






 本文深入剖析了LinkedHashMap的数据结构,包括其底层实现、继承结构、基本属性、构造方法及核心方法。LinkedHashMap是一种有序的HashMap实现,支持插入有序和访问有序,通过双向链表维护键值对的顺序。
本文深入剖析了LinkedHashMap的数据结构,包括其底层实现、继承结构、基本属性、构造方法及核心方法。LinkedHashMap是一种有序的HashMap实现,支持插入有序和访问有序,通过双向链表维护键值对的顺序。
本文首先介绍LinkedHashMap的底层数据结构,然后从继承结构,基本属性,构造方法,核心方法等方面进行介绍,最后再进行特点总结。
LinkedHashMap是key键有序的HashMap的一种实现,除了使用哈希表,还使用了双向链表保证key的顺序性。而LinkedHashMap提供了两种key的有序:1、插入有序;2、访问有序;
-
数据结构
LinkedHashMap底层是“数组+双向链表”,较之于HashMap的Entry节点新增了两个属性:before,after;这主要与LinkedHashMap的访问有序相关,此时的Entry节点有六个属性(K key,V value,int hash,Entry next,Entry before,Entry after);下列图引自:https://www.cnblogs.com/chenpi/p/5294077.html
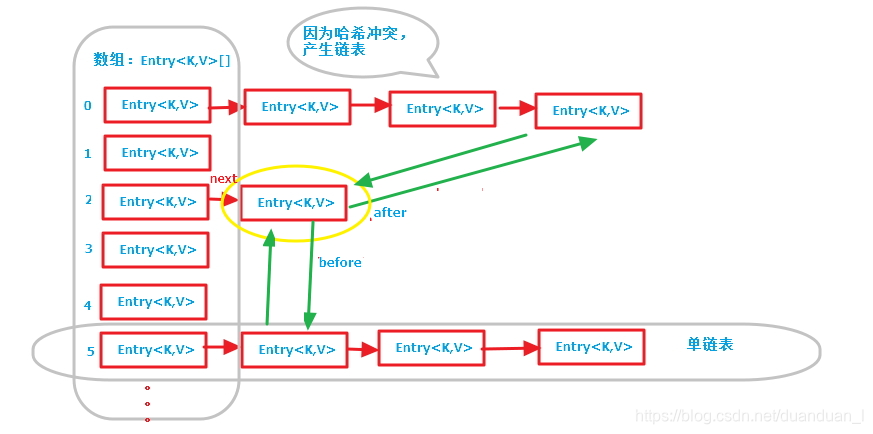
上图即为LinkedHashMap的底层数据结构,其中还有双向循环链表,如下图:
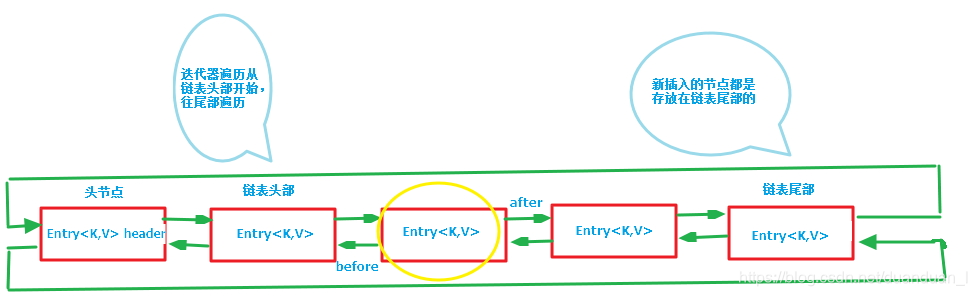
循环双向链表主要是在访问有序时进行操作的,访问有序时,通过header头节点将整个双向循环链表组织起来,头节点是整个双向循环链表的入口,一般不存放键值对,双向循环链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点。
-
继承结构
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>LinkedHashMap继承于HashMap,实现了Map接口;
-
基本属性
private static final long serialVersionUID = 3801124242820219131L;
//主要用于占位,Entry类型,不存数据,双向循环链表头节点
private transient Entry<K,V> header;
//accessOrder为true,按访问顺序排序,为false,按插入顺序排序
private final boolean accessOrder;
accessOrder属性是LinkedHashMap中非常重要的属性,它决定了是按照访问有序还是插入有序,具体体现在哪里,详见核心方法分析;
-
构造器
//指定初始容量和加载因子,默认按插入顺序排序
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);//调用父类构造器,而父类构造器中调用了Init方法,LinkedHashMap重写了该方法
accessOrder = false;
}
@Override
void init() {//该方法new了双向循环链表的头节点,初始化其前后引用;
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
//指定初始容量,调用父类HashMap的对应构造器,默认按插入顺序排序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
//默认构造器,调用父类构造器,默认按插入顺序排序
public LinkedHashMap() {
super();
accessOrder = false;
}
//根据指定的Map生成HashMap,调用父类构造器,默认按插入顺序排序
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
//生成一个空的LinkedHashMap,指定初始容量和加载因子,排序方式
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);//父类构造器中调用了Init方法,LinkedHashMap重写了该方法
this.accessOrder = accessOrder;
}-
核心方法
图示如下:
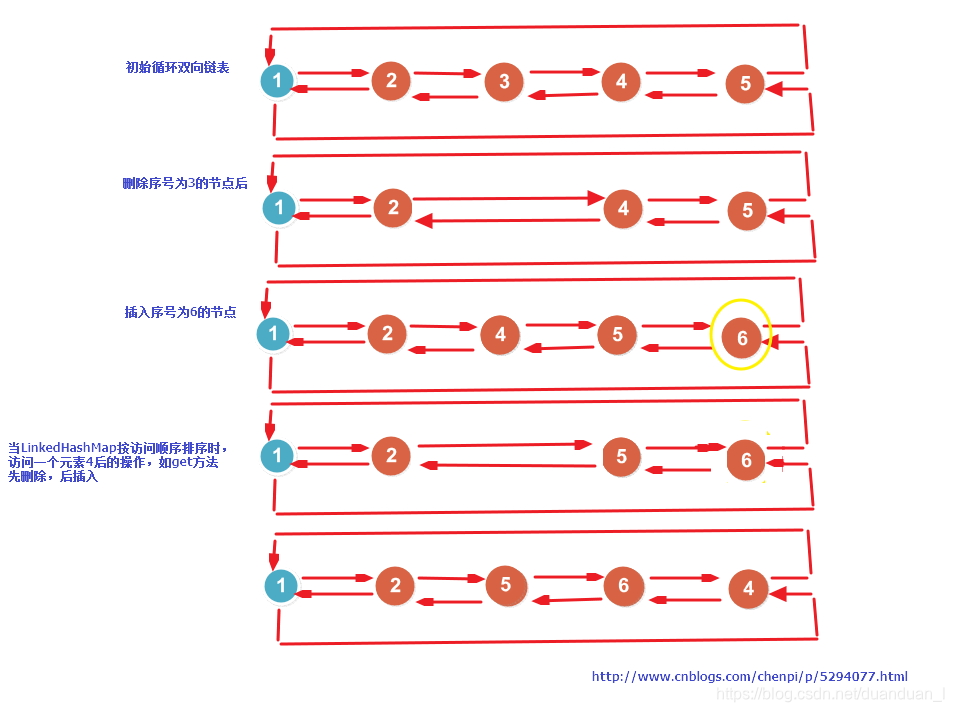
1、put方法
