




作业3
有一份会员数据集(data.xlsx),第一列代表会员的姓名,第二列是性别,第三列是年龄,第四列是体重,第五列是身高。
数据集存在以下问题:
-
列名为数字,不能知道具体的数据的含义
-
数据的完整性检查:
- 发现有一整行记录为空值
- 姓名为gloria的体重数据缺失
-
数据的全面性检查
- 发现身高的度量单位不统一,有米的,也有厘米的
- 姓名的首字母大小写不统一,有大写,也有小写的
-
数据的合法性检查:
- 姓名字段存在非ASCII码字符、存在?号非法字符、出现空值
- 性别字段存在空格
- 年龄字段存在负数
-
数据的唯一性检查
- 姓名为Emma的记录存在重复。
请编写Python程序对数据集进行清洗,输出清洗之后的数据。
思路
-
列名修改
列名为数字,不知道具体的数据含义:使用
data.columns属性为数据框添加具体的列名,第一到第五列分别代表姓名、性别、年龄、体重、身高。 -
数据完整性检查
由于
dropna()会删除包含NaN的行,所以要先将体重缺失项填充后再进行删除,否则会导致该行数据的丢失。- 姓名为gloria的体重数据缺失:先查找姓名为 ‘gloria’ 的行,使用
data.loc[data['姓名'] == 'gloria', '体重'] = mean_weight将 “gloria” 的体重数据填充为体重列的均值 - 发现一整行记录为空值:使用
data.dropna()删除。需要在原地修改,使用inplace=True参数删除包含NaN值的行,并修改原始的data。
- 姓名为gloria的体重数据缺失:先查找姓名为 ‘gloria’ 的行,使用
-
数据全面性检查
- 身高的度量单位不统一:此处将所有身高数据统一转化为厘米。
- 首先检查身高数据:由于以米为单位的数据小于 3 ,可使用
is_meter = data['身高'] < 3识别出以米为单位的数据。 - 转换单位: 使用
data.loc[is_meter, '身高'] = data.loc[is_meter, '身高'] * 100将以米为单位的数据转换为厘米,再将转换后的数据更新到数据框中。
- 首先检查身高数据:由于以米为单位的数据小于 3 ,可使用
- 姓名的首字母大小写不统一:使用
data['姓名'].str.title()将所有姓名的首字母转换为大写,其他字母转换为小写。
- 身高的度量单位不统一:此处将所有身高数据统一转化为厘米。
-
数据合法性检查
- 删除非 ASCII 码字符和非法字符:可使用正则表达式删除所有非字母字符
data['姓名'] = data['姓名'].apply(lambda x: re.sub(r'[^a-zA-Z]', '', str(x)))- 处理空值: 使用
data.dropna(subset=['姓名'])删除包含空值的行。 - 去除性别字段中的前后空格:使用
data['性别'].str.strip()去除性别字段中的前后空格。 - 处理年龄字段中的负数: 使用
data.loc[data['年龄'] < 0, '年龄'] = mean_age将年龄字段中的负数替换为年龄的均值。首先计算年龄的均值(排除负数),然后将负数替换为均值。
-
数据唯一性检查
- 唯一性检查: 使用
data.duplicated()检查数据集中是否存在重复记录,并打印重复记录的数量。 - 用
data.drop_duplicates(subset=['姓名'], keep='first')删除姓名为 “Emma” 的重复记录,只保留第一次出现的记录。
- 唯一性检查: 使用
改进

打印结果后发现无法正确查找姓名为’gloria’的行,原因是查找时姓名格式还没统一,可能包含额外的空格或大小写不一致,可在在查找时忽略大小写和空格。更新后的代码如下:
# 查找姓名为 'gloria' 的行(忽略大小写和空格)
gloria_row = data[data['姓名'].str.strip().str.lower() == 'gloria']
print("\n姓名为 'gloria' 的行:")
print(gloria_row)
# 填充 'gloria' 的体重数据
mean_weight = data['体重'].mean()
data.loc[data['姓名'].str.strip().str.lower() == 'gloria', '体重'] = mean_weight
# 打印填充后的数据
print("\n填充 'gloria' 的体重数据后:")
print(data[data['姓名'].str.strip().str.lower() == 'gloria'])
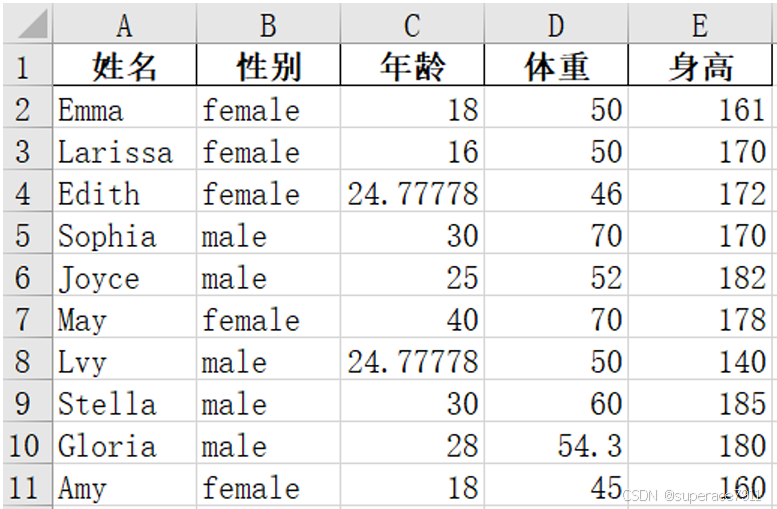
结果
最终输出结果:


















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









