



 文章介绍了bean-searcher,一种专注于高级查询的轻量级ORM框架,无需额外依赖,简化后端开发,支持联表查询、排序和分页,但功能有限,主要适用于列表检索场景。
文章介绍了bean-searcher,一种专注于高级查询的轻量级ORM框架,无需额外依赖,简化后端开发,支持联表查询、排序和分页,但功能有限,主要适用于列表检索场景。
1. 简介
在我们的日常开发中,列表检索是一个绕不开的领域,涉及到多表连接查询、复杂查询条件的拼接,常用的框架如mybatis需要使用xml约定查询sql,不容易debug调试,mybatis-plus虽然不需要写xml,但本身不支持连接查询,需要引入第三方工具包如mybatis-plus-join,加大学习成本。这里介绍一个更轻量级,学习成本更低,开发效率更高的orm框架——bean-searcher。bean-searcher是一种针对列表检索的轻量级ORM框架,不依赖任何第三方框架例如mybaits、mybatis-plus、jpa等,可直接嵌入到项目替换掉原有的查询接口。
2. 官方资料
gitee: bean-searcher: 🔥🔥🔥 专注高级查询的只读 ORM,天生支持联表,免 DTO/VO 转换,使一行代码实现复杂列表检索成为可能!
官方文档:起步 | Bean Searcher (zhxu.cn)
3. beanSearch简单介绍
3.1 优点
3.1.1极大的简化了后端的开发速度
传统的列表查询需要定义查询参数实体类,bean-searcher则选择将查询参数全部交由前端确定,使得在极端情况下,后端只需要一行代码便能完成带有极高拓展性的查询列表接口,如下所示:
@Autowired
private MapSearcher beanSearcher;
@GetMapping("/index")
public Object index(@RequestParam Map<String, Object> params) {
// 组合检索、排序、分页 和 统计 都在这一句代码中实现了
return beanSearcher.search(Employee.class, params);
}并且后续如果前端需要更多的查询参数,也只需要按照固定的规范新增传参即可,大大降低了后端的维护工作量。
3.1.2支持多表连接查询。
与mybatis需要使用xml、mybatis-plus需要引入第三方包才能实现连接查询相比,bean-searcher提供了一套完整的注解,使得我们可以在连接查询对应的vo类上直接约定连接查询条件以及属性映射关系,如下所示:
@SearchBean(tables = "employee e left join department d on e.department_id = d.id",autoMapTo = "e",
orderBy = "e.entry_date desc",sortType = SortType.ALLOW_PARAM)
public class Employee extends BaseBean {
@DbField(onlyOn = { StartWith.class, Contain.class , Empty.class, NotEmpty.class})
private String name;
private Integer age;
private Gender gender;
@DbField("d.name")
private String department;
@JsonFormat(pattern="yyyy-MM-dd HH:mm", timezone = "GMT+8")
private LocalDateTime entryDate;
}
