



首先 需要用到 三个模块
import requests #请求模块
from bs4 import BeautifulSoup #过滤模块,用来提取,筛选
import openpyxl #用来生成excel模块
#get_html获取我们的网页内容,我们使用Google Chrome
#设置图文件
def get_html(url):
headers = {
'User-Agent':
}
html = requests.get(url, headers=headers)
User-Agent后面的内容在谷歌浏览器里搜chrome://version,把用户代理的内容复制在后面
#soup用来过滤,提取,筛选
soup = BeautifulSoup(html.text,'lxml')
movie_list = []
#这里用来找到网页里面所有的div标签,填写条件叫做info
for movie in soup.find_all('div',class_='info'):
name = movie.find('span',class_='title').text
info = movie.find('div',class_='bd').p.text.strip().split('\n')
#获取导演信息,去除空格
director_star = info[0].strip().split('\xa0\xa0\xa0 ')
director = director_star[0][3:]
star = director_star[1][3:] if len(director_star) > 1 else '没有演员信息'
这里我们按f12,打开开发者工具,在元素里Ctrl F 进行搜索info,发现所有的信息都在一个info的盒子里面,所以我们提取类名为info的盒子,获取类名为title的一个span标签的文本。其他的信息都在一个叫做BD的一个盒子里。在这个盒子里第一行是我们的导演,加上主演,第二行是国家以及年份等
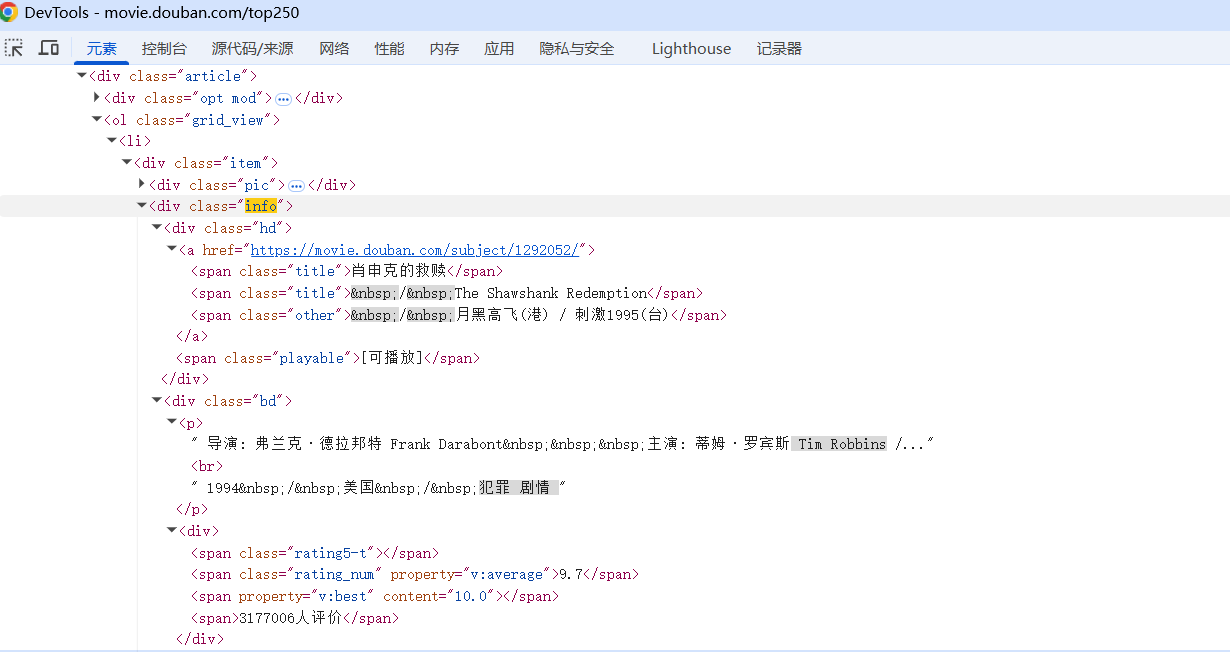
