



一、关于数据文件分隔符的问题
前言:Hive中默认使用单字节分隔符来加载文本数据,例如逗号、制表符、空格等等,默认的分隔符为\001。根据不同文件的不同分隔符,我们可以通过在创建表时使用 row format delimited fields terminated by ‘单字节分隔符’ 来指定文件中的分割符,确保正确将表中的每一列与文件中的每一列实现一一对应的关系。
但是,当分隔符为多字节分隔符(比如:'---' & '!!!' ),或者字段的数据中包含分隔符时,使用 row format delimited fields terminated by ‘单字节分隔符’ 来指定文件中的分割符就会失效,此时,就需要用特殊的办法来指定分隔符。
1-1 数据文件的分隔符为多字节分隔符
下面有一份儿数据文件,文件的分隔符为多字节分隔符 '||'

此时,如果用 row format delimited fields terminated by '||' 语句来建hive表,加载数据之后,就会查询失败。原因是:Hive中默认只支持单字节分隔符,无法识别多字节分隔符。
解决办法1:替换分隔符
如果数据中的分隔符是多字节分隔符,可以使用程序提前将数据中的多字节分隔符替换为单字节分隔符,然后使用Hive加载,就可以实现正确加载对应的数据。
例如上面的例子,原始数据中的分隔符为“||”,可以在ETL阶段通过一个MapReduce程序,将“||”替换为单字节的分隔符“|”,程序执行完成之后,分隔符为“||”就会变成自己想要的单字节分隔符。然后就可以使用常规的建表语句建表和加载数据了。
但是这种方式有对应的优缺点,并不是所有的场景适用于该方法。
优点:实现方式较为简单,基于字符串替换即可
缺点:无法解决 '数据文件某字段的数据中包含了分隔符' 这个问题
解决办法2: 自定义InputFormat
这种办法开发成本太高,所以一般不会使用。
解决办法3: RegexSerDe正则加载
Hive提供了一种特殊的Serde来加载特殊数据的问题,使用正则匹配来加载数据,匹配每一列的数据。
RegexSerde是Hive中专门为了满足复杂数据场景所提供的正则加载和解析数据的接口,使用RegexSerde可以指定正则表达式加载数据,根据正则表达式匹配每一列数据。上述遇到的问题,可以通过RegexSerDe使用正则表达式来加载实现。
用RegexSerDe解决多字节分隔符的步骤如下:
1)分析数据格式,构建正则表达式
原始数据格式
|
01||周杰伦||中国||台湾||男||七里香 |
用正则表达式定义每一列(正则表达式的写法不唯一,可以探索更高效的写法)
|
([0-9]*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*)\\|\\|(.*) |
2)正则校验(就是验证一下这个正则表达式正不正确)
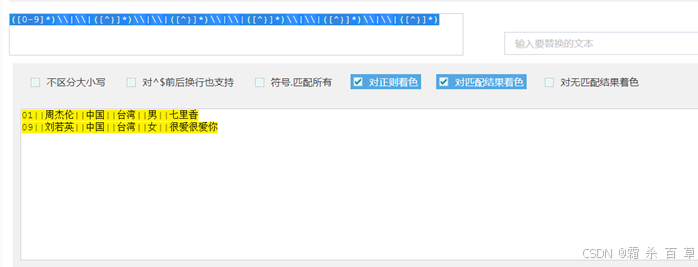
3)基于正则表达式,使用RegexSerde建表
|
--如果表已存在就删除表 drop table if exists singer; --创建表 create table singer( id string,--歌手id name string,--歌手名称 country string,--国家 province string,--省份 gender string,--性别 works string--作品 ) --指定使用RegexSerde加载数据 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' --指定正则表达式 WITH SERDEPROPERTIES ( "input.regex" = "([0-9]*)\\|\\|([^}]*)\\|\\|([^}]*)\\|\\|([^}]*)\\|\\|([^}]*)\\|\\|([^}]*)" ); |
