




CH3 Linear models for regression回归的线性模型
3.1线性基函数模型
-
回归的最简单模型
y(x,w)=w0+w1x1+…+wDxD y(\boldsymbol x,\boldsymbol w)=w_0+w_1x_1+\ldots+w_Dx_D y(x,w)=w0+w1x1+…+wDxD
其中x=(x1,…,xD)T\boldsymbol x=(x_1,\ldots,x_D)^Tx=(x1,…,xD)T. -
扩展模型
将输入变量的固定的非线性函数进行线性组合
形式为
y(x,w)=w0+∑j=1M−1wjϕj(x) y(\boldsymbol x,\boldsymbol w)=w_0+\sum_{j=1}^{M-1}w_j\phi_j(\boldsymbol x) y(x,w)=w0+j=1∑M−1wjϕj(x)
其中ϕj(x)\phi_j(\boldsymbol x)ϕj(x)称为基函数(basis function)。此模型中的参数总数为MMM。参数w0w_0w0称为偏置参数(bias parameter)定义ϕ0(x)=1\phi_0(\boldsymbol x)=1ϕ0(x)=1,此时
y(x,w)=∑j=0M−1wjϕj(x)=wTϕ(x) y(\boldsymbol x,\boldsymbol w)=\sum_{j=0}^{M-1}w_j\phi_j(\boldsymbol x)=\boldsymbol w^T\phi(\boldsymbol x) y(x,w)=j=0∑M−1wjϕj(x)=wTϕ(x)
其中w=(w0,…,wM−1)T\boldsymbol w=(w_0,\ldots,w_M-1)^Tw=(w0,…,wM−1)T且ϕ=(ϕ0,…,ϕM−1)T\phi=(\phi_0,\ldots,\phi_{M-1})^Tϕ=(ϕ0,…,ϕM−1)T。基函数{ ϕj(x)\phi_j(\boldsymbol x)ϕj(x)}可以表示原始变量x\boldsymbol xx的特征(预处理或特征抽取后的) -
基函数选择
多项式拟合,基函数:ϕj(x)=xj\phi_j(x)=x^jϕj(x)=xj。局限性:是输入变量的全局函数,因此对于输入空间一个区域的改变将会影响所有其他的区域。解决:把输入空间切分成若干个区域,对每个区域用不同的多项式函数拟合。----样条函数(spline function)???
高斯基函数,ϕj(x)=exp{ −(x−μj)22s2}\phi_j(x)=\exp\left\{-\frac{(x-\mu_j)^2}{2s^2}\right\}ϕj(x)=exp{ −2s2(x−μj)2},其中μj\mu_jμj控制了基函数在输入空间中的位置,参数sss控制了基函数的空间大小。未必是一个概率表达式。归一化系数不重要,因为有调节参数wjw_jwj
sigmoid基函数,ϕj(x)=σ(x−μjs)\phi_j(x)=\sigma(\frac{x-\mu_j}{s})ϕj(x)=σ(sx−μj),其中σ(a)=11+exp(−a)\sigma(a)=\frac{1}{1+\exp(-a)}σ(a)=1+exp(−a)1是logistic sigmoid函数。等价地可以使用tanh函数,和logistic sigmoid函数的关系为tanh(aaa)=2σ(2a)−12\sigma(2a)-12σ(2a)−1
傅里叶基函数,用正弦函数展开。
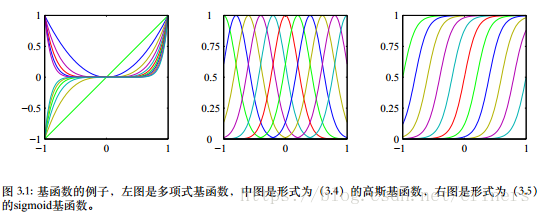
3.1.1最大似然与最小平方
假设目标变量ttt由确定的函数y(x,w)y(\boldsymbol x,\boldsymbol w)y(x,w)给出,附加高斯噪声,即
t=y(x,w)+ϵ t=y(\boldsymbol x,\boldsymbol w)+\epsilon t=y(x,w)+ϵ
其中ϵ\epsilonϵ是一个零均值的高斯随机变量,精度为β\betaβ,有
p(t∣x,w,β)=N(t∣y(x,w),β−1) p(t|\boldsymbol x,\boldsymbol w,\beta)=\mathcal N(t|y(\boldsymbol x,\boldsymbol w),\beta^{-1}) p(t∣x,w,β)=N(t∣y(x,w),β−1)