上述代码便完成了数据库中employee表和 department 表的连接查询,条件为employee .department_id = department.id,实体类的属性默认映射到employee表属性,查询结果默认按entry_date 降序排列。且可以由@DbField指定特殊的属性映射关系。
3.1.3. 相对优秀的性能。
bean-searcher默认在第一次执行某个vo的查询时,会把其属性和数据库字段的映射关系初始化到缓存中去,这就使得bean-searcher在经过一次预热后,性能变得非常优秀,在使用h2内存数据库的情况下进行测试,结果如下图,单位毫秒:
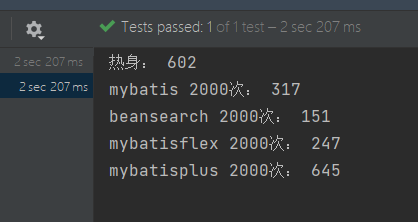
不过实际生产中,查询的时间消耗主要是io等待,orm框架上的性能优化对整体性能的影响比较小,上图差距如此大的原因也是使用了h2内存数据库,省去了远程io等待的过程。在使用mysql作为数据库的情况下,预热一轮,后执行200次的结果如下图所示:
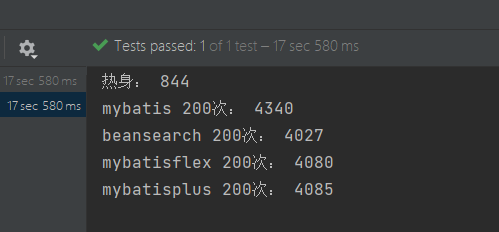
可以看到没有太大差距。
3.2. 缺点
3.2.1. 功能太少
功能上的对比如下如图
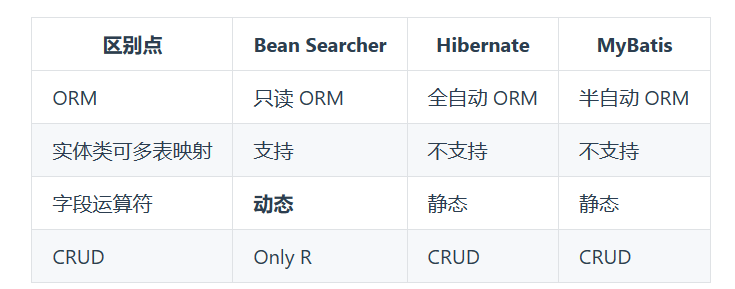
这与bean-searcher本身的定位有关系,bean-searcher只是弥补其他框架在列表检索领域的不足,所以只支持查询操作,并且本身并没有类似mybatis一级缓存机制,所以无法配合事务进行性能优化,无法应付列表检索外的其他常用查询。
3.3. 小结
bean-searcher有着不错的性能以及能极大程度的提高开发效率,可以替换原有项目中的分页查询接口,但本身提供的功能比较少,所以只能局限在列表检索领域使用。
4. 简单入门
4.1. 入参规范
相信看到第3节的小伙伴都非常好奇,既然入参完全交给前端了,那前端到底该怎么传参做才能应对复杂的实际查询业务呢?接下来会对常见的入参规范进行介绍。第3节接口对应postman如下:
4.1.1. 分页参数
page=1&size=10。注意框架有默认的分页配置,当使用beanSearcher.search()时会收到默认配置的约束,配置类如下,可通过bean-searcher.params.pagination.*设置需要的配置
public static class Pagination {
public static final String TYPE_PAGE = "page";
public static final String TYPE_OFFSET = "offset";
/**
* 默认分页大小,默认为 15
*/
private int defaultSize = 15;
/**
* 分页类型,可选:`page` 和 `offset`,默认为 `page`
* */
private String type = TYPE_PAGE;
/**
* 分页大小参数名,默认为 `size`
*/
private String size = "size";
/**
* 页码参数名(仅在 type = `page` 时有效),默认为 `page`
*/
private String page = "page";
/**
* 页偏移参数名(仅在 type = `offset` 时有效),默认为 `offset`
*/
private String offset = "offset";
/**
* 起始页码 或 起始页偏移,默认为 0,
* 注意:该配置对方法 {@link MapBuilder#page(long, int)} } 与 {@link MapBuilder#limit(long, int)} 无效
*/
private int start = 0;
/**
* 分页保护:每页最大允许查询条数,默认为 100,
* 注意:该配置对 {@link BeanSearcher#searchAll(Class)} 与 {@link MapSearcher#searchAll(Class)} 方法无效
