




 本文深入探讨了MySQL性能优化的关键方面,包括操作系统与硬件的选择、内存与磁盘资源的平衡、固态存储的应用、以及针对备库和RAID的硬件配置策略。此外,还介绍了网络配置的重要性、操作系统及文件系统的选取原则。
本文深入探讨了MySQL性能优化的关键方面,包括操作系统与硬件的选择、内存与磁盘资源的平衡、固态存储的应用、以及针对备库和RAID的硬件配置策略。此外,还介绍了网络配置的重要性、操作系统及文件系统的选取原则。
操作系统和硬件优化:
1.是什么限制了mysql的性能
最常见的2个瓶颈 CPU 和 IO。
当数据可以放在内存中或者可以从磁盘中以足以快的速度读取时,CPU可能出现瓶颈。另一方面是IO瓶颈,一般发生在工作所需的数据
远远超过有效内存的容量的时候。
某一方面的缺陷常常会将压力施加到另外一个子系统。当找到一个限制系统性能因素时,要问自己 '是这个部分本身问题,还是系统中其他不合理
的压力转移到这里所致的'。
2.mysql 如何选择 CPU
当遇到cpu密集型的工作时,mysql通常可以从更快的cpu中获益,但这不是绝对的,因为还依赖负载情况和cpu数量。更古老的mysql版本在多cpu
上有扩展问题,即使新版本也不能对单个查询并发利用多个cpu。因此,cpu速度限制了每个cpu密集型查询的响应时间。
现在的服务器一般有多个插槽,每个插槽上都可以插一个有多个核心的cpu(有独立的执行单元),并且每个核心可能有多个'硬件线程'(超线程)。
实际上单个执行单元并不是真的可以在同一时间运行2个进程。
mysql复制也能在高速cpu下工作的很好,而多cpu对复制的帮助却不大。如果工作负载是cpu密集型,主库上的并发任务传递到备库以后会被简化为
串行任务,这样即使备库硬件比较比主库好,也可能无法保持跟主库之间的同步。也就是说,备库的瓶颈通常是IO子系统,而不是CPU。
如果有一个cpu密集型的工作负载,考虑是需要更快的cpu还是更多的cpu的另外因素是查询语句实际在做什么?在硬件层面,一个查询可以在等待或者
执行。处于等待状态的常见原因是在运行队列中等待(进程已经是可运行的,但所有的cpu都在忙),等待闩锁(Latch)或锁(Lock),等待磁盘或者网络。
如果等待闩锁或者锁,通常需要更快的cpu;如果在运行队列中等待,那么更多或者更快的cpu都可能有帮助。
不管是查询还是读取不同的表还是相同的表,InnoDB都会有一些全局共享的数据结构;MyISAM在每个缓冲区都有全局锁。
实际上有2种类型的数据库并发问题,需要不同的方法来解决,如下:
1.逻辑并发问题
应用程序可以看到资源的竞争,如表或者行锁争用。这些问题通常需要更好的策略来解决,如改变应用程序,使用不同的存储引擎,改变服务器的配置。
或者使用不同的锁定提示或事务隔离级别。
2.内部并发问题
比如信号量,访问InnoDB缓冲池页面的资源争用,等等。可以尝试通过改变服务器的设置,改变操作系统,或者使用不同的硬件解决。
3.平衡内存和磁盘资源
配置大量的内存最大的原因不是可以在内存中保存大量数据:最终的目的是避免磁盘IO,因为磁盘IO比在内存中访问的数据要慢的多。
随机IO和顺序IO:
数据库服务器同时使用随机IO和顺序IO,随机IO从缓存中获益最多。