//HashMap的put()方法 public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this);//LinkedHashMap重写了该方法,将当前访问节点移动到尾部 return oldValue; } } modCount++; addEntry(hash, key, value, i);//否则,新插入节点 return null; } //子类重写了addEntry和createEntry方法 void addEntry(int hash, K key, V value, int bucketIndex) { super.addEntry(hash, key, value, bucketIndex);//调用父类addEntry方法 // Remove eldest entry if instructed Entry<K,V> eldest = header.after; //获取头节点的下一个节点 //判断是否需要移除最不常用的Entry if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key);//移除Entry } }//createEntry() void createEntry(int hash, K key, V value, int bucketIndex) { HashMap.Entry<K,V> old = table[bucketIndex]; //查看该索引位置是否存在元素 Entry<K,V> e = new Entry<>(hash, key, value, old); //new一个节点e,并将其下一个节点指向old; table[bucketIndex] = e; e.addBefore(header); size++; }//recordAccess() void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; //当按访问顺序排序时,先删除该节点,再将该节点插入到链表尾部(即Header的前一个节点),否则不进行任何操作 if (lm.accessOrder) { lm.modCount++; remove(); //移除当前元素 addBefore(lm.header); //将该元素加到链表尾部 } } 对访问有序做处理 //删除访问节点 private void remove() { before.after = after; after.before = before; } //将访问节点插入到头节点的前一个 private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; }
LinkedHashMap在添加元素时,调用其父类HashMap的put()方法,但不同的是LinkedHashMap重写了父类的部分方法(recordAccess方法,addEntry方法,createEntry方法等);为了形象化说明添加节点过程,请看下图:
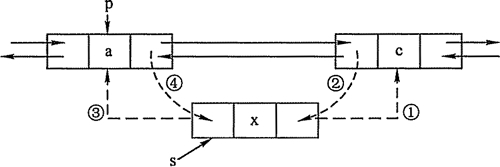
通过源码分析可以看出:LinkedHashMap的整个put过程:HashMap.put --> LinkedHashMap.addEntry --> HashMap.addEntry
--> LinkedHashMap.createEntry;
2、get()方法
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);//调用父类的getEntry()方法,得到key对应的节点
if (e == null)
return null;
e.recordAccess(this);//若accessOrder为true,将该节点放到链表尾部
return e.value;
}
//当访问有序,(accessOrder为true,才进行相关操作),(两步操作)具体操作:将访问节点移除后,添加到双链表的尾部
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
//get方法,按访问有序排序,将当前访问节点删除,然后将该节点移到链表尾部;具体操作图,举例如下:

-
特点总结:
1、LinkedHashMap允许为空;
2、数据重复问题:key不允许重复(重复进行覆盖),value可以重复;
3、数据有序:两种有序(插入有序和访问有序,主要取决于accessorder的取值);
4、LinkedHashMap是非线程安全的;

















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