4)加载数据
|
load data local inpath '/export/data/test01.txt' into table singer; |
5)查看数据结果,发现数据文件映射成功
|
select * from singer; |
1-2 数据文件某字段的数据中包含了分隔符
下面有一份儿数据文件,文件的分隔符为空格,但是时间字段的数据里面也包含空格
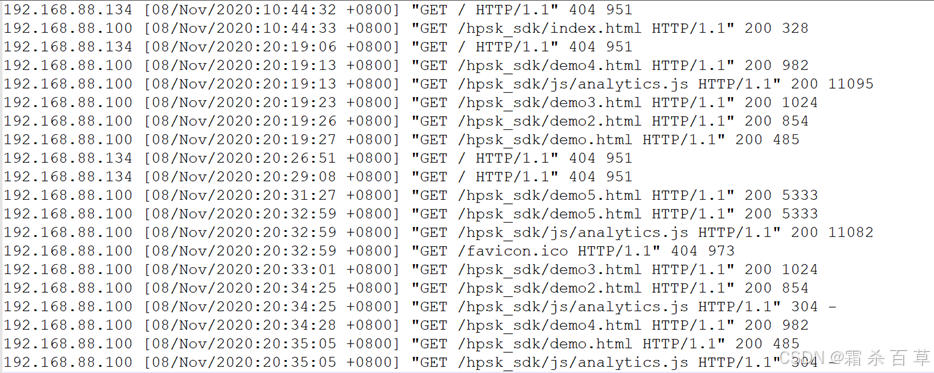
此时,如果用 row format delimited fields terminated by ' ' 语句来建hive表,加载数据之后,就会查询失败。原因是:时间数据中包含了分隔符,导致Hive认为这是两个字段,但实际业务需求中,为一个字段。
解决办法1: 自定义InputFormat
这种办法开发成本太高,所以一般不会使用。
解决办法2: RegexSerDe正则加载
Hive提供了一种特殊的Serde来加载特殊数据的问题,使用正则匹配来加载数据,匹配每一列的数据。
RegexSerde是Hive中专门为了满足复杂数据场景所提供的正则加载和解析数据的接口,使用RegexSerde可以指定正则表达式加载数据,根据正则表达式匹配每一列数据。上述遇到的问题,可以通过RegexSerDe使用正则表达式来加载实现。
用RegexSerDe解决字段数据中包含分隔符的问题步骤如下:
1)分析数据格式,构建正则表达式
原始数据格式
|
192.168.88.100 [08/Nov/2020:10:44:33 +0800] "GET /hpsk_sdk/index.html HTTP/1.1" 200 328 |
正则表达式定义每一列(正则表达式的写法不唯一,可以探索更高效的写法)
|
([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*) |
2)正则校验(就是验证一下这个正则表达式正不正确)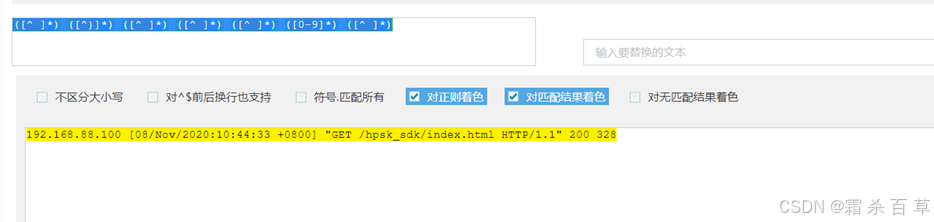
3)基于正则表达式,使用RegexSerde建表
|
--如果表存在,就删除表 drop table if exists apachelog; --创建表 create table apachelog( ip string, --IP地址 stime string, --时间 mothed string, --请求方式 url string, --请求地址 policy string, --请求协议 stat string, --请求状态 body string --字节大小 ) --指定使用RegexSerde加载数据 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' --指定正则表达式 WITH SERDEPROPERTIES ( "input.regex" = "([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)" ); |
4)加载数据
|
load data local inpath '/export/data/apache_web_access.log' into table apachelog; |
5)查看数据结果,发现数据文件映射成功
|
select ip,stime,url,stat,body from apachelog; |
1-3 关于正则表达式的一些基础解答
问题1:如何写正则表达式?