典型的情况是,热点数据随机分布。因此,缓存这些数据有助于避免昂贵的磁盘寻道。相反,顺序读取一般只需要扫描一次数据,所以缓存它是没有用的,
除非完全放在内存中缓存起来。
顺序读取不能从缓存中获益的另外一个原因是它们比随机读取快。这有以下2个原因:
1.顺序IO比随机IO快
2.此次因其执行顺序读比随机读快
一个随机读意味着存储引擎必须执行索引操作。
缓存,读和写:
如果有足够的内存,就完全可以避免磁盘读取的请求。如果所有的数据文件都可以放在内存中,一旦服务器'热'起来了,所有的读操作都会在缓冲命中。
虽然还是会有逻辑读取,不过物理读取就没有了。但写入是不同的问题。写入可以向读一样在内存中完成,但迟早要被写入到磁盘,所以它是需要持久化的。
换句话说,缓冲可以延缓写入,但不能消除读取一样消除写入。
事实上,除了允许写入被延迟,缓冲还允许它们被集中操作,主要通过以下2个途径:
1.多次写入,一次刷新
一个数据可以在内存中改变很多次,而不需要把所有的变更都写入磁盘。当数据最终被刷新到磁盘后,最后一次物理写之前发生的修改都被持久化了。
2.IO合并
许多不同部分的数据可以在内存中修改,并且这些修改可以合并在一起,通过一次磁盘操作完成物理写入。
工作集:做这个工作确实需要用到的数据。
找到有效的内存/磁盘比例:
选择硬盘:
从传统磁盘读取数据分为三个步骤:
1.移动读取磁头到磁盘表面上的正确位置
2.等待磁盘旋转,所有所需的数据在读取磁头下
3.等待磁盘旋转过去,所有所需的数据都被读取磁头读出
4.固态存储
固态(闪存)存储器,也被称为 NVRAM,或者非易失性随机存取存储器。
最重要的是提升随机IO和并发性。闪存记忆体可以在高并发下提供很好的随机IO性能,这正是范式化的数据库所需要的。设计非范式化的 Schema 最常见的
原因是避免随机IO,并且使得查询转化为顺序IO。
固态存储最适合使用在任何有着大量随机IO工作负载的场景下。
优化固态硬盘上的mysql:
InnoDB 的默认配置从实践上来看是为了硬盘驱动器定制的,而不是为了固态硬盘定制的。如果用固态硬盘,可以改进如下:
1.增加InnoDB 的 IO 容量
2.让InnoDB 日志文件更大
3.把一些文件从闪存移到RAID
4.禁用预读
5.配置InnoDB刷新算法
6.禁止双写缓冲的可能
7.限制插入缓冲大小
5.为备库选择硬件
备库只能串行化执行。
6.RAID 性能优化
RAID 0 : 没有任何冗余
RAID 1 : 有很好的冗余性
RAID 5 : 奇偶校验块
RAID 10 :
RAID 50 :
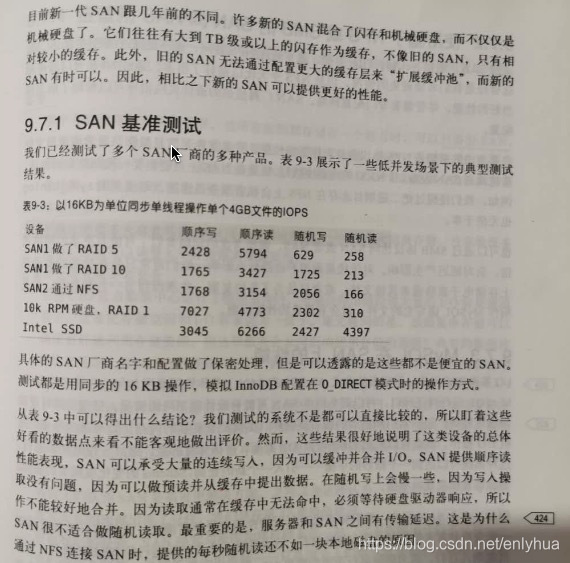
7.SAN 和 NAS
SAN(storage area network) 和 NAS(network-attached storage) 是2个外部文件存储设备加载到服务器的方法。
访问SAN设备时通过块接口服务器直接看到一块硬盘并且可以像磁盘一样使用,但是NAS设备通过基于文件的协议来访问,如NFS,SMB。
8.使用多磁盘卷
mysql 创建的文件类型:
1.数据和索引文件
2.事务日志文件
3.二进制日志文件
4.常规日志(错误日志,查询日志和慢查询日志)
5.临时表和临时文件
9.网络配置
当mysql收到一个请求时,它同时需要做正向和反向DNS查找.