#获取电影类型,国家地区
other_info = info[1].strip().split('/')#斜杠进行分割
address = other_info[1].strip()
style = other_info[2].strip()
score = movie.find('span',class_='rating_num').text#评分信息,类名为reting_num
movie_list.append([name,director,star,style,address,score])#把所有信息整合成一个类表
return movie_list
#保存我们的数据
def save(movie_info):
wb = openpyxl.Workbook()#新建工作簿
sheet = wb.active#获取工作表
sheet.append((['电影名','导演','主演','类型','地区','评分']))#添加标题
for movie in movie_info:#将电影数据逐个添加进来
sheet.append(movie)
wb.save('豆瓣2521.xlsx')#保存文件
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start={}&filter='
#列表用来保存电影页面信息
movie_info= []
for i in range(0,226,25):
#把得到的电影信息追加到列表里
movie_info.extend(get_html(url.format(i)))
#保存电影信息
save(movie_info)
我们在豆瓣页面点第二页,第三页发现起始页以25往上加,最后一页为225,写一个循环,从0到225,每次都加25,最后保存运行,在文件路径找到excel
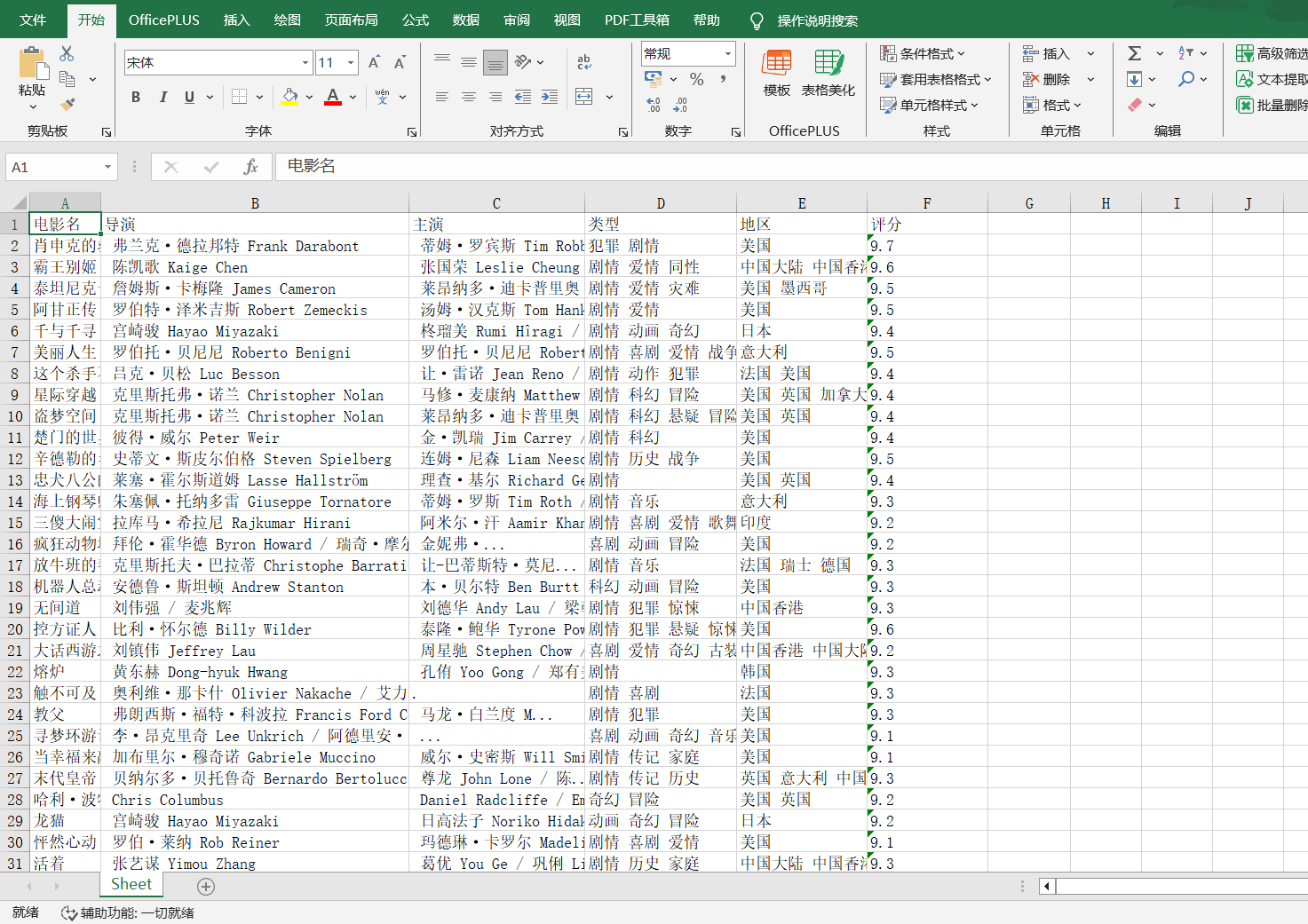

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