正则表达式是一种强大的字符串匹配工具,在各种编程和脚本语言中都有应用。以下是一些常见的正则表达式语法,通过这些元字符或特殊序列,可以创建复杂的匹配模式。
1. `.`:匹配任意单个字符。例如,“a.b”可以匹配"acb"、 "aab"、"adb"等。
2. `*`:匹配前面字符 0 次或多次。例如, "a*" 可以匹配 "a"、"aa"、"aaa" 或者完全不出现 "a"。
3. `+`:匹配前面的字符 1 次或多次。例如,“a+”可以匹配"a":"aa"、"aaa",但不能匹配空字符串。
4. `?`:匹配前面的字符 0 次或 1 次。例如,“a?”可以匹配 "a" 或者空字符串。
5. `{n}`、`{n,}`、`{n,m}`:分别表示匹配前面的字符恰好 n 次、至少 n 次、至少 n 次至多 m 次。例如,“a{3}”可以匹配 "aaa"。
6. `[abc]`:匹配方括号中的任意字符,例如,“[abc]”可以匹配 "a" 或 "b" 或 "c"。
7. `[^abc]`:匹配除了方括号中字符的任意字符。
8. `\d`、`\w`、`\s`:分别匹配任意数字、字母数字字符以及空白字符。
9. `\D`、`\W`、`\S`:分别匹配非数字、非字母数字字符以及非空白字符。
10. `^` 和 `$`:代表字符串的开头和结束。
11. `|`:表示或,例如 "a|b" 表示可以是 "a" 也可以是 "b"。
以校验电子邮箱地址为例,定义一个简单的电子邮箱校验的正则表达式可能如下:
regex
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
这个正则表示:字符串以一到多个数字或字母或 `.` `_` `%` `+` `-` 开头,中间有一个 `@` 符号,然后又是一到多个字母、数字或 `.` `-`,再然后是一个 `.`,最后以两个或更多的字母结尾。
问题2:同一组字符串,可以用多种正则表达式进行表示吗?
是的,同一组字符串可以被多种正则表达式表示。正则表达式的构建非常灵活,可以根据特定的需求来调整规则。例如,字符串 "12345" 可以被 "\d{5}", "[0-9]{5}", "[1-9][0-9]*" 等多种正则表达式匹配。所以,根据具体的提取或匹配需求,可以编写出多种不同的正则表达式来匹配统一组字符串。
问题3:正则校验是什么意思?
正则校验,即使用正则表达式进行数据验证。在很多情况下,我们需要检查输入数据是否满足特定的格式,例如,手机号码,邮箱地址,IP地址等等。这种情况下,正则表达式就派上了用场。
其工作原理是:你为特定数据格式编写一个正则表达式,然后将输入数据与这个正则表达式进行匹配,如果匹配成功,说明输入数据是正确的,满足要求的格式;如果匹配不成功,说明输入数据是错误的,不满足要求的格式。
问题4:将一组字符串用多种正则表达式进行表示了,如何校验正则表达式是否正确?
1)使用在线正则表达式测试工具:这类工具可以实时显示正则表达式对输入字符串的匹配结果,有助于理解和调试正则表达式。例如:Regex101、RegExr等。
2)在实际编码中进行测试:编写一些样例,包括边界情况和一般情况,看是否都能得到预期结果。异常输入也不应让程序崩溃。
3)使用IDE工具:部分集成开发环境(IDE,如 PyCharm 、IntelliJ IDEA 等)支持正则表达式语法校验和测试,可以在编写代码的同时完成。
二、URL(网址)解析函数及侧视图
2-1 什么叫做URL,构成是什么
URL(Uniform Resource Locator)定义:全称是统一资源定位器,也就是我们常说的网址。例如,一个完整的URL可以是: `https://www.example.com:8080/path/to/page?query=example#fragment` 它是互联网上用来描述信息资源位置的一种规范格式。
URL的基本组成
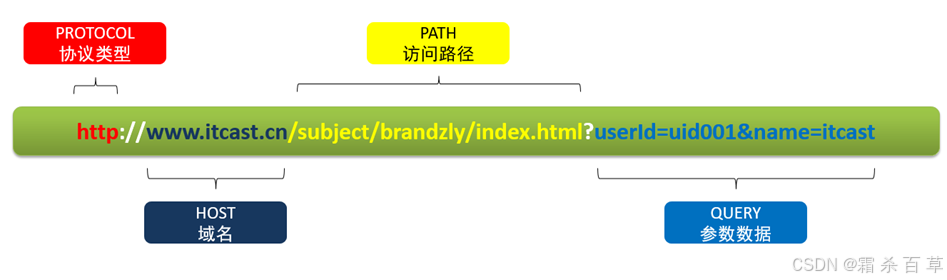
1)PROTOCOL:协议类型
通信协议类型,一般也叫作Schema,常见的有http、https等;
2)HOST:域名