1.端口范围
/proc/sys/net/ipv4/ip_local_port_range
2.允许更多的连接进入队列
/proc/sys/net/ipv4/tcp_max_syn_backlog
3.缩短tcp保持状态的时间
/proc/sys/net/ipv4/tcp_fin_timeout
10.选择操作系统
11.选择文件系统
更重要的考虑是恢复时间。如果可能,最好使用日志文件系统。
如果选择 ext3或者其继承者 ext4,有3个选项来控制数据怎么记日志,这可以放在 /etc/fstab 中作为挂载选项:
1.data=writeback
只有元数据会写入日志,这是最快的配置
2.data=ordered
也只会记录元数据,但提供了一些保证。比writeback慢,但是崩溃时更安全。
3.data=journal
提供了原子日志的行为,它的开销比其他2个都大。
不管哪种文件系统,都有一些特定的选项最好禁用。如记录访问时间的选项,甚至读文件或者目录时也要进行一次写操作。在 /etc/fstab 中添加
noatime,nodiratime 挂载选项来禁用此选项。这样做有时可以提升5%~10%的性能。如下:
/dev/sda2 /usr/lib/mysql ext3 noatime,nodiratime,data=writeback 0 1
12.选择磁盘队列调度策略
在 Linux 上,队列调度决定了到块设备的请求实际上发送到底层设备的顺序。默认情况下使用cfq(completely fair queueing,完全公平排队)策略。
随意使用的笔记本和台式机使用这个调度策略是没有问题,并且有助于防止IO饥饿,但是用于服务器则是有问题的。在mysql的工作负载类型下,cfq会导致很差
的响应时间,因为会在队列中延迟一些不必要的请求。
通过下面命令查看当前的调度策略:
cat /sys/block/sda/queue/scheduler
noop deadline [cfq]
13.线程
mysql 每个连接使用一个线程,另外还有内部处理线程,特殊用途的线程,以及所有存储引擎创建的线程。
14.内存交换区
当操作系统因为没有足够的内存而将一些虚拟内存写到磁盘就会发生内存交换。内存交换对操作系统中运行的进程是透明的。只有操作系统知道特定的虚拟内存地址
是在物理内存还是在硬盘。
内存交换对于mysql的性能影响是很糟糕的。它破坏了缓存在内存的目的,并且对于使用很小的内存做缓存,使用交换区的性能更差。mysql和存储引擎有很多算法
来区别对待内存中的数据和硬盘上的数据。
因为内存交换对用户进程是不可见的,mysql并不知道数据实际上已经移动到磁盘还是在内存中。结果会导致性能很差。例如,存储引擎认为数据依然在内存,可能觉得
为'短暂'的内存操作锁定一个全局互斥变量是ok的。如果这个操作实际上引起了硬盘IO,直到IO完成前任何操作都会被挂起。这意味着内存交换比直接做IO操作还要糟糕。
