







 本文详细解读了Diffusion-Convolutional Neural Networks论文,重点介绍了hop概念,它扩展了节点的关注范围,不再局限于直接邻居。论文探讨了节点分类、图分类和边分类三种任务,并详细阐述了网络结构、输入输出以及参数设置。在节点分类中,-hop矩阵P*是关键,通过与特征矩阵X相乘得到中间表示。图分类则通过对所有节点的平均得到Z。边分类引入了连接矩阵Bt,用于处理边的特征。
本文详细解读了Diffusion-Convolutional Neural Networks论文,重点介绍了hop概念,它扩展了节点的关注范围,不再局限于直接邻居。论文探讨了节点分类、图分类和边分类三种任务,并详细阐述了网络结构、输入输出以及参数设置。在节点分类中,-hop矩阵P*是关键,通过与特征矩阵X相乘得到中间表示。图分类则通过对所有节点的平均得到Z。边分类引入了连接矩阵Bt,用于处理边的特征。
Diffusion-Convolutional Neural Networks
论文链接
总结
这篇文章提出了hop的概念,使一个节点能够关注到与它距离更远的节点,而不仅限于一阶邻居。
网络介绍
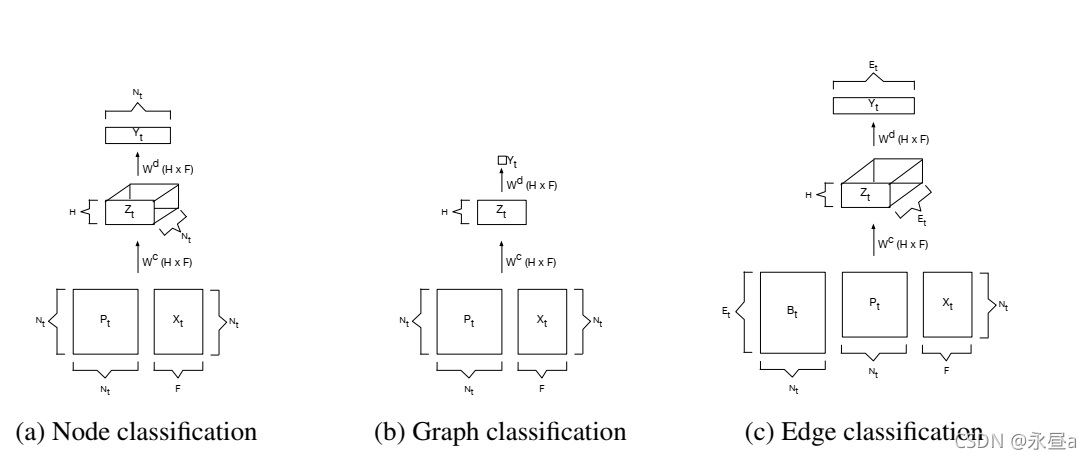
这篇论文主要针对三种分类任务。
1. 节点分类
1.1 输入
输入为两个矩阵,分别为矩阵P和矩阵X。X为图的特征矩阵(N*F),P则是多个类似于邻接矩阵的矩阵叠加而成,也是本篇论文的核心‘hop’。
对于网络而言,hop是一个超参,当hop=1时,则P就代表着邻接矩阵;当hop=2时,P代表着邻接矩阵加上与该节点距离为2的节点的邻接矩阵(即设该节点为i,要到达节点j,最短路径为i->k->j)。hop更高时以此类推。
而图中P,实际上在论文中用P*来表示,是是将所有的邻接矩阵堆叠到一起的产物(即hop=2即将1阶邻居的邻接矩阵和2阶邻居的邻接矩阵concat到一起)。如此的话,P*就是一个N*H*N的矩阵。
所以,输入的P*和X相乘后,就得到了N*H*F的矩阵。
1.2 参数
这里的参数有 W c 和 W d W^c和W^d Wc和Wd两个,是H*F的矩阵,与输入进行点乘(element-wise)。
1.3 输出
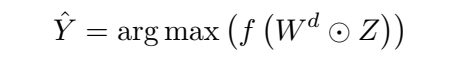
1.3.1 问题
论文中提到由Z到Y的部分应该是一个全连接,而
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3415
3415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