一般为服务器的域名主机名或ip地址。例如www.google.com。这通常包括子域名(如www),主域名(如google),和顶级域名(如.com)。
3)PATH:访问路径
访问路径目录,由“/”隔开的字符串,表示的是主机上的目录或文件地址。
4)QUERY:参数数据
查询参数,此项为可选项,可以给动态网页传递参数,用“&”隔开,每个参数的名和值用“=”隔开
5)端口号:
这是可选的,通常在域名后面加上冒号和数字表示。例如,http://www.example.com:80。大多数情况下,80是默认的HTTP端口,443是默认的HTTPS端口,如果是这两个端口则通常会被省略。
6)片段
以"#"开头,表示网页中的一个位置。比如:www.example.com#section1,表示访问该页面的section1部分。
2-2 URL(网址)解析函数的应用场景
业务需求中,我们经常需要对用户的访问、用户的来源进行分析,用于支持运营和决策。
例如我们经常对用户访问的页面进行统计分析,分析热门受访页面的Top10,观察大部分用户最喜欢的访问最多的页面等:
又或者我们需要分析不同搜索平台的用户来源分析,统计不同搜索平台中进入网站的用户个数,根据数据进行精准的引导和精准的广告投放等:
要想实现上面的受访分析、来源分析等业务,必须在实际处理数据的过程中,对用户访问的URL和用户的来源URL进行解析处理,获取用户的访问域名、访问页面、用户数据参数、来源域名、来源路径等信息。
2-3 URL(网址)函数- parse_url
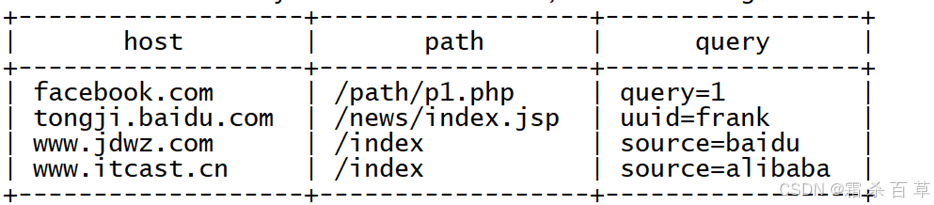
案例:在hive中创建了一个表 tb_url,表中有两个字段 id, url ,现在数据已经成功映射;需求:基于当前的数据,实现对URL进行分析,从URL中获取每个ID对应HOST、PATH以及QUERY,最终实现效果如下:

以下为表 tb_url的数据内容

2-3-1 parse_url 的功能
parse_url函数是Hive中提供的最基本的url解析函数,可以根据指定的参数,从URL解析出对应的参数值进行返回,函数为普通的一对一函数类型。
2-3-2 parse_url 的语法
parse_url(url, part To Extract[, key])
- - part To Extract参数是你要提取的 URL的哪个部分;[, key]) 是可选参数,只有在 `part To Extract` 参数值为"QUERY"时使用,用来提取特定的查询参数。
参数 `part To Extract`的可能值包括:
- `HOST`:返回 URL 的主机名
- `PATH`:返回 URL 的路径
- `QUERY`:返回 URL 的查询字符串
- `REF`:返回 URL 的碎片标识符
- `PROTOCOL`:返回 URL 的协议
- `FILE`:返回 URL 的文件名
- `AUTHORITY`:返回 URL 的授权信息
- `USERINFO`:返回 URL 的用户信息
`part To Extract` 参数值为"QUERY"时,有两种情况:
情况1:
`parse_url('http://www.example.com/path/to/page?key=value#fragment', 'QUERY')` 返回 `key=value`
情况2:
`parse_url('http://www.example.com/path/to/page?key=value#fragment', 'QUERY', 'key')` 返回 `value`
综上所述,parse_url在使用时需要指定两个参数
第一个参数:url:指定要解析的URL
第二个参数:key:指定要解析的内容
2-3-3 用parse_url 实现上述案例的需求
select
id,
parse_url(url,"HOST") as host,
parse_url(url,"PATH") as path,
parse_url(url,"QUERY") as query
from tb_url;

2-3-4 parse_url 函数的问题和不足
