




卷积神经网络
1、简介
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络,卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要由三部分组成:卷积层、池化层和全连接层构成:
- 卷积层负责提取图像中的局部特征
- 池化层用来大幅降低参数量级(降维)
- 全连接层用来输出想要的结果
2、卷积层

-
input 表示输入的图像
-
filter 表示卷积核, 也叫做卷积核(滤波矩阵)
-
input 经过 filter 得到输出为最右侧的图像,该图叫做特征图
(一)、卷积
卷积运算本质上就是在卷积核和输入数据的局部区域间做点积。
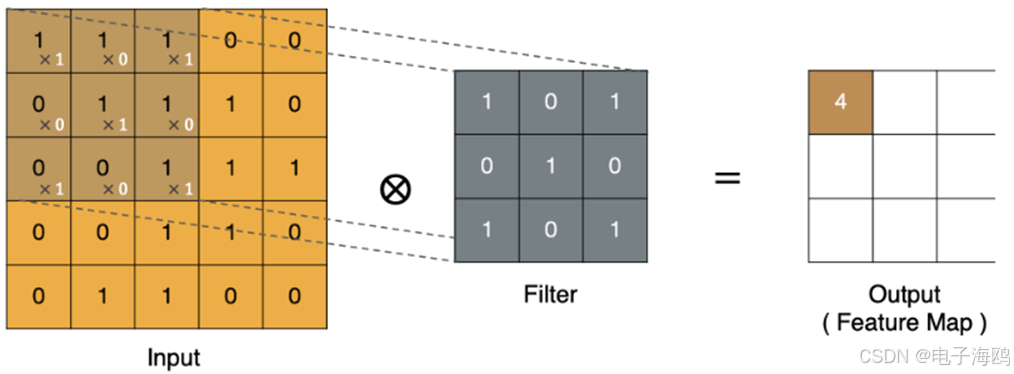
(二)、padding
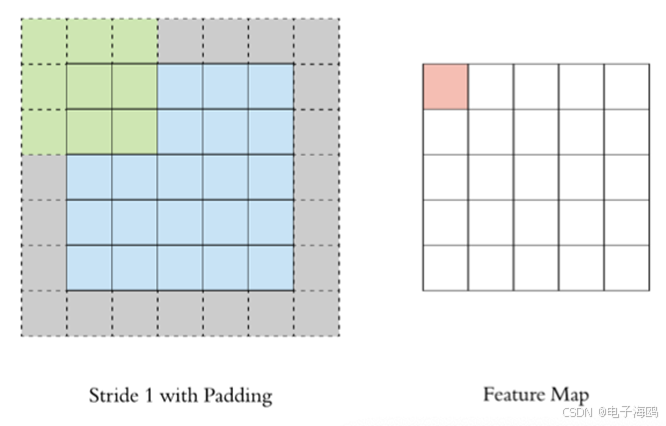
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 padding 来实现。

(三)、stride

(四)、多通道卷积计算
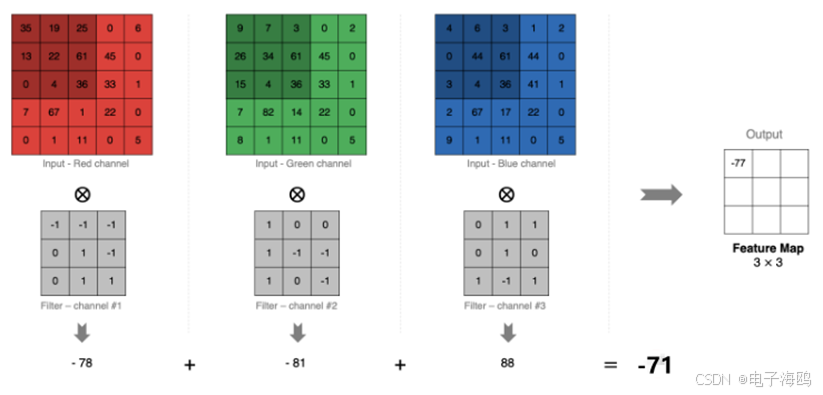
实际操作中,图像都是多通道组成,我们怎样去计算卷积呢?

