







 本文详细介绍了 Spark Streaming 的核心概念、实时 WordCount 应用实例及常见错误,展示了如何整合 Flume、Kafka 和 Spark Streaming 进行数据处理,并探讨了转向 Structured Streaming 的必要性。
本文详细介绍了 Spark Streaming 的核心概念、实时 WordCount 应用实例及常见错误,展示了如何整合 Flume、Kafka 和 Spark Streaming 进行数据处理,并探讨了转向 Structured Streaming 的必要性。
文章目录
1. spark streaming概述
spark流式处理的框架,能够很容易的构建容错、高可用的计算模型
- 特点
- 1.易用 2. 容错 3. 集成
2. DStream概述
-
Discretized(离散的) Stream是Spark Streaming的基础抽象 -
代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据, 对数据的操作也是按照RDD为单位来进行的 -
DStream上的原语与RDD的类似,分为
Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。 -
特殊的Transformations
-
UpdateStateByKeyOperation- UpdateStateByKey原语用于记录历史记录,Word Count示例中就用到了该特性。若不用UpdateStateByKey来更新状态,那么每次数据进来后分析完成后,结果输出后将不在保存
-
TransformOperation- Transform原语允许DStream上执行任意的RDD-to-RDD函数。通过该函数可以方便的扩展Spark API。此外,MLlib(机器学习)以及Graphx也是通过本函数来进行结合的。
-
WindowOperations- Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Streaming的允许状态
-
-
Output Operations on DStreams
Output Operations可以将DStream的数据输出到外部的数据库或文件系统,当某个Output Operations原语被调用时(与RDD的Action相同),streaming程序才会开始真正的计算过程。- print()
- saveAsTextFiles(prefix, [suffix])
- saveAsObjectFiles(prefix, [suffix])
- saveAsHadoopFiles(prefix, [suffix])
- foreachRDD(func)
3. spark streaming 实现实时WordCount统计
3.1. 架构图
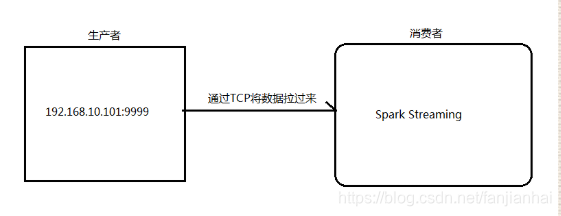
- 安装并启动生成者
-
首先在一台Linux(ip:mini1)上用YUM安装nc工具
yum install -y nc -
启动一个服务端并监听9999端口
c -lk 9999
-
3.2. 源代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingTCP {
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = runningCount.getOrElse(0) + newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
// 初始化环境
val conf = new SparkConf().setAppName("spark stream").setMaster("local[2]")
// 5 秒处理一次
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("hdfs://192.168.1.28:9000/local_checkpoint")
// 注册一个监听ip和port, 用来收集数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.1.27", 9999)
// 对数据进行处理
val words: DStream[String] = lines.flatMap(_.split(" "))
val result: DStream[(String, Int)] = words.map((_, 1)).updateStateByKey(updateFunction _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
3.3. Window模式源代码(应用场景,每小时的流量统计,不累加)
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingTCP {
def main(args: Array[String]): Unit = {
// 初始化环境
val conf = new SparkConf().setAppName("spark stream").setMaster("local[2]")
// 5 秒处理一次
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("hdfs://192.168.1.28:9000/local_checkpoint")
// 注册一个监听ip和port, 用来收集数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.1.27", 9999)
// 对数据进行处理
val words: DStream[String] = lines.flatMap(_.split(" "))
val result: DStream[(String, Int)] = words.map((_,1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(6), Seconds(6))
result.print()
ssc.start()
ssc.awaitTermination()
}
}
3.4. 依赖jar包容易犯的错;版本问题和scope问题
4. Flume+Kafka+Spark Streaming 整合
4.1. 从Flume中拉取数据到Spark Stream进行处理
-
Flume配置
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /var/log/flume a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.hostname = mini2 a1.sinks.k1.port = 9999 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
spark streaming代码
package cn.xiaofan.spark import java.net.InetSocketAddress import akka.japi.Option.Some import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{HashPartitioner, SparkConf} /** * 从Flume中拉取数据到Spark Stream进行处理 */ object FlumeWordCount { val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => { iter.flatMap{ case (x,y,z) => Some(y.sum + z.getOrElse(0)).map(v => (x,v))} } def main(args: Array[String]): Unit = { // local的线程数量一定超过两个 val conf = new SparkConf().setAppName("FlumeWordCount").setMaster("local[2]") // 5秒处理一次 val ssc = new StreamingContext(conf, Seconds(5)) // 回滚点设置在本地 ssc.checkpoint("./") // 设置flume的多台地址 val addresses: Seq[InetSocketAddress] = Seq(new InetSocketAddress("mini2", 9999)) // 从flume中拉取数据 val flumeStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc, addresses, StorageLevel.MEMORY_AND_DISK) // 将flume数据中的body部分array转换为string,进行rdd val result: DStream[(String, Int)] = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_, 1)).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true) result.print() ssc.start() ssc.awaitTermination() } }注意: 需要把对应版本的spark-streaming-flume-sink_2.11-2.1.0.jar包,拷贝到flume的lib目录下
4.2. FlumeSpark采集数据到Spark Stream进行处理
-
Flume配置
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /var/log/flume a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = 192.168.116.1 a1.sinks.k1.port = 9999 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
spark streaming代码
package cn.xiaofan.spark import akka.japi.Option.Some import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{HashPartitioner, SparkConf} /** * Flume把数据采集到Spark Stream进行处理 */ object FlumeWordCount { val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => { iter.flatMap{ case (x,y,z) => Some(y.sum + z.getOrElse(0)).map(v => (x,v))} } def main(args: Array[String]): Unit = { // local的线程数量一定超过两个 val conf = new SparkConf().setAppName("FlumeWordCount").setMaster("local[2]") // 5秒处理一次 val ssc = new StreamingContext(conf, Seconds(5)) // 回滚点设置在本地 ssc.checkpoint("./") // Flume把采集到的数据推过来 val flumeStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc,"192.168.116.1", 9999) // 将flume数据中的body部分array转换为string,进行rdd val result: DStream[(String, Int)] = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_, 1)).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true) result.print() ssc.start() ssc.awaitTermination() } }
4.3. Spark Stream处理Kafka中的数据
```
package cn.xiaofan.spark
import akka.japi.Option.Some
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf}
/**
* 从Kafka中读取数据进行单词统计
*/
object KafkaWordCount {
val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.flatMap{ case (x,y,z) => Some(y.sum + z.getOrElse(0)).map(v => (x,v))}
}
def main(args: Array[String]): Unit = {
// local的线程数量一定超过两个
val conf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
// 5秒处理一次
val ssc = new StreamingContext(conf, Seconds(5))
// 回滚点设置在本地
ssc.checkpoint("./")
// 构建数组的另一种方式
val Array(zkQuorum, groupId, topics, numThreads) = Array("mini1:2181,mini2:2181,mini3:2181","g1","kafka_word_count","2")
val topicMap: Map[String, Int] = topics.split(",").map((_,numThreads.toInt)).toMap
val lines: DStream[String] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2)
val result: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
```


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