ch1中,假设一个平方损失函数,对于x\boldsymbol xx的一个新值,最优预测由目标变量的条件均值给出,在高斯条件分布的情况下,条件均值可写成
E[t∣x]=∫tp(t∣x)dt=y(x,w) \mathbb E[t|\boldsymbol x]=\int tp(t|\boldsymbol x)dt=y(\boldsymbol x,\boldsymbol w) E[t∣x]=∫tp(t∣x)dt=y(x,w)
高斯噪声的假设表明,给定x\boldsymbol xx的条件下,ttt的条件分布是单峰的,可以扩展到条件高斯分布的混合,描述多峰的条件分布
考虑一个输入数据集X={
x1,…,xN}\boldsymbol X=\left\{\boldsymbol x_1,\ldots,\boldsymbol x_N\right\}X={
x1,…,xN},对应的的目标值为t1,…,tNt_1,\ldots,t_Nt1,…,tN,将目标向量{
tnt_ntn}组成一个列向量,记作t\boldsymbol tt。假设数据点独立,得到似然函数为
p(t∣X,w,β)=∏n=1NN(tn∣wTϕ(xn),β−1) p(\boldsymbol t|\boldsymbol X,\boldsymbol w,\beta)=\prod_{n=1}^N\mathcal N(t_n|\boldsymbol w^T\phi(\boldsymbol x_n),\beta^{-1}) p(t∣X,w,β)=n=1∏NN(tn∣wTϕ(xn),β−1)
取对数似然函数,有(不显式地写出x\boldsymbol xx)
lnp(t∣w,β)=∑n=1NlnN(tn∣wTϕ(xn),β−1)=N2lnβ−N2ln(2π)−βED(w) \ln p(\boldsymbol t|\boldsymbol w,\beta)=\sum_{n=1}^N\ln \mathcal N(t_n|\boldsymbol w^T\phi(\boldsymbol x_n),\beta^{-1})=\frac{N}{2}\ln\beta-\frac{N}{2}\ln(2\pi)-\beta E_D(\boldsymbol w) lnp(t∣w,β)=n=1∑NlnN(tn∣wTϕ(xn),β−1)=2Nlnβ−2Nln(2π)−βED(w)
其中平方和误差函数为
ED(w)=12∑n=1N{
tn−wTϕ(xn)}2 E_D(\boldsymbol w)=\frac{1}{2}\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(\boldsymbol x_n)\right\}^2 ED(w)=21n=1∑N{
tn−wTϕ(xn)}2
对数似然函数的梯度为
∇lnp(t∣w,β)=β∑n=1N{
tn−wTϕ(xn)}ϕ(xn)T \nabla \ln p(\boldsymbol t|\boldsymbol w,\beta)=\beta\sum_{n=1}^N\left\{t_n-\boldsymbol w^T\phi(\boldsymbol x_n)\right\}\phi(\boldsymbol x_n)^T ∇lnp(t∣w,β)=βn=1∑N{
tn−wTϕ(xn)}ϕ(xn)T
令梯度为0,得
0=∑n=1Ntnϕ(xn)T−wT(∑n=1Nϕ(xn)ϕ(xn)T) 0=\sum_{n=1}^Nt_n\phi(\boldsymbol x_n)^T-\boldsymbol w^T(\sum_{n=1}^N\phi(\boldsymbol x_n)\phi(\boldsymbol x_n)^T) 0=n=1∑Ntnϕ(xn)T−wT(n=1∑Nϕ(xn)ϕ(xn)T)
求解w\boldsymbol ww,有
wML=(ΦTΦ)−1ΦTt \boldsymbol w_{ML}=(\boldsymbol \Phi^T\boldsymbol \Phi)^{-1}\boldsymbol \Phi^T\boldsymbol t wML=(ΦTΦ)−1ΦTt
称为最小平方问题的规范方程(normal equation),Φ\boldsymbol \PhiΦ是N×MN\times MN×M的矩阵,称为设计矩阵(design matrix),元素为Φnj=ϕj(xn)\Phi_{nj}=\phi_j(\boldsymbol x_n)Φnj=ϕj(xn),即