使用parse_url函数每次只能解析一个参数,导致需要经过多个函数调用才能构建多列,开发角度较为麻烦,实现过程性能也相对较差,需要对同一列做多次计算处理,我们希望能实现调用一次函数,就可以将多个参数进行解析,得到多列结果。
2-4 URL(网址)函数- parse_url_tuple
案例:在hive中创建了一个表 tb_url,表中有两个字段 id, url ,现在数据已经成功映射;需求:基于当前的数据,实现对URL进行分析,从URL中获取每个ID对应HOST、PATH以及QUERY,最终实现效果如下:
以下为表 tb_url的数据内容
2-4-1 parse_url_tuple 的功能
函数可以通过一次指定多个参数,从URL解析出多个参数的值进行返回多列,函数为特殊的一对多函数类型,即通常所说的UDTF函数类型。注意,`parse_url_tuple`函数可能并非所有Hive环境中都有,需要根据实际环境确保其可用性。
2-4-2 parse_url_tuple 的语法
parse_url_tuple(url, partname1, partname2, ..., partnameN)
-- partname表示要从查询字符串部分提取的查询参数的名称。 和 `parse_url` 函数一样这些部分包括:
- `HOST`: 返回 URL 的主机名
- `PATH`: 返回 URL 的路径
- `QUERY`: 返回 URL 的查询字符串
- `REF`: 返回 URL 的碎片标识符
- `PROTOCOL`: 返回 URL 的协议
- `FILE`: 返回 URL 的文件名
- `AUTHORITY`: 返回 URL 的授权信息
- `USERINFO`: 返回 URL 的用户信息
综上所述,parse_url在使用时可以指定多个参数
第一个参数:url:指定要解析的URL
第二个参数:key1:指定要解析的内容1
……
第N个参数:keyN:指定要解析的内容N
语法实例:
SELECT parse_url_tuple('http://www.example.com/path/to/page?key=value#fragment', 'HOST', 'PATH', 'QUERY', 'key');
--这个查询返回一个结构体,其中包含对应的主机名、路径以及查询字符串中 `key` 对应的值。如果没有找到对应的值,或者 URL 不合法,返回值为 `NULL`。
2-4-3 用parse_url_tuple实现上述案例的需求
情况1 select后面不跟其他原表的字段,只有parse_url_tuple函数
select parse_url_tuple(url,"HOST","PATH","QUERY") as (host,path,query) from tb_url;
情况2 select后面跟了其他原表的字段,此时就会报错,因为这个函数属于UDTF表函数类型,所以这种情况下需要配合侧视图进行使用
select id, parse_url_tuple(url,"HOST","PATH","QUERY") as (host,path,query)
from tb_url;
- - 以上命令会报错
2-4-4 用parse_url_tuple的问题
UDTF函数对于很多场景下有使用限制,例如:select时不能包含其他字段、不能嵌套调用、不能与group by等放在一起调用等等。
UDTF函数的调用方式,主要有以下两种方式:
方式一:直接在select后单独使用
方式二:与Lateral View放在一起使用
2-4 Lateral View 侧视图的使用
说明:关于侧视图的知识点,见黑马-hive学习笔记(3),里面有详细的介绍
继续沿用上面的案例,使用侧视图和parse_url_tuple 函数搭配解决问题
情况1 单个lateral view调用,实现上述需求
select
a.id as id,
b.host as host,
b.path as path,
b.query as query
from tb_url a
lateral view parse_url_tuple(url,"HOST","PATH","QUERY") b as host,path,query;