分别计算卷积后,求和

(五)、多卷积核卷积计算
当使用多个卷积核时,应该怎么进行特征提取?
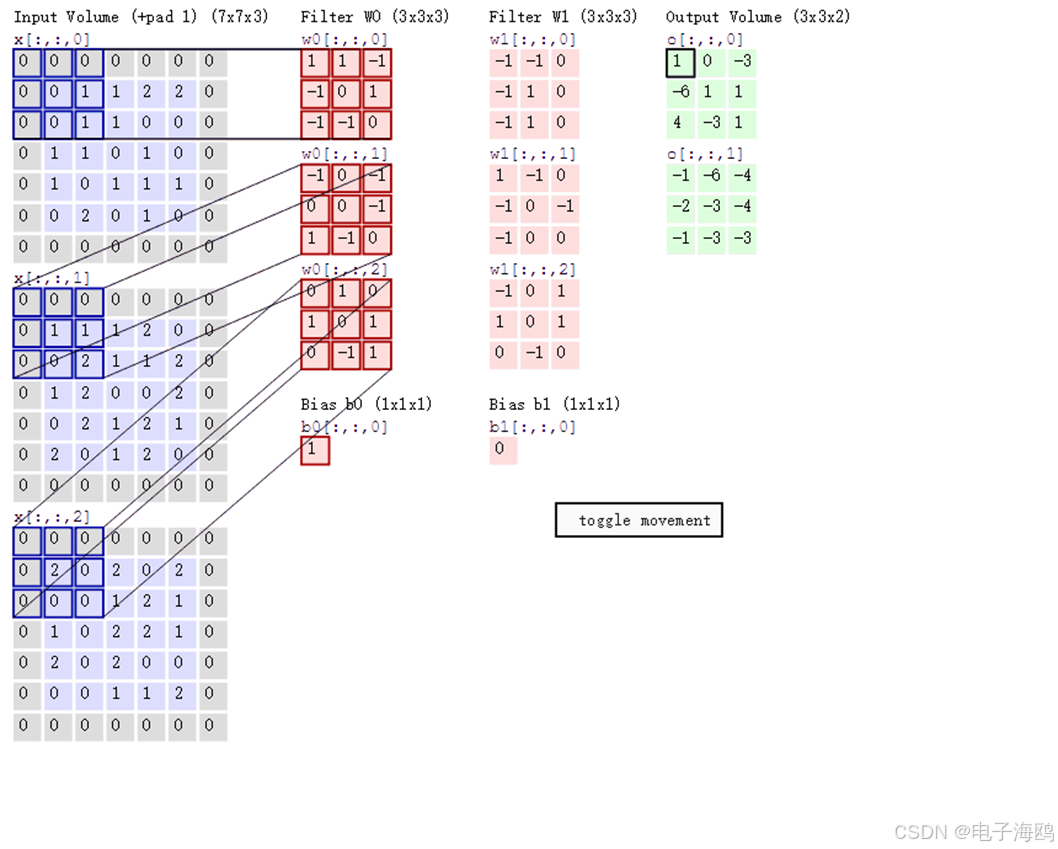
(六)、特征图大小计算
输出特征图的大小与以下参数息息相关:
-
size: 卷积核/过滤器大小,一般会选择为奇数,比如有 11 、33、5*5
-
padding: 零填充的方式
-
stride: 步长
计算方式如下:
N=W−F+2PS+1输入图像大小:W×W卷积核大小:F×Fstride:Spadding:P输出图像大小:N×N
N=\frac{W-F+2P}{S}+1\\
输入图像大小:W×W\\
卷积核大小:F×F\\
stride:S\\
padding:P\\
输出图像大小:N×N
N=SW−F+2P+1输入图像大小:W×W卷积核大小:F×Fstride:Spadding:P输出图像大小:N×N
例如:
- 图像大小: 5 x 5
- 卷积核大小: 3 x 3
- Stride: 1
- Padding: 1
- (5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
(七)、API
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
'''
in_channels (int):输入图像中的通道数
out_channels (int):由卷积产生的通道数
kernel_size (int或tuple):卷积核的大小
stride (int或tuple,可选):卷积的步幅。默认值:1
padding (int, tuple或str,可选):填充到输入特征图,默认值:0
padding_mode (str,可选):”0“”、“”反映的“,”“复制”“”或“”循环的' '。默认值:“0”“(int或tuple,可选):内核元素之间的间距。默认值:1
groups (int,可选):从输入通道到输出通道的阻塞连接数。默认值:1
bias (bool,可选):如果"True",则在输出中添加一个可学习的偏差。默认值:“True”
'''
3、池化层
(一)、池化层计算
池化层 (Pooling) 降低维度, 缩减模型大小,提高计算速度。

