



从Flume传输数据到Kafka并读取
从Flume传输数据到Kafka并读取
- 创建八个队列信息
//users
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic users --partitions 1 --replication-factor 1
//user_friends_raw
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic user_friends_raw --partitions 1 --replication-factor 1
//user_friends
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic user_friends --partitions 1 --replication-factor 1
//events
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic events --partitions 1 --replication-factor 1
//event_attendees_raw
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic event_attendees_raw --partitions 1 --replication-factor 1
//event_attendees
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic event_attendees --partitions 1 --replication-factor 1
//train
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic train --partitions 1 --replication-factor 1
//test
[root@hadoop100 opt]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --create --topic test --partitions 1 --replication-factor 1
- 查看一下队列
[root@hadoop100 ~]# kafka-topics.sh --zookeeper 192.168.136.100:2181 --list
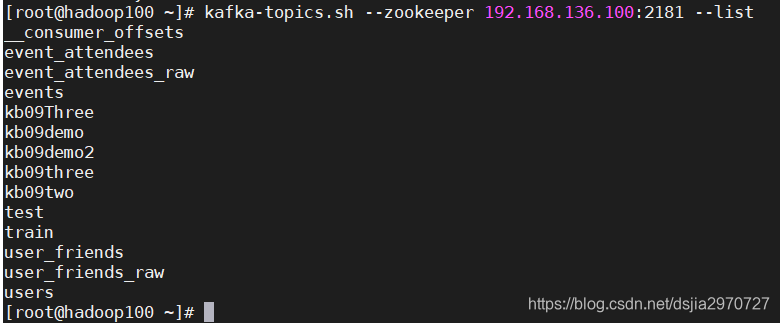
user_friends_raw
- 创建配置文件userFriend-flume-kafka.conf
userfriend.sources=userfriendSource
userfriend.channels=userfriendChannel
userfriend.sinks=userfriendSink
userfriend.sources.userfriendSource.type=spooldir
userfriend.sources.userfriendSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/userfriend
userfriend.sources.userfriendSource.deserializer=LINE
userfriend.sources.userfriendSource.deserializer.maxLineLength=320000
userfriend.sources.userfriendSource.includePattern=userfriend_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
userfriend.sources.userfriendSource.interceptors=head_filter
userfriend.sources.userfriendSource.interceptors.head_filter.type=regex_filter
userfriend.sources.userfriendSource.interceptors.head_filter.regex=^user,friends*
userfriend.sources.userfriendSource.interceptors.head_filter.excludeEvents=true
userfriend.channels.userfriendChannel.type=file
userfriend.channels.userfriendChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/userfriend
userfriend.channels.userfriendChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/userfriend
userfriend.sinks.userfriendSink.type=org.apache.flume.sink.kafka.KafkaSink
userfriend.sinks.userfriendSink.batchSize=640
userfriend.sinks.userfriendSink.brokerList=192.168.136.100:9092
userfriend.sinks.userfriendSink.topic=user_friends_raw
userfriend.sources.userfriendSource.channels=userfriendChannel
userfriend.sinks.userfriendSink.channel=userfriendChannel
- 保存退出,启动flume
[root@hadoop100 flume160]# ./bin/flume-ng agent --name userfriend ./conf/ --conf-file ./conf/jobkb09/userFriend-flume-kafka.conf -Dflume.root.logger=INFO,console
- 拷贝文件user_friends.csv文件
[root@hadoop100 tmp]# cp user_friends.csv /opt/flume160/conf/jobkb09/dataSourceFile/userfriend/userfriend_2020-12-08.csv
- 进入kafka查询topic中的数据
[root@hadoop100 opt]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.136.100:9092 --topic user_friends_raw --time -1 --offsets 1