实现形式:
情况2 多个lateral view调用,实现上述需求
select
a.id as id,
b.host as host,
b.path as path,
c.protocol as protocol,
c.query as query
from tb_url a
lateral view parse_url_tuple(url,"HOST","PATH") b as host,path
lateral view parse_url_tuple(url,"PROTOCOL","QUERY") c as protocol,query;
实现形式:
三、行列转换相关场景
3-1 多行转多列
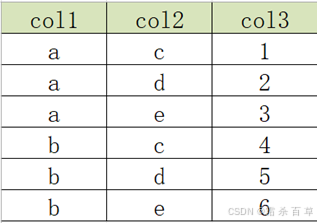
举例:原始数据表如下
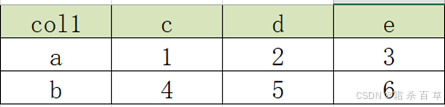
要求变为以下结构
实现步骤:(用流程控制函数可以实现,详细介绍在mysql中)
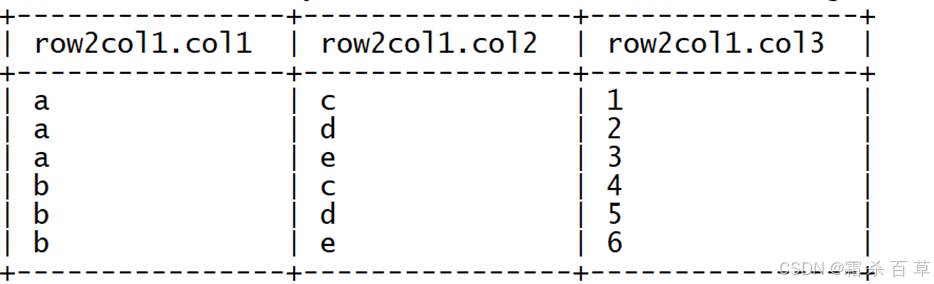
1.创建原始表 row2col1,并加载数据,结构如下
2.进行转换(流程控制函数经验绝伦的写法)
select col1 as col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'e' then col3 else 0 end) as e
from row2col1
group by col1;
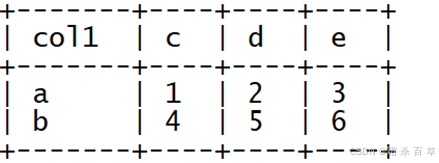
3-2 多行转单列
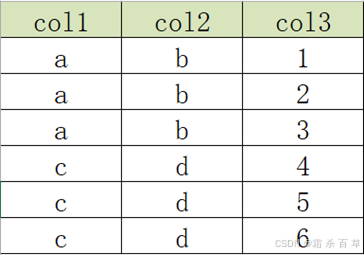
举例:原始数据表如下
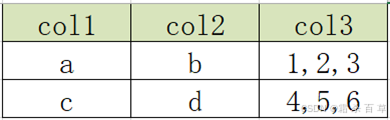
要求变为以下结构
注释:在mysql中,可以直接用group_concat函数实现这个需求,但是hive不支持这个函 数,但是hive可以用`concat_ws`和`collect_list`这两个函数的组合达到同样的效果。
实现步骤:
1.创建原始表 row2col2,并加载数据,结构如下
2.进行转换
select col1, col2,
concat_ws(',', collect_list(cast(col3 as string))) as col3
from row2col2
group by col1, col2;
--补充注释1:CAST函数在Hive中用于将一种数据类型转换为另一种数据类型。用法如下: CAST(<expression> AS <data_type>)
其中, - `<expression>` 是您要转换的字段或值。 - `<data_type>` 是您要将字段或值转换成的数据类型。
例如,如果您有一个包含数字的字符串字段,您可以使用CAST函数将其转换为整数类型,如下: SELECT CAST(string_field AS INT) FROM table;以上语句将`string_field`字段从字符串类型转换为整数类型。
--补充注释2:在Hive中,`concat`系列的函数用于连接两个或更多字符串。如果你试图直接使用该函数连接数值型数据,你可能会遇到错误。 然而,你可以使用`cast`函数先将数值转换为字符串,然后再使用`concat`函数进行连接。
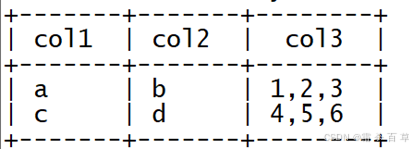
3-3 concat 家族的函数们
注意:在Hive和mysql中,concat系列的函数是用来连接两个或更多的字符串的。如果你试图传入非字符串类型的参数,比如整数或日期,那么Hive会自动将这些参数转换为字符串。
虽然允许这样做,但是如果你传入的是一些不可以被转换为字符串的更复杂类型,例如数组或结构,那么你可能会遇到错误。在这种情况下,需要使用cast函数先将其转换为字符串。
3-3-1 concat
语法: concat(string str1, string str2,...)
