






 本文详细介绍了Hive作为数据仓库工具的定义、优缺点、架构,以及与数据库的区别。深入讨论了Hive的元数据、数据类型、内部表与外部表的差异,并列举了数据加载、分区操作的方法。此外,还涵盖了Hive的窗口函数应用和性能优化策略,如MapJoin、数据倾斜处理等。
本文详细介绍了Hive作为数据仓库工具的定义、优缺点、架构,以及与数据库的区别。深入讨论了Hive的元数据、数据类型、内部表与外部表的差异,并列举了数据加载、分区操作的方法。此外,还涵盖了Hive的窗口函数应用和性能优化策略,如MapJoin、数据倾斜处理等。
系列文章目录
文章目录
hive是什么?hive的定义
Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理,Hive是通过一种类似SQL的查询语言(称为HiveSQL,简称为HQL)分析和管理数据。
hive定义:由Facebook开源用于解决海量结构化日志的数据统计
hive优缺点:
优点
1.操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2.避免了去写MapReduce,减少开发人员的学习成本。
3.Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4.Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5.Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
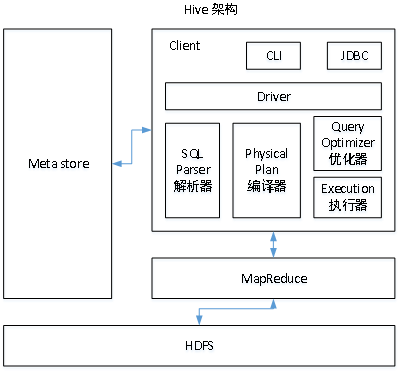
hive架构
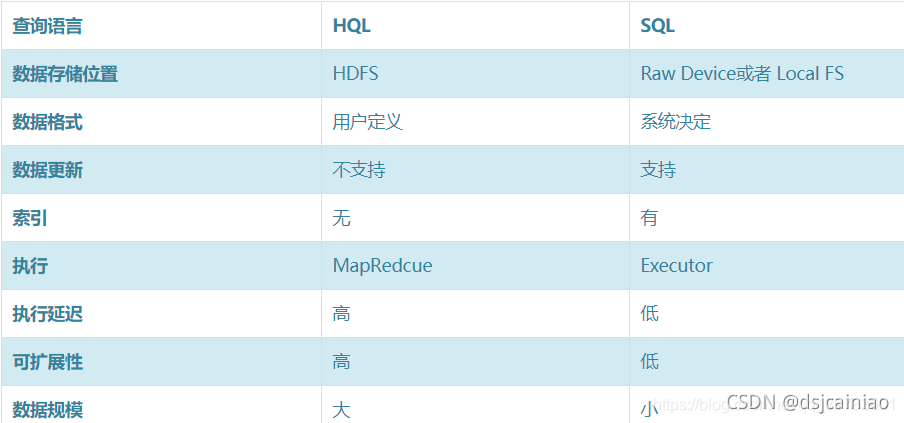
hive和数据库的区别
hive元数据包括哪些,存在哪里
1、内部表数据由Hive自身管理,外部表数据由HDFS管理;
2、内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse);
3、外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
4、未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
5、删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
6、对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
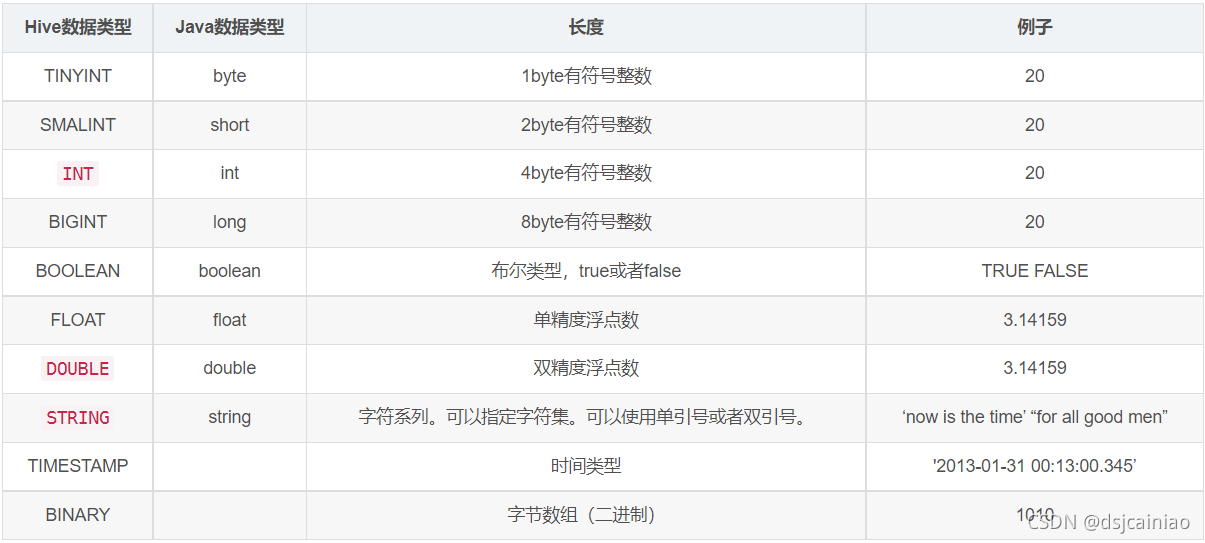
hive基本数据类型&复杂数据类型
基本数据类型
复杂数据类型