- 从消费者拉取数据
[root@hadoop100 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.136.100:9092 --topic user_friends_raw --from-beginning
注意:数据量过大,谨慎拉取数据
users
- 创建配置文件users-flume-kafka.conf
users.sources=usersSource
users.channels=usersChannel
users.sinks=usersSink
users.sources.usersSource.type=spooldir
users.sources.usersSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/users
users.sources.usersSource.includePattern=users_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
users.sources.usersSource.deserializer=LINE
users.sources.usersSource.deserializer.maxLineLength=10000
users.sources.usersSource.interceptors=head_filter
users.sources.usersSource.interceptors.head_filter.type=regex_filter
users.sources.usersSource.interceptors.head_filter.regex=^user_id*
users.sources.usersSource.interceptors.head_filter.excludeEvents=true
users.channels.usersChannel.type=file
users.channels.usersChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/users
users.channels.usersChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/users
users.sinks.usersSink.type=org.apache.flume.sink.kafka.KafkaSink
users.sinks.usersSink.batchSize=640
users.sinks.usersSink.brokerList=192.168.136.100:9092
users.sinks.usersSink.topic=users
users.sources.usersSource.channels=usersChannel
users.sinks.usersSink.channel=usersChannel
- 保存退出,启动flume
[root@hadoop100 jobkb09]# flume-ng agent --name users /opt/flume160/conf/ --conf-file users-flume-kafka.conf -Dflume.root.logger=INFO,console
- 拷贝文件users.csv文件
[root@hadoop100 tmp]# cp users.csv /opt/flume160/conf/jobkb09/dataSourceFile/users/users_2020-12-08.csv
- 进入kafka中查询topic中的数据
[root@hadoop100 ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.136.100:9092 --topic users --time -1 --offsets 1

events
- 创建配置文件events-flume-kafka.conf
events.sources=eventsSource
events.channels=eventsChannel
events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/events
events.sources.eventsSource.deserializer=LINE
events.sources.eventsSource.deserializer.maxLineLength=10000
events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.sources.eventsSource.interceptors=head_filter
events.sources.eventsSource.interceptors.head_filter.type=regex_filter
events.sources.eventsSource.interceptors.head_filter.regex=^event_id*
events.sources.eventsSource.interceptors.head_filter.excludeEvents=true
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/events
events.channels.eventsChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/events
events.sinks.eventsSink.type=org.apache.flume.sink.kafka.KafkaSink
events.sinks.eventsSink.batchSize=640
events.sinks.eventsSink.brokerList=192.168.136.100:9092
events.sinks.eventsSink.topic=events
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
- 保存退出,启动flume
[root@hadoop100 flume160]# flume-ng agent --name events conf/ --conf-file conf/jobkb09/events-flume-kafka.conf -Dflume.root.logger=INFO,console
- 拷贝文件events.csv文件
[root@hadoop100 tmp]# cp events.csv /opt/flume160/conf/jobkb09/dataSourceFile/events/events_2020-12-08.csv
- 进入kafka中查询topic中的数据
[root@hadoop100 ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.136.100:9092 --topic events --time -1 --offsets 1

event_attendees_raw
- 创建配置文件event-flume-kafka.conf
event.sources=eventSource
event.channels=eventChannel
event.sinks=eventSink
event.sources.eventSource.type=spooldir
event.sources.eventSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/event
event.sources.eventSource.includePattern=event_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
event.sources.eventSource.deserializer=LINE
event.sources.eventSource.deserializer.maxLineLength=10000
event.sources.eventSource.interceptors=head_filter
event.sources.eventSource.interceptors.head_filter.type=regex_filter
event.sources.eventSource.interceptors.head_filter.regex=^event*
event.sources.eventSource.interceptors.head_filter.excludeEvents=true
event.channels.eventChannel.type=file
event.channels.eventChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/event
event.channels.eventChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/event
event.sinks.eventSink.type=org.apache.flume.sink.kafka.KafkaSink
event.sinks.eventSink.batchSize=640
event.sinks.eventSink.brokerList=192.168.136.100:9092
event.sinks.eventSink.topic=event_attendees_raw
event.sources.eventSource.channels=eventChannel
event.sinks.eventSink.channel=eventChannel
- 保存退出,启动flume
[root@hadoop100 flume160]# flume-ng agent --n event -c conf/ -f conf/jobkb09/event-flume-kafka.conf -Dflume.root.logger=INFO,console
- 拷贝event_attendees.csv文件
[root@hadoop100 tmp]# cp event_attendees.csv /opt/flume160/conf/jobkb09/dataSourceFile/event/event_2020-12-08.csv
- 进入kafka中查询topic中的数据
[root@hadoop100 ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.136.100:9092 --topic event_attendees_raw --time -1 --offsets 1

