






 本文讲述了作者在使用BERT模型时遇到的GPU运行速度慢的问题,通过排查发现容器环境未正确连接GPU。解决过程包括指定Docker运行时GPU参数、检查代码中设备选择和模型加载一致性,最终通过显式指定所有张量设备解决了问题。
本文讲述了作者在使用BERT模型时遇到的GPU运行速度慢的问题,通过排查发现容器环境未正确连接GPU。解决过程包括指定Docker运行时GPU参数、检查代码中设备选择和模型加载一致性,最终通过显式指定所有张量设备解决了问题。
模型加载到GPU运算【踩坑备忘】
背景,主服务调用一个bert模型,测试使用,没怎么看,改了改开源代码能连上用就行,但是运行速度极慢,怀疑用的cpu,开始排查
docker内
python=3.9
torch=2.0.1
服务开始之后查看gpu运行情况nvidia-smi
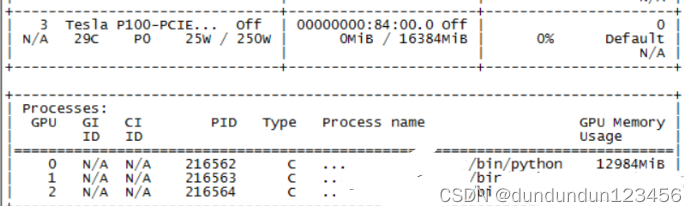
环境指定gpu
发现gpu没挂上,因为在程序里面已经指定了
os.environ[“CUDA_VISIBLE_DEVICES”] = “3”
是没有作用吗
然后直接在执行时候一起指定了
CUDA_VISIBLE_DEVICES=3 python test.py
还是没挂上,然后开始从代码找问题
容器无法连接gpu
先看了一下我的语句
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
就是说代码自动判断cuda是否可用否则用cpu,那明显这里应该是判断不可用了
然后为了验证我直接在环境里用python执行了一下
>>>import torch
>>>print(torch.cuda.is_available())
False
结果返回false,所以就是说我的容器环境里面程序就没找到可用gpu,
(然后发现我最上面执行nvidia-smi的时候是在本机而不是容器里面,要不然当时就应该曝出信息找不到cuda之类的)
所第一个问题锁定:
容器无法连接gpu
原因:
创建docker时候没有指定
解决方法:
创建docker环境的时候docker run -it -d [xxx1] [xxx2] [xxx3]加一个参数
--gpus all
重新创建之后:
>>>import torch
>>>print(torch.cuda.is_available())
True
这样就是说我的device是可以找到cuda了
但是再次启动服务,docker内可以连接cuda了,但是程序显然没有使用,第三块卡还是没有数据加载
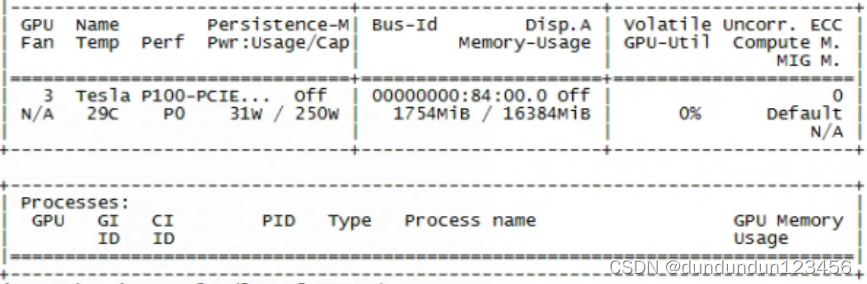
继续看代码:
self.model = self.x.Model(self.config).to('cpu')
self.model.load_state_dict(torch.load(self.config.save_path, map_location='cpu'))
直接改成cuda,这时候是会报错了
Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)
注意这里cuda0就是我指定的cuda3,因为我指定CUDA_VISIBLE_DEVICES=3表示我的程序只能找到这一块gpu它就会自动被变为第一个也就是cuda0
模型加载不一致
这个错误就是说我有一部分中间量加载到了cuda0,有一部分加载到了cpu,因为map_location指定以后load_state_dict本身就是单纯加载数据指定位置的,按理说它不会有错,那现在这个加载位置不一致的报错两种情况:
1.Model和load_state_dict加载位置不一致
2.Model自己内部不一致
这两个我不知道是Model还是map_location加载数据时应将它们映射有问题,所以控制变量法,两个参数两个值,四种情况而已:
①cpu+cpu是正常的
self.model = self.x.Model(self.config).to(‘cpu’)
self.model.load_state_dict(torch.load(self.config.save_path, map_location=‘cpu’))
cpu运算很慢
②cuda+cuda报错
self.model = self.x.Model(self.config).to(‘cuda’)
self.model.load_state_dict(torch.load(self.config.save_path, map_location=‘cuda’))
Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)
③cuda+cpu报错
self.model = self.x.Model(self.config).to(‘cuda’)
self.model.load_state_dict(torch.load(self.config.save_path, map_location=‘cpu’))
Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)
④cpu+cuda是正常的
self.model = self.x.Model(self.config).to(‘cpu’)
self.model.load_state_dict(torch.load(self.config.save_path, map_location=‘cuda’))
慢,但是能跑,说明这个不一致没有出在load_state_dict过程中也和它无关,Model和load_state_dict不一致这个可能性排除
所以第二个问题锁定:
x.Model过程中加载不一致
原因:
检索网上帖子“在进行张量运算时,涉及的张量并不都在同一个计算设备上”
解决方法:
一步步锁定中间值终于找到这句:
embedding_output = self.embeddings(input_ids, token_type_ids)
encoded_layers = self.encoder(embedding_output,
extended_attention_mask,
output_all_encoded_layers=output_all_encoded_layers)
那就是笨办法把所有值to(device=‘cuda’)指定一遍:
input_ids=input_ids.to(device='cuda')
token_type_ids=token_type_ids.to(device='cuda')
embedding_output = self.embeddings(input_ids, token_type_ids)
embedding_output = embedding_output.to(device='cuda' )
extended_attention_mask=extended_attention_mask.to(device='cuda' )
encoded_layers = self.encoder(embedding_output,
extended_attention_mask,
output_all_encoded_layers=output_all_encoded_layers)
然后再次启动服务,查看gpu情况:
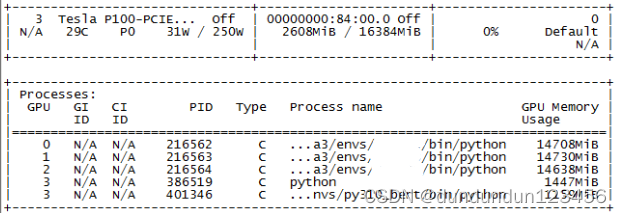
好的,一切正常
备注:这个是2023_gd_node项目的一些记录,互联网备忘录一下

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