*/
private int maxAllowedSize = 100;
/**
* 分页保护:最大允许偏移量,如果是 page 分页,则最大允许页码是 maxAllowedOffset / size
*/
private long maxAllowedOffset = 20000;
}
4.1.2. 属性查询条件
onlySelect=id,name——只查出需要的属性
selectExclude=department——不查出该属性
[field]=value——查出对应属性等于value的数据,其中field需要与VO类的成员变量相对应
[field]-op=operate——属性过滤的具体操作,常[field]=value一起使用,默认operate为eq,语义为[field]等于value,其中operate可为eq、ne、ge、le、gt、lt、bt(between)、il(inList)、ct(contains)、sw(startwith)、ew(endwith)、ey(empty)、ny(notEmpty)
有小伙伴可能会感觉给前端提供如此多的操作是否不安全,也可以通过在VO的成员变量上添加@DbField(onlyOn = { StartWith.class,, Empty.class, NotEmpty.class}),约束生效的operate。
此外,像bt、in这种value为多个值的,可以参考对于 op=mv / bt 的查询,使用 `ParamFilter` 来简化多值传参,例如:用 age=[20,30] 替代 age-0=20&age-1=30 · Issue #10 · troyzhxu/bean-searcher · GitHub进行设置
[field]-ic=true——是否忽略大小写
拓展:约定自定义的操作符高级 | Bean Searcher (zhxu.cn)
4.1.3. 排序参数:
单列排序:sort=[field]&order=asc/desc——按id增序排列
多列排序:orderBy=age:asc,id:asc
4.2. 逻辑分组
细心的小伙伴可以发现,4.1节的条件都是and关系,bean-searcher同样也支持逻辑关系约定,具体做法可参考检索参数 | Bean Searcher (zhxu.cn)
大致思路是将条件进行分组,再使用gexpr针对分组进行逻辑定义,如图,注意"|","&"这种特殊符号在url里面需要转移
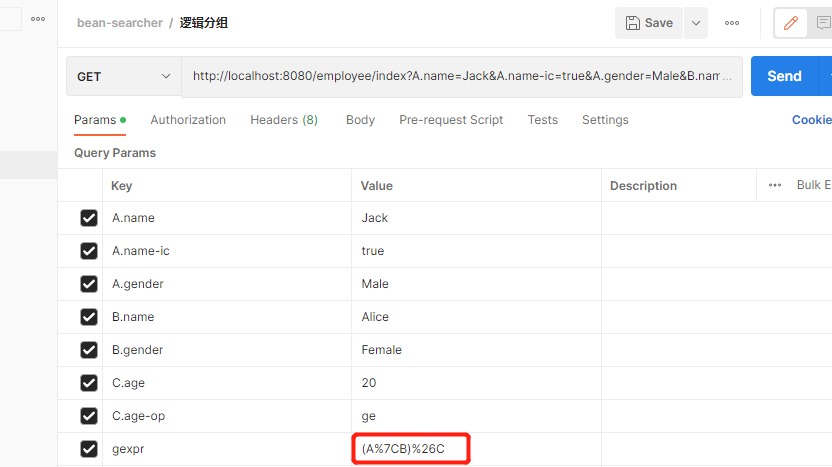
5. 彩蛋 用一个接口处理所有的列表查询操作
/**
* 所有的查询列表操作放到同一个接口实现
*/
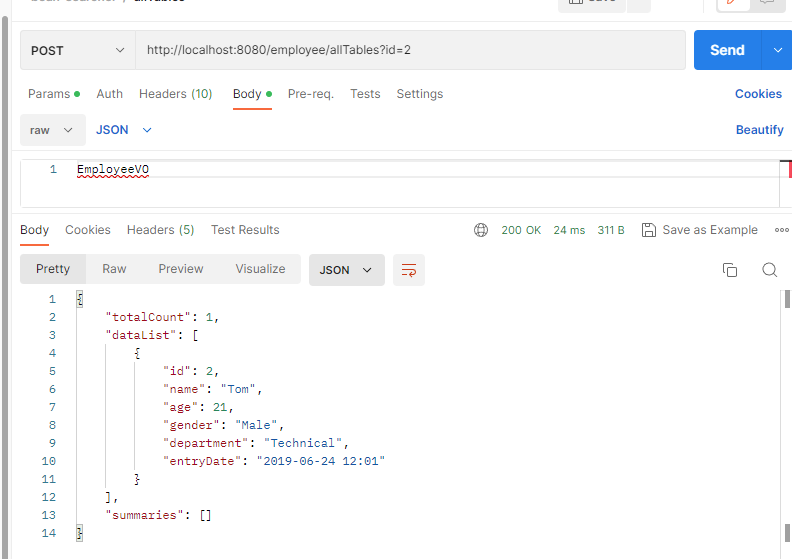
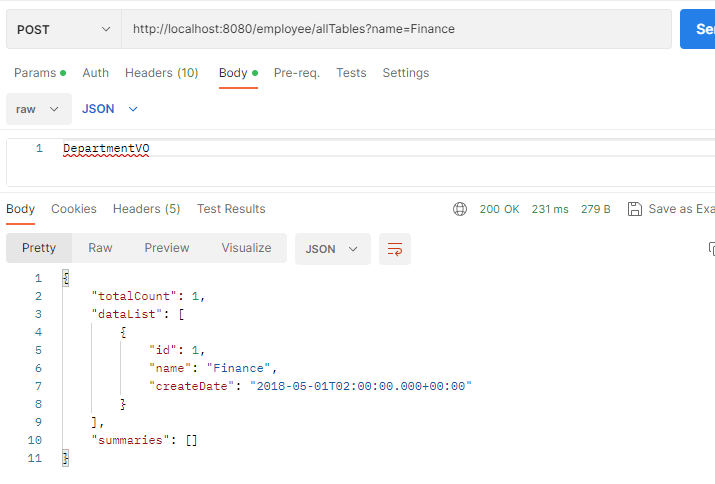
@PostMapping("/allTables")
public Object allTables(@RequestBody String table, HttpServletRequest request) throws ClassNotFoundException {
Class<?> tableClass = Class.forName("com.example.sbean."+table);
return beanSearcher.search(tableClass, MapUtils.flat(request.getParameterMap()));
}
前端在body中传递VO对应实体类名,接口通过反射获取到对应的class对象,即可实现同一个接口,查询所有vo的列表,如下所示

















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