案例:
情况1:串联字符串
SELECT concat('Hello ', 'World'); --查询将返回 'Hello World'
情况2:串联表中的字段
SELECT concat(firstname, ' ', lastname) as fullname FROM your_table;
-- 'firstname'和'lastname'列中的值将被拼接成一个新的"fullname"列,两个名字之间有一个空格字符。
注意事项:如果任意一个元素为null,结果就为null
select concat("it","cast","And",null); --结果返回 null
3-3-2 concat_ws
语法: concat_ws(string delimiter, string str1, string str2...)
--"delimiter"是连接字符串的分隔符,"str1"、"str2"等是要连接的字符串。
案例:
情况1:串联字符串
SELECT concat_ws(',', 'Hello', 'World'); --查询将返回 'Hello,World'。
情况2:串联表中的字段
SELECT concat_ws(' ', firstname, lastname) as fullname FROM your_table;
--将会将'firstname'和'lastname'列的值用空格连接起来,形成一个新的'fullname'列。
情况3:串联字符串中包含null时
SELECT concat_ws('-', 'Hello', NULL, 'World');
--这个查询将返回 'Hello--World',注意这里有两个连起来的破折号,表示中间存在一个空字符串。
3-3-3 collect_list
功能:用于将一列中的多行合并为一行,不进行去重
1)`collect_list`函数仅能接受一个字段作为参数。这个函数会把同一分组内同一列的所有值收集到一个列表中。如果你需要收集多个字段的值,你需要为每个字段单独调用`collect_list`。2)`collect_list`函数返回的结果是一个数组,数组中的元素之间以逗号(`,`)分隔。而在结果的展示上,整个数组以方括号(`[]`)包围,数组中的元素以逗号和空格分隔。
语法:collect_list(colName) --colName是字段名称
案例:
select collect_list(col1) from row2col1;
输出:["a","a","a","b","b","b"]
3-3-4 collect_set
功能:用于将一列中的多行合并为一行,并进行去重
语法:collect_set(colName) --colName是字段名称
案例:
select collect_set(col1) from row2col1;
输出:["b","a"]
3-4 多列转多行
解决办法:用union all 连接关键字
案例:目标表如下
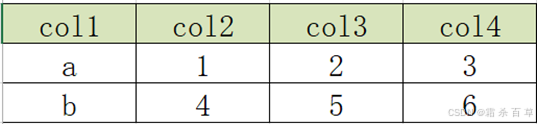
需要改成目标结果表格式
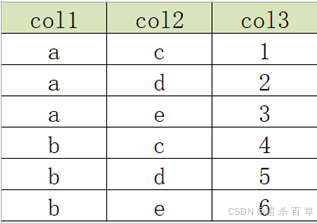
实现方法:
步骤1:建立原表col2row1,加载数据
步骤2:转换格式
|
select col1, 'c' as col2, col2 as col3 from col2row1 |
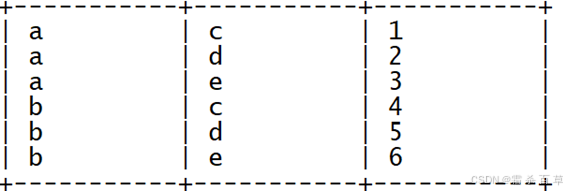
3-4 单列转多行
使用 explode 爆炸函数进行解决,关于此函数的详细说明见 学习笔记(3)
案例:原始数据表结构如下
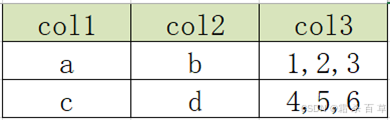
现在需要变成以下结构
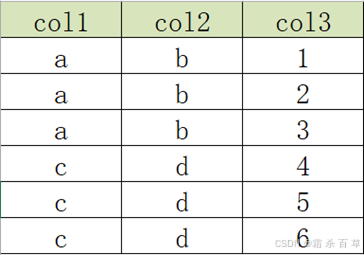
实现方式:
步骤1:创建原始数据表col2row2,加载数据
步骤2:转换格式
|
select |

四、JSON数据处理
4-1 什么叫JSON格式的数据
JSON格式属于半结构化数据类型。在JSON中,数据被表示为键值对的集合。它既包含了结构(通过键值对表示),也包含了一些不规则的数据(比如,值可以是数组或另一个键值对集合),这就是为什么它被称为半结构化数据。通常,JSON格式的数据的结构是很复杂的,所以就需要我们对其进行处理,把它变成多列常规的数据格式,增加可读性。
注意:在处理JSON格式的数据文件时,会有两种方式;一种是先将数据文件按照正常的语句加载到hive表中,然后再用专门处理JSON的函数对其进行解析;另外一种是建表的时候使用JSON对应的serde,这样在数据加载之后,就会自动在表中解析完成。