(二)、stride
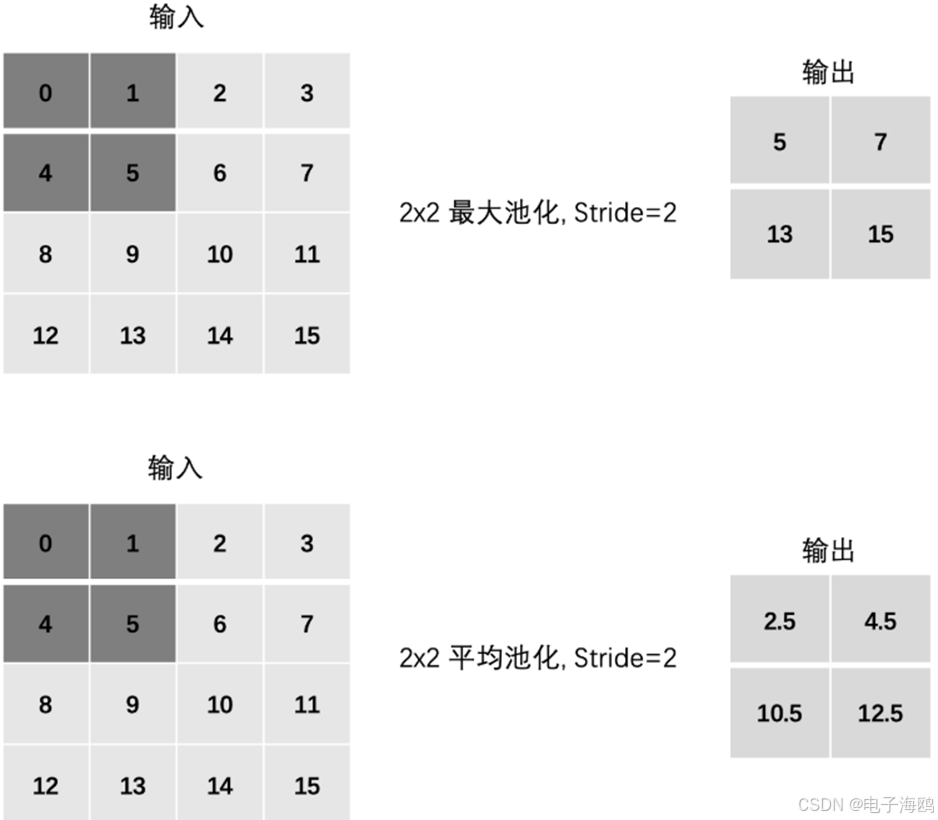
(三)、padding

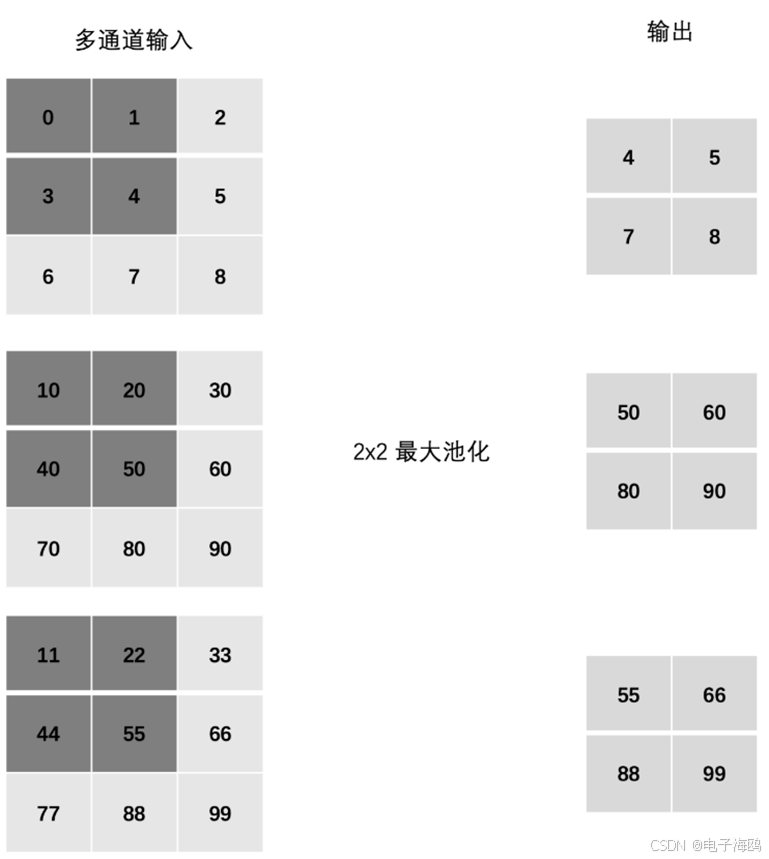
(四)、多通道池化层计算
(五)、池化层API
# 最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
'''
Kernel_size:要占用的最大窗口的大小
stride:窗户的跨步。默认值为:attr:"kernel_size"
padding:两侧要添加的隐式负无穷大填充
dilation:控制窗口中元素的步幅的参数
return_indices:如果"True",将返回最大索引以及输出。
适用于:class:"torch.nn.MaxUnpool2d”后
ceil_mode:当为True时,将使用"ceil"而不是"floor"来计算输出形状
'''
# 平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
'''
Kernel_size:窗口的大小
stride:窗户的跨步。默认值为:attr:"kernel_size"
padding:隐式的零内边距将在所有三面添加
ceil_mode:当为True时,将使用"ceil"而不是"floor"来计算输出形状
count_include_pad:当为True时,将在平均计算中包含零填充
Divisor_override:如果指定,它将被用作除数,否则:attr:"kernel_size"将被使用
'''
4、CIFAR10图像分类案例
# 导包
import time
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor, Compose
from torch.utils.data import DataLoader
# 设置运算单元
cuda = torch.device("cuda")
# 获取数据
def create_dataset():
transform = Compose([ToTensor()])
train = CIFAR10(root='data', train=True, download=True, transform=transform)
vaild = CIFAR10(root='data', train=False, download=True, transform=transform)
return train, vaild
# 建立模型
class cv_model(nn.Module):
def __init__(self):
super(cv_model, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
# BN层
self.bn1 = nn.BatchNorm2d(32)
# 池化层
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
# 池化层
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
# 池化层
self.pool3 = nn.AvgPool2d(kernel_size=2, stride=2)
# 全连接层
# self.linear0 = nn.Linear(128 * 4 * 4, 1024)
self.linear1 = nn.Linear(2048, 512)
self.linear2 = nn.Linear(512, 256)
self.linear3 = nn.Linear(256, 128)