train
- 创建配置文件train-flume-kafka.conf
train.sources=trainSource
train.channels=trainChannel
train.sinks=trainSink
train.sources.trainSource.type=spooldir
train.sources.trainSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/train
train.sources.trainSource.includePattern=train_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
train.sources.trainSource.deserializer=LINE
train.sources.trainSource.deserializer.maxLineLength=10000
train.sources.trainSource.interceptors=head_filter
train.sources.trainSource.interceptors.head_filter.type=regex_filter
train.sources.trainSource.interceptors.head_filter.regex=^user*
train.sources.trainSource.interceptors.head_filter.excludeEvents=true
train.channels.trainChannel.type=file
train.channels.trainChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/train
train.channels.trainChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/train
train.sinks.trainSink.type=org.apache.flume.sink.kafka.KafkaSink
train.sinks.trainSink.batchSize=640
train.sinks.trainSink.brokerList=192.168.136.100:9092
train.sinks.trainSink.topic=train
train.sources.trainSource.channels=trainChannel
train.sinks.trainSink.channel=trainChannel
- 保存退出,启动flume
[root@hadoop100 flume160]# flume-ng agent --name train --conf conf/ --conf-file conf/jobkb09/train-flume-kafka.conf -Dflume.root.logger=INFO,console
- 拷贝train.csvwe文件
[root@hadoop100 tmp]# cp train.csv /opt/flume160/conf/jobkb09/dataSourceFile/train/train_2020-12-08.csv
- 进入kafka中出查询topic中的数据
[root@hadoop100 ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.136.100:9092 --topic train --time -1 --offsets 1

test
- 创建配置文件test-flume-kafka.conf
test.sources=testSource
test.channels=testChannel
test.sinks=testSink
test.sources.testSource.type=spooldir
test.sources.testSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/test
test.sources.testSource.includePattern=test_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
test.sources.testSource.deserializer=LINE
test.sources.testSource.deserializer.maxLineLength=10000
test.sources.testSource.interceptors=head_filter
test.sources.testSource.interceptors.head_filter.type=regex_filter
test.sources.testSource.interceptors.head_filter.regex=^user*
test.sources.testSource.interceptors.head_filter.excludeEvents=true
test.channels.testChannel.type=file
test.channels.testChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/test
test.channels.testChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/test
test.sinks.testSink.type=org.apache.flume.sink.kafka.KafkaSink
test.sinks.testSink.batchSize=640
test.sinks.testSink.brokerList=192.168.136.100:9092
test.sinks.testSink.topic=test
test.sources.testSource.channels=testChannel
test.sinks.testSink.channel=testChannel
- 保存退出,启动flume
[root@hadoop100 flume160]# flume-ng agent --n test -c conf/ -f conf/jobkb09/test-flume-kafka.conf -Dflume.root.logger=INFO,console
- 拷贝test.csv文件
[root@hadoop100 tmp]# cp test.csv /opt/flume160/conf/jobkb09/dataSourceFile/test/test_2020-12-08.csv
- 进入kafka查询topic中的数据
[root@hadoop100 ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.136.100:9092 --topic test --time -1 --offsets 1


















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