内部表外部表区别
内部表
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/opt/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
外部表
因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉
往表中添加数据的5种方式
装载,追加,覆盖
保留,插入
往分区中添加数据的三种方式
装载,追加,覆盖
建表完整语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
窗口函数
窗口函数功能
1.sum(col) over() : 分组对col累计求和
2.count(col) over() : 分组对col累计
3.min(col) over() : 分组对col求最小值
4.max(col) over() : 分组求col的最大值
5.avg(col) over() : 分组求col列的平均值
6.first_value(col) over() : 某分组排序后的第一个col值
7.last_value(col) over() : 某分组排序后的最后一个col值
8.lag(col,n,DEFAULT) : 统计往前n行的col值,n可选,默认为1,DEFAULT当往上第n行为NULL时
候,取默认值,如不指定,则为NULL
9.lead(col,n,DEFAULT) : 统计往后n行的col值,n可选,默认为1,DEFAULT当往下第n行为NULL时
候,取默认值,如不指定,则为NULL
10.ntile(n) : 用于将分组数据按照顺序切分成n片,返回当前切片值。注意:n必须为int类型
11.row_number() over() : 排名函数,不会重复,适合于生成主键或者不并列排名
12.rank() over() : 排名函数,有并列名次,名次不连续。如:1,1,3
13.dense_rank() over() : 排名函数,有并列名次,名次连续。如:1,1,2
hive的优化
压缩
行列过滤
列式储存

mapjoin
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率
数据倾斜
指的是并行处理的过程中,某些分区或节点处理的数据,显著高于其他分区或节点,导致这部分的数据处理任务比其他任务要大很多,从而成为这个阶段执行最慢的部分,进而成为整个作业执行的瓶颈,甚至直接导致作业失败。
合理设置map数,复杂文件增加Map数
当input的文件比较大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
小文件进行合并
如果一个任务有很多小文件(远远小于块大小128m),则每个小文件都会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,会造成很大的资源浪费。并且,同时可执行的map数是受限的。
合理设置Reduce数
Reduce的个数对整个作业的运行性能有很大影响。在设置reduce个数的时候需要考虑两个原则:
处理大数据量利用合适的reduce数;使单个reduce任务处理数据量大小要合适。
(1)如果Reduce设置的过大,将会产生很多小文件,对NameNode会产生一定的影响,而且整个作业的运行时间未必会减少;
(2)如果Reduce设置的过小,单个Reduce处理的数据将会加大,很可能会引起OOM(out of memory)异常。

















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









