







 超级会员免费看
超级会员免费看
 本项目探讨了Q-learner在无噪声BridgeGrid环境中学习最佳策略的情况。实验涉及不同epsilon和学习率的设置,以确定是否存在一组参数,使得在50次迭代后能以超过99%的概率学到最优策略。question8()函数需返回可能的(epsilon, learning rate)对或'not possible'字符串。解答不应依赖特定的动作选择机制,确保答案在环境旋转后依然有效。"
88814691,8421682,MSP430F2274IDAR:16位超低功耗微控制器详解,"['MSP430F2274', '超低功耗微控制器', '嵌入式硬件', '微处理器架构', '16位RISC']
本项目探讨了Q-learner在无噪声BridgeGrid环境中学习最佳策略的情况。实验涉及不同epsilon和学习率的设置,以确定是否存在一组参数,使得在50次迭代后能以超过99%的概率学到最优策略。question8()函数需返回可能的(epsilon, learning rate)对或'not possible'字符串。解答不应依赖特定的动作选择机制,确保答案在环境旋转后依然有效。"
88814691,8421682,MSP430F2274IDAR:16位超低功耗微控制器详解,"['MSP430F2274', '超低功耗微控制器', '嵌入式硬件', '微处理器架构', '16位RISC']
首先,在无噪声的BridgeGrid上用默认学习率训练50次完全随机的Q-learner学习,观察是否找到最佳策略。
python gridworld.py -a q -k 50 -n 0 -g BridgeGrid -e 1
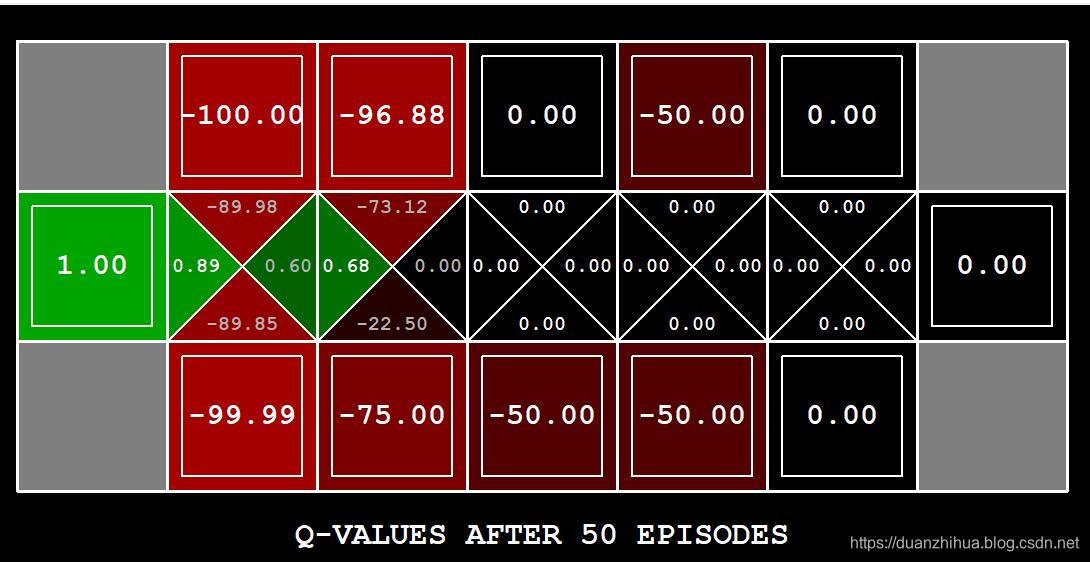
现在采用epsilon设置为0做同样的实验。是否存在一个epsilon和一个学习率,在50次迭代之后,很可能(大于99%)会学习到最佳策略?analysis.py中的question8()应返回2元组(epsilon,learning rate)或字符串“not possible”。epsilon由-e控制,学习率由-l控制。注意:您的响应不应依赖于用于选择动作的平分决胜机制。这意味着,即使我们将整个桥梁网格世界旋转90度,您的答案也应该是正确的。
要评分,请运行autograder:
python autograder.py -q q8
欢迎关注微信公众号:“从零起步学习人工智能”!


















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