极端情况下,太多的内存交换可能会导致操作系统交换空间溢出。如果发生了这种情况,缺乏虚拟内存可能会让mysql崩溃。但是即使交换空间没有溢出,非常活跃的内存
交换也会导致整个操作系统变得无法响应,到这个时候甚至不能登录系统去杀掉mysql进程。有时当交换空间溢出时,甚至Linux内核都会完全hang住。
在特别大的内存压力下经常会发生的另一件事是内存不足(OOM),这会导致踢掉和杀掉一些进程。
15.操作系统状态
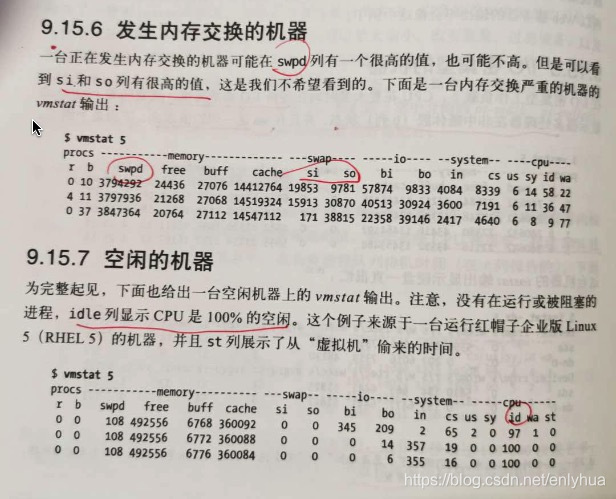
1.vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 1409384 2116 1700048 0 0 194 315 264 226 2 1 97 0 0
procs:
r : 显示了多少进程正在等待cpu
b : 显示了多少进程正在不可中断的休眠(通常意味着它们在等待IO,如磁盘,网络,用户输入等)
memory:
swpd : 显示了多少块被换到了磁盘(页面交换)。
free : 显示了多少列是空闲的,未被使用
buff : 多少块正被用作缓冲
cache : 多少正被用作操作系统的缓存
swap :
si : 每秒有多少块正被换入(从磁盘)
so : 换出(到磁盘)
大部分时间,我们比较喜欢看到 si,so 是0,并且我们很明确不希望看到每秒超过10个块。
io :
bi : 多少块从块设备读取
bo : 从块设备写出
反应了硬盘IO
system :
in : 这些列显示了每秒中断
cs : 上下文切换的数量
cpu :
所有cpu所花费在各类操作的百分比
us : 执行用户代码
sy : 执行系统代码(内核)
id : 空闲
wa : 等待IO
st : 从虚拟机中 '偷走' 的百分比。这关系到那些虚拟机想运行但是系统管理程序转而运行其他的对象的时间。如果虚拟机
不希望运行任何对象,但是系统管理程序运行了其他对象,这不算被偷走的cpu
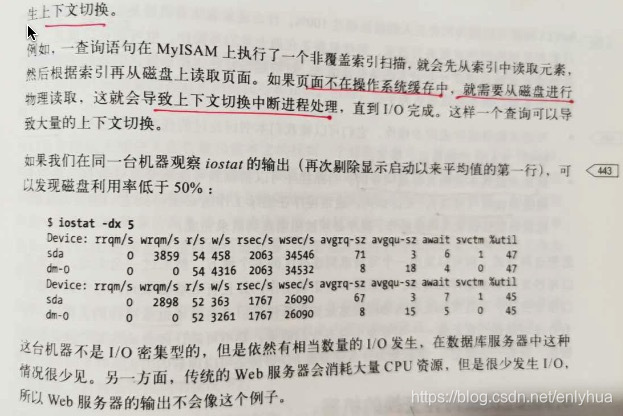
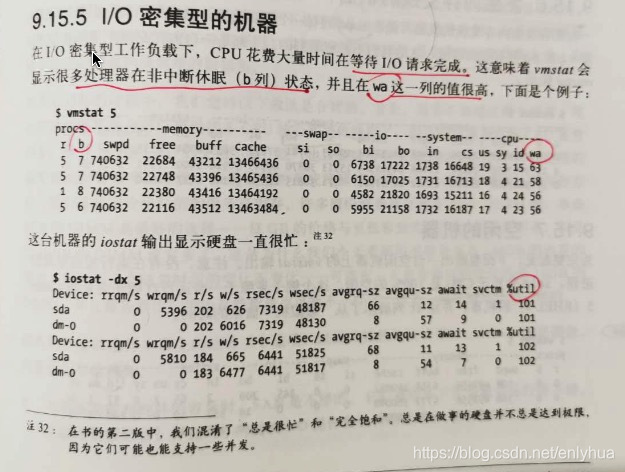
2.iostat -dx 5
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.12 2.58 1.33 109.25 177.34 146.32 0.01 2.57 2.07 3.55 0.82 0.32
dm-0 0.00 0.00 2.08 1.00 102.35 176.00 181.00 0.01 3.19 2.25 5.15 0.94 0.29