Φ=(ϕ0(x1)ϕ1(x1)⋯ϕM−1(x1)ϕ0(x2)ϕ1(x2)⋯ϕM−1(x2)⋮⋮⋱⋮ϕ0(xN)ϕ1(xN)⋯ϕM−1(xN)) \boldsymbol \Phi=\begin{pmatrix}\phi_0(\boldsymbol x_1) &\phi_1(\boldsymbol x_1) & \cdots & \phi_{M-1}(\boldsymbol x_1) \\ \phi_0(\boldsymbol x_2) & \phi_1(\boldsymbol x_2) &\cdots & \phi_{M-1}(\boldsymbol x_2) \\ \vdots &\vdots&\ddots&\vdots \\\phi_0(\boldsymbol x_N)&\phi_1(\boldsymbol x_N)&\cdots&\phi_{M-1}(\boldsymbol x_N)\end{pmatrix} Φ=⎝⎜⎜⎜⎛ϕ0(x1)ϕ0(x2)⋮ϕ0(xN)ϕ1(x1)ϕ1(x2)⋮ϕ1(xN)⋯⋯⋱⋯ϕM−1(x1)ϕM−1(x2)⋮ϕM−1(xN)⎠⎟⎟⎟⎞
量
Φ†≡(ΦTΦ)−1ΦT \boldsymbol \Phi^\dagger\equiv (\boldsymbol \Phi^T\boldsymbol \Phi)^{-1}\boldsymbol \Phi^T Φ†≡(ΦTΦ)−1ΦT
成为矩阵的Moore-Penrose伪逆矩阵(pseudo-inverse matrix),可被看成逆矩阵的概念对于非方阵的矩阵的推广
显式地写出偏置参数,误差函数为
ED(w)=12∑n=1N{
tn−w0−∑j=1M−1wjϕj(xn)}2 E_D(\boldsymbol w)=\frac{1}{2}\sum_{n=1}^N\left\{t_n-w_0-\sum_{j=1}^{M-1}w_j\phi_j(x_n)\right\}^2 ED(w)=21n=1∑N{
tn−w0−j=1∑M−1wjϕj(xn)}2
令关于wow_owo的导数等于零,解出wow_owo,得
w0=tˉ−∑j=1M−1wjϕˉj w_0=\bar t-\sum_{j=1}^{M-1}w_j\bar \phi_j w0=tˉ−j=1∑M−1wjϕˉj
其中定义了
tˉ=1N∑n=1Ntn \bar t=\frac{1}{N}\sum_{n=1}^Nt_n tˉ=N1n=1∑Ntn
ϕˉj=1N∑n=1Nϕj(xn) \bar \phi_j=\frac{1}{N}\sum_{n=1}^N\phi_j(\boldsymbol x_n) ϕˉj=N1n=1∑Nϕj(xn)
因此偏置w0w_0w0补偿了目标值的平均值(在训练集上的)与基函数的值的平均值的加权求和之间的差。
关于噪声精度参数β\betaβ最大化似然函数
1βML=1N∑n=1N{
tn−wMLTϕ(xn)}2 \frac{1}{\beta_{ML}}=\frac{1}{N}\sum_{n=1}^N\left\{t_n-w_{ML}^T\phi(x_n)\right\}^2 βML1=N1n=1∑N{
tn−wMLTϕ(xn)}2
因此噪声精度的倒数由目标值在回归函数周围的残留方差给出
3.1.2最小平方的几何描述
考虑一个NNN维空间,坐标轴由tnt_ntn给出,t=(t1,…,tN)\boldsymbol t=(t_1,\ldots,t_N)t=(t1,…,tN)是空间中的一个向量 ,每个在NNN个数据点处估计的基函数ϕj(xn)\phi_j(\boldsymbol x_n)ϕj(xn)可以表示为这个空间中的一个向量,记作φj\varphi_jφj,对应于Φ\PhiΦ的第iii列
如果基函数的数量MMM小于数据点的数量NNN,那么MMM个向量φj\varphi_jφj将会张成一个MMM维的子空间SSS。
定义y\boldsymbol yy是一个NNN维向量,第nnn个元素为y(xn,w)y(\boldsymbol x_n,\boldsymbol w)y(xn,w),由于y\boldsymbol yy是向量φj\varphi_j
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









