




 超级会员免费看
超级会员免费看
 本文深入探讨了Spark的RDD依赖,包括窄依赖和宽依赖,以及如何区分它们。详细介绍了Spark的DAG和Stage划分,以及Shuffle过程。此外,还涵盖了Job调度流程,Spark的基本概念如并行度,并提供了算子背后的逻辑分析。
本文深入探讨了Spark的RDD依赖,包括窄依赖和宽依赖,以及如何区分它们。详细介绍了Spark的DAG和Stage划分,以及Shuffle过程。此外,还涵盖了Job调度流程,Spark的基本概念如并行度,并提供了算子背后的逻辑分析。
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
以词频统计WordCount程序为例,Job执行是DAG图:
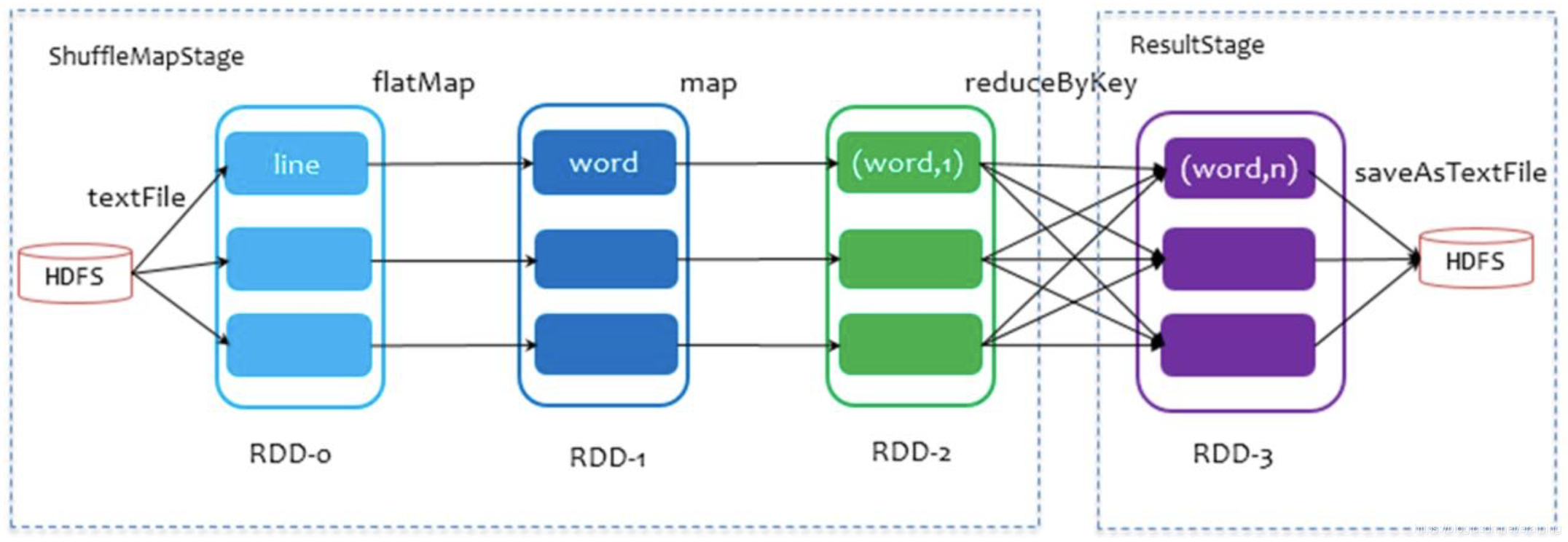
1. RDD 依赖
RDD 的容错机制是通过将 RDD 间转移操作构建成有向无环图来实现的。从抽象的角度看, RDD 间存在着血统继承关系,其本质上是 RDD之间的依赖(Dependency)关系。
从图的角度看,RDD 为节点,在一次转换操作中,创建得到的新 RDD 称为子 RDD,同时会产生新的边,即依赖关系,子 RDD 依赖向上依赖的 RDD 便是父 RDD,可能会存在多个父 RDD。 可以将这种依赖关系进一步分为两类,分别是

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4079
4079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