dm-1 0.00 0.00 0.02 0.00 0.38 0.00 47.40 0.00 2.50 2.50 0.00 1.83 0.00
dm-2 0.00 0.00 0.13 0.04 1.08 0.98 23.61 0.00 2.36 2.02 3.50 1.86 0.03
rrqm/s 和 wrqm/s : 每秒合并的读和写请求。'合并的'意味着操作系统从队列中拿出多个逻辑请求合并为一个请求到达实际磁盘。
r/s 和 w/s : 每秒发送到设备的读和写请求
rkB/s 和 wkB/s : 每秒读和写的扇区数。
avgrq-sz : 请求的扇区数
avgqu-sz : 在设备中等待的请求数
await : 磁盘排队上花费的毫秒数
svctm : 服务请求花费的毫秒数,不包括排队时间
%util : 至少有一个活跃请求所占时间的百分比。
可以利用iostat的输出判断某些机器的 IO 子系统的实际情况。一个重要的度量标准是请求服务的并发数。因为读写的单位是每秒而服务器时间点的单位是
千分之一秒,所以可以利用特尔法则得到下面的公式,计算出设备服务的并发请求数:
concurrency = (r/s + w/s) * (svctm/1000)
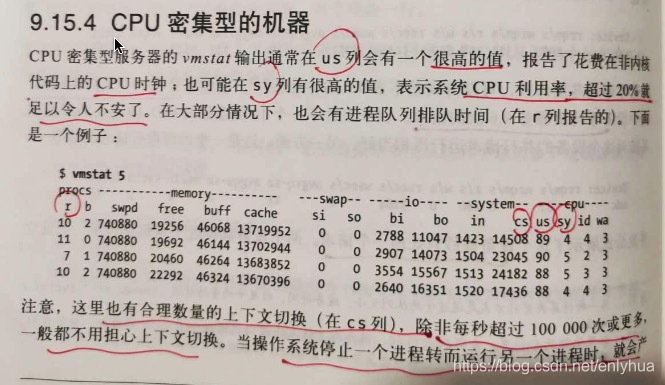
3.CPU 密集型的机器
cpu 密集型的机器的 vmstat 输出通常在 us 列会有一个很高的值,报告了花费在非内核代码上的 cpu 时钟;也可能在 sy 列有很高的值,表示系统cpu
利用率,超过 20% 就足以令人不安了。在大部分情况下,也会有进程排队时间(在 r 列报告的)。
注意,整理也有合理数量的上下文切换(cs列),除非每秒超过 10 0000 次或者更多,一般都不用担心上下文切换。当操作系统停止一个进程转而运行另外
一个进程,就会产生上下文切换。
4.IO 密集型的机器
在IO密集型工作负载下,cpu花费大量时间在等待IO请求完成。这意味着vmstat会显示很多处理器在非中断休眠(b列)状态,并且在 wa 列很高。
5.发生内存交换的机器
一台正在发生内存交换的机器可能在 swpd 列有很高的值,也可能不高。但是可以看到 si 和 so 列有很高的值。
6.空闲的机器
idle 列显示了cpu 100% 的空闲。

1.什么限制了 MySQL 性能


2.如果为 MySQL 选择 CPU









3.平衡内存和磁盘资源














- 固态存储


























5.为备库选择硬件











































































 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









