







 超级会员免费看
超级会员免费看
# 随机数据
生成随机数据样本。
输入
*无
输出
*数据: 随机生成的数据
随机数据 组件允许创建随机数据集,其中变量对应于选定的分布。用户可以指定行数(样本数)以及每个分布的变量数量。该组件使用 Scipy 的 stats 模块中的分布。
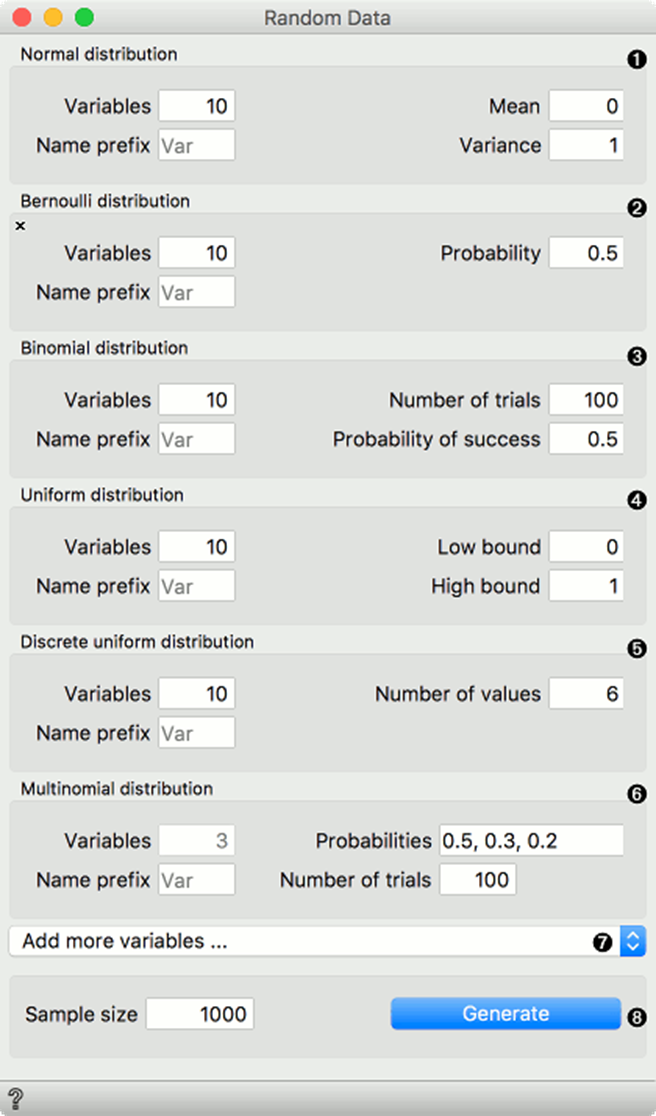
1.正态分布: 一个正态连续随机变量。设置变量数量、均值和方差。
2.伯努利分布: 一个伯努利离散随机变量。设置变量数量和概率质量函数(即成功概率 p)。
3.二项分布: 一个二项离散随机变量。设置变量数量、试验次数 (n) 和成功概率 §。
4.**均匀分布 (连续) **: 一个连续均匀随机变量。设置变量数量以及分布的下界和上界。
5.**离散均匀分布 : 一个离散均匀随机变量。设置变量数量和每个变量的取值数量(或范围)。
6.多项分布: 一个多项随机变量。设置概率和试验次数 (n)。概率

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











