




 本文详细介绍了多核CPU缓存的层级结构,包括从寄存器到主存的不同访问延迟,并探讨了Intel Mesi缓存一致性协议的工作原理。此外,还讨论了缓存行对齐的重要性及其在JDK中的应用,以及合并写技术和非统一内存访问(UMA和NUMA)的概念。
本文详细介绍了多核CPU缓存的层级结构,包括从寄存器到主存的不同访问延迟,并探讨了Intel Mesi缓存一致性协议的工作原理。此外,还讨论了缓存行对齐的重要性及其在JDK中的应用,以及合并写技术和非统一内存访问(UMA和NUMA)的概念。
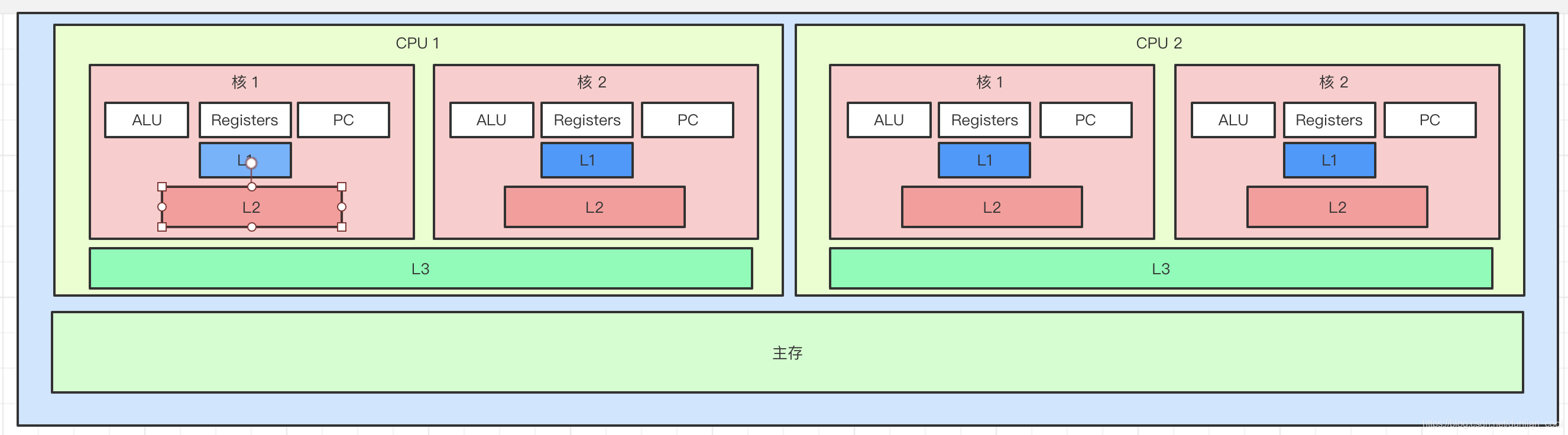
多核CPU
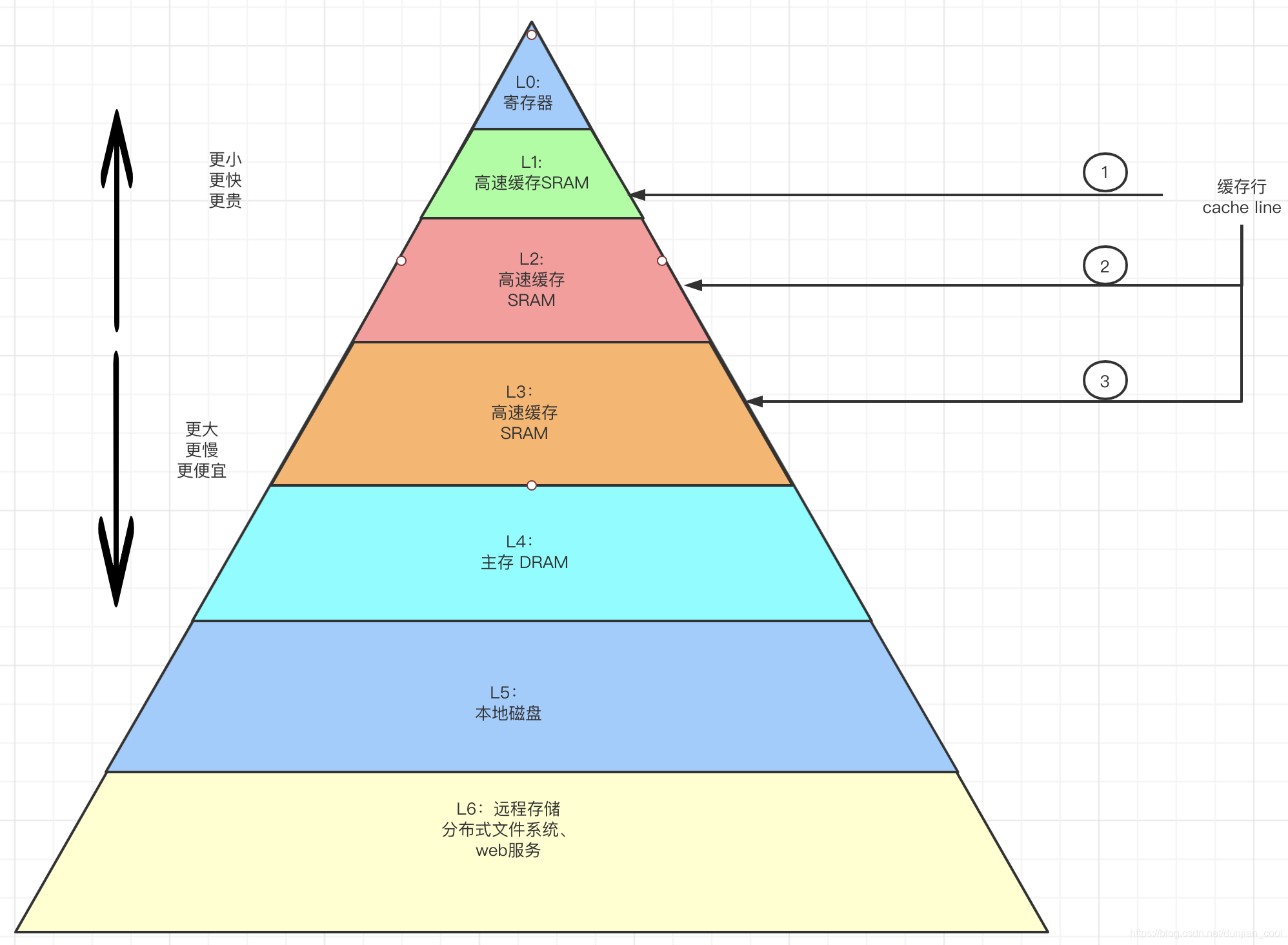
| Registers | < 1ns |
| L1 | 约 1ns |
| L2 | < 3ns |
| L3 | 约15ns |
| 主存 | 约 80ns |
为什么三层:工业测试的效果最好
缓存行大小:越大,局部性空间效率越大,读取越慢;越小,局部性空间效率越小,读取越快。64字节(intel)
Intel mesi 缓存一致性协议(又叫缓存锁)
其他 msi
一致性协议无法保证缓存一致性时 :跨越多个缓存行、无法缓存的数据
使用总线锁的策略
实践的指导意义:
缓存行对齐:对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存行对齐的编程方式
JDK7中,很多采用long padding提高效率 如disruptor
JDK8,加入了@Contended注解需要加上:JVM -XX:-RestrictContended 根据机器情况帮助填充
扩展概念:
1、合并写技术: Write Combining Buffer
一般是4个字节,由于ALU速度太快,所以在写入L1的同时,写入一个WC Buffer,满了之后,再直接更新到L2
2、UMA 和 NUMA 和 NUMA aware Non Uniform Memory Access
ZGC - NUMA aware:分配内存会优先分配该线程所在CPU的最近内存
参考:缓存一致性协议 https://www.cnblogs.com/z00377750/p/9180644.html

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