self.linear4 = nn.Linear(128, 64)
# nn.init.xavier_normal_(self.linear3.weight)
self.fc = nn.Linear(64, 10)
def forward(self, x):
x = self.pool1(torch.relu(self.conv1(x)))
x = self.pool2(torch.relu(self.conv2(x)))
x = self.pool3(torch.relu(self.conv3(x)))
x = x.reshape(x.size(0), -1)
# x = torch.relu(self.linear0(x))
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
x = torch.relu(self.linear3(x))
x = torch.relu(self.linear4(x))
# dropout = nn.Dropout(0.8)
# x = dropout(x)
return self.fc(x)
# 训练模型
def train_model(model, train_dataset, num_epochs, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)
start = time.time()
for epoch in range(num_epochs):
dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
total_loss = 0.0
total_num = 1
for x, y in dataloader:
x, y = x.to(cuda), y.to(cuda)
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_num += 1
print(f'epoch:{epoch}, loss:{total_loss / total_num}, time:{time.time() - start}')
torch.save(model.state_dict(), 'data/model/model1.pth')
# 计算预测精度
def test(valid_dataset):
# 构建数据加载器
dataloader = DataLoader(valid_dataset, batch_size=8, shuffle=True)
# 加载模型并加载训练好的权重
model = cv_model().to(cuda)
model.load_state_dict(torch.load('data/model/model1.pth'))
model.eval()
# 计算精度
total_correct = 0
total_samples = 0
# 遍历每个batch的数据,获取预测结果,计算精度
for x, y in dataloader:
x, y = x.to(cuda), y.to(cuda)
output = model(x)
total_correct += (torch.argmax(output, dim=-1) == y).sum()
total_samples += len(y)
# 打印精度
print('Acc: %.3f' % (total_correct / total_samples))
if __name__ == '__main__':
