




书生浦语大模型实战营第四期-InternLM + LlamaIndex RAG 实践
- 教程链接:https://github.com/InternLM/Tutorial/tree/camp4/docs/L1/LlamaIndex
- 任务链接:https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/LlamaIndex/task.md
- 提交链接:https://aicarrier.feishu.cn/share/base/form/shrcnUqshYPt7MdtYRTRpkiOFJd
任务说明
基础任务 (完成此任务即完成闯关)
-
任务要求1(必做,参考readme_api.md):基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力,截图保存。注意:写博客提交作业时切记不要泄漏自己 api_key!
-
任务要求2(可选,参考readme.md):基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 InternLM2-Chat-1.8B 模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力,截图保存。
-
任务要求3(优秀学员必做) :将 Streamlit+LlamaIndex+浦语API的 Space 部署到 Hugging Face。
闯关材料提交 (完成任务并且提交材料时为闯关成功)
- 请将作业发布到知乎、优快云 等任一社交媒体,将作业链接提交到以下问卷,助教老师批改后将获得 100 算力点奖励!!!
- 提交地址:https://aicarrier.feishu.cn/share/base/form/shrcnUqshYPt7MdtYRTRpkiOFJd
任务1
环境创建:
conda create -n llamaindex python=3.10
pip install einops==0.7.0 protobuf==5.26.1
pip install llama-index==0.11.20
pip install llama-index-llms-replicate==0.3.0
pip install llama-index-llms-openai-like==0.2.0
pip install llama-index-embeddings-huggingface==0.3.1
pip install llama-index-embeddings-instructor==0.2.1
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121
然后新建脚本test_internlm.py,贴入下述内容:
from openai import OpenAI
from api import api_key
base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
# api_key = "sk-请填写准确的 token!"
model="internlm2.5-latest"
# base_url = "https://api.siliconflow.cn/v1"
# api_key = "sk-请填写准确的 token!"
# model="internlm/internlm2_5-7b-chat"
client = OpenAI(
api_key=api_key ,
base_url=base_url,
)
chat_rsp = client.chat.completions.create(
model=model,
messages=[{
"role": "user", "content": "xtuner是什么?"}],
)
for choice in chat_rsp.choices:
print(choice.message.content)
其中需要新建一个api.py放入申请好的token哈,运行一下:

显然不是我们想要的结果~
然后测试下RAG的结果,准备好数据和知识库后,新建脚本test_internlm_rag,贴入下述内容:
import os
os.environ['NLTK_DATA'] = 'nltk_data'
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
from api import api_key
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
# api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#初始化llm
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")
print(response)
python运行一下,效果如下:
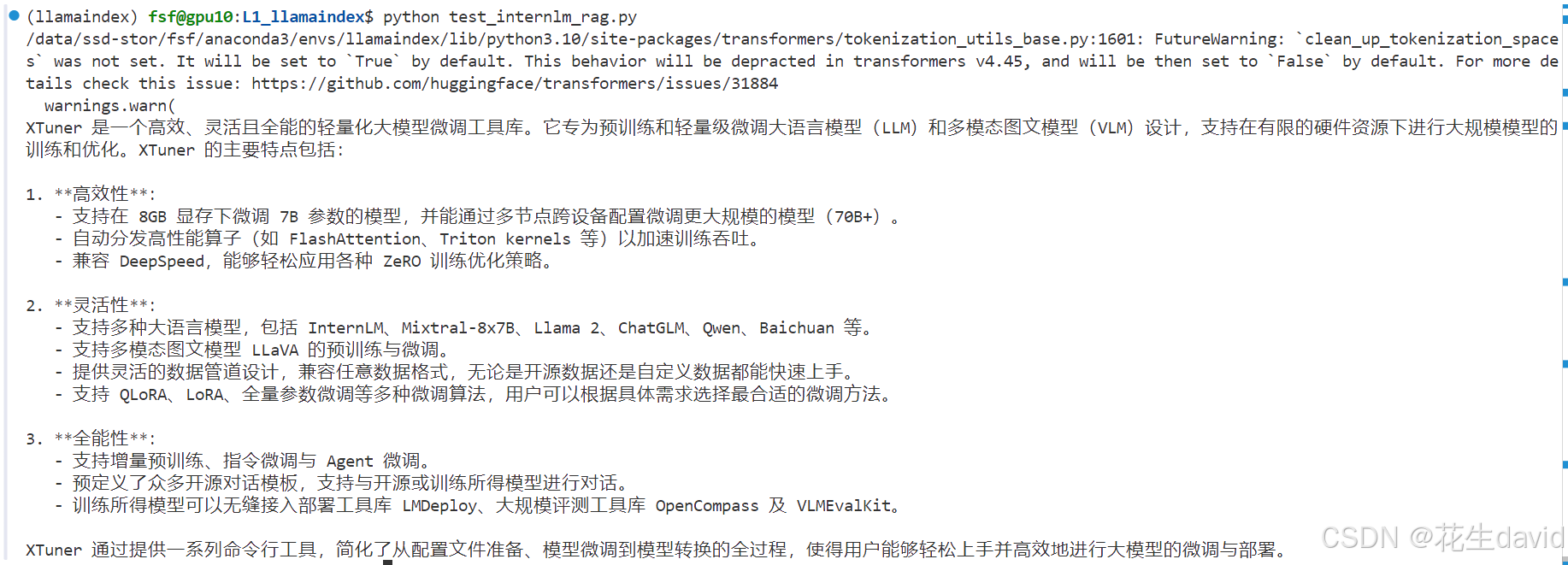
可以看到模型准备回答了我们想要的结果
然后换个问题问下:
未使用RAG之前:

使用RAG之后:

对比前后结果,RAG之后的模型输出了领域知识结果,不错~
任务2
教程的原理图放这里镇着,没事儿看看,更多内容可以看上面的教程链接
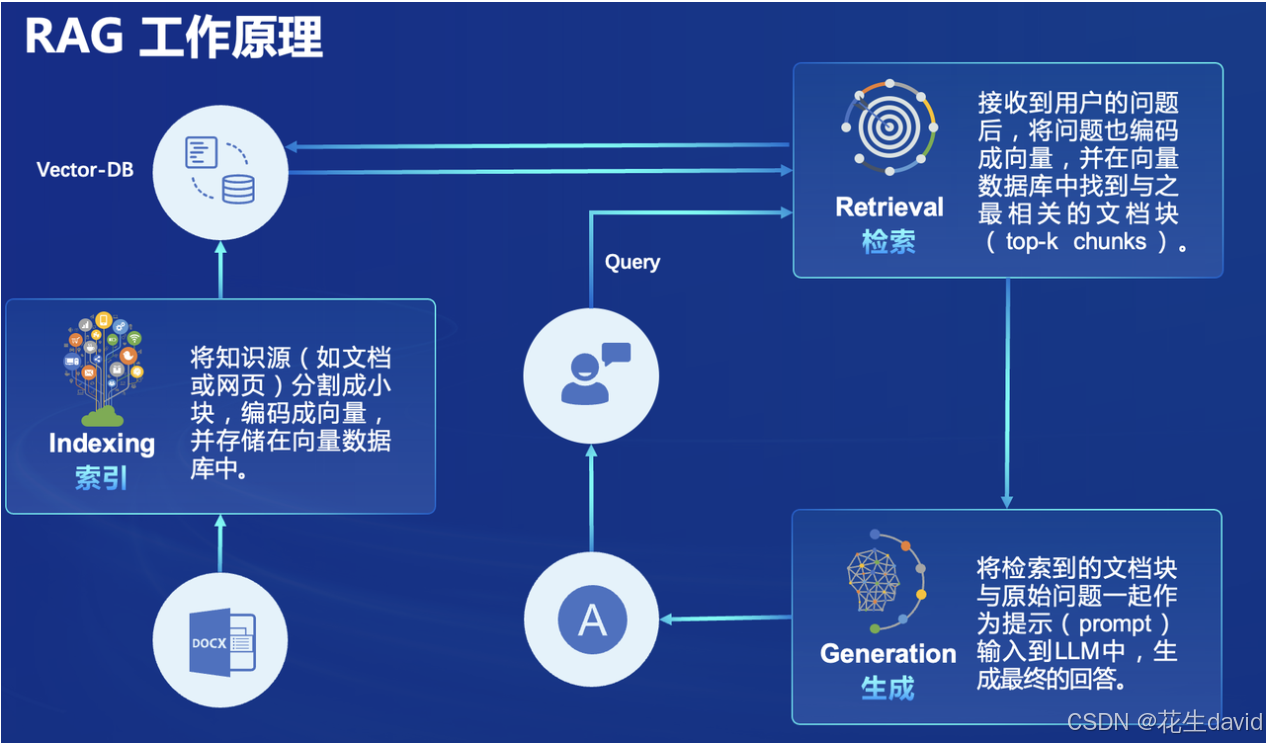
教程案例测试
基本环境配一下,缺啥pip啥:
conda create -n llamaindex python=3.10
conda activate llamaindex
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install einops==0.7.0 protobuf==5.26.1
pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0
pip install llama-index-embeddings-huggingface==0.2.0 llama-index-embeddings-instructor==0.1.3
准备一个词向量模型,这个随意就好,用教程推荐的就行,后续可以换更好的,下载脚本:
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir ../models/sentence-t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