# train_dataset, vaild_dataset = create_dataset()
# plt.figure(figsize=(2, 2))
# plt.imshow(train_dataset.data[1])
# plt.show()
train_dataset, test_dataset = create_dataset()
model = cv_model().to(cuda)
train_model(model, train_dataset, 50, 128)
test(valid_dataset=test_dataset)
结果:
epoch:0, loss:1.7613592229935588, time:4.846324443817139
epoch:1, loss:1.3295656585571718, time:9.640836477279663
epoch:2, loss:1.0933615381316262, time:14.640412092208862
epoch:3, loss:0.9363998112325765, time:19.95414161682129
epoch:4, loss:0.8110160149481832, time:25.264078617095947
epoch:5, loss:0.6966068256570368, time:30.539992332458496
epoch:6, loss:0.6078249838735376, time:35.77179217338562
....
epoch:14, loss:0.13294050235263244, time:78.57502555847168
epoch:15, loss:0.12194599922537347, time:83.9551248550415
epoch:16, loss:0.11020404038409114, time:89.62402033805847
epoch:17, loss:0.09626854594074646, time:95.05350303649902
epoch:18, loss:0.08197111733096214, time:100.44407653808594
....
epoch:31, loss:0.0502818250465587, time:171.21738266944885
epoch:32, loss:0.04245567006149272, time:176.7062246799469
epoch:33, loss:0.03994235387446159, time:182.3315486907959
epoch:34, loss:0.04389468806618183, time:188.0010974407196
epoch:35, loss:0.04615501189849111, time:193.32318544387817
....
epoch:47, loss:0.031241593034866705, time:258.6930603981018
epoch:48, loss:0.03505272038722867, time:264.0214114189148
epoch:49, loss:0.0346011698973004, time:269.329030752182
Acc: 0.725
常见的优化方向:
- 增加卷积核输出通道数
- 增加全连接层的参数量
- 调整学习率
- 调整优化方法
- 修改激活函数
*基础网络:卷积+BN+激活+池化

















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