4-2 应用场景
JSON数据格式是数据存储及数据处理中最常见的结构化数据格式之一,很多场景下公司都会将数据以JSON格式存储在HDFS中,当构建数据仓库时,需要对JSON格式的数据进行处理和分析,那么就需要在Hive中对JSON格式的数据进行解析读取。
4-3 解析JSON数据格式的方式
4-3-1 使用JSON函数:get_json_object 解析
1)功能: 用于解析JSON字符串,可以从JSON字符串中返回指定的某1个对象列的值
2) 语法:
`get_json_object` 是 Hive 中的内置函数,用于从 JSON 格式的字符串中获取指定键的值。
此函数主要接收两个参数:第一个参数为 JSON 格式的字符串(通常是表中的一个字段),第二个参数为需要获取值的键名,键名需以 `$` 符号开始。 函数的基本语法为:
get_json_object(string json_string, string path)
3)举例:
假设我们有一个表 `persons`,其中有一个 `info` 列,保存了 JSON 格式的字符串,数据如下:

我们想获取每个人的年龄,就能使用 `get_json_object` 函数,查询语句如下:
SELECT name, get_json_object(info, '$.age') as age FROM persons;
执行结果会是:

在这个例子中,`get_json_object` 函数从 `info` 列(一个包含 JSON 格式数据的字符串)中获取 "age" 键的值。
4)特点:
每次只能返回JSON对象中某一列键的值(一个json数据字段中可能包含多个键值对)
4-3-2 使用JSON函数:json_tuple 解析
1)功能:
用于实现JSON字符串的解析,可以通过指定多个参数来解析JSON返回多列的值
2)语法:
`json_tuple`函数是Hive中的内置函数,用于从JSON格式的字符串中提取多个字段的值。它接收一个JSON字符串作为第一个参数,然后接收一个或多个要提取的字段的名称。
函数的基本语法为:
json_tuple(string json_string, string col1, string col2, ...)
3)例子
假设我们有一个表`persons`,其中有一个`info`列,保存了JSON格式的字符串,数据如下:

我们想获取每个人的年龄和性别,便可以使用`json_tuple`函数,查询语句如下:
SELECT name, json_tuple(info, 'age', 'gender') as (age, gender) FROM persons;
执行结果会是:

在这个例子中,`json_tuple`函数从`info`列(一个包含JSON格式数据的字符串)中获取 "age" 和 "gender" 字段的值。需要注意的是,当字段不存在时,`json_tuple`函数会返回NULL。
4)特点
- 功能类似于get_json_object,但是可以调用一次返回多列的值。属于UDTF类型函数(表函数)
- 返回的每一列都是字符串类型
- 一般搭配lateral view使用
4-3-3 使用 JSONSerde
上述解析JSON的过程中是将数据作为一个JSON字符串加载到表中,再通过JSON解析函数对JSON字符串进行解析,灵活性比较高,但是对于如果整个文件就是一个JSON文件,在使用起来就相对比较麻烦。Hive中为了简化对于JSON文件的处理,内置了一种专门用于解析JSON文件的Serde解析器,在创建表时,只要指定使用JSONSerde解析表的文件,就会自动将JSON文件中的每一列进行解析。
注意:JSONSerde不需要额外指定分隔符,系统会自动处理
例如:
create table tb_json_test2 (device string, deviceType string, )
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
总结:不论是Hive中的JSON函数还是自带的JSONSerde,都可以实现对于JSON数据的解析,工作中一般根据数据格式以及对应的需求来实现解析。如果数据中每一行只有个别字段是JSON格式字符串,就可以使用JSON函数来实现处理,但是如果数据加载的文件整体就是JSON文件,每一行数据就是一个JSON数据,那么建议直接使用JSONSerde来实现处理最为方便。
4-4 例子
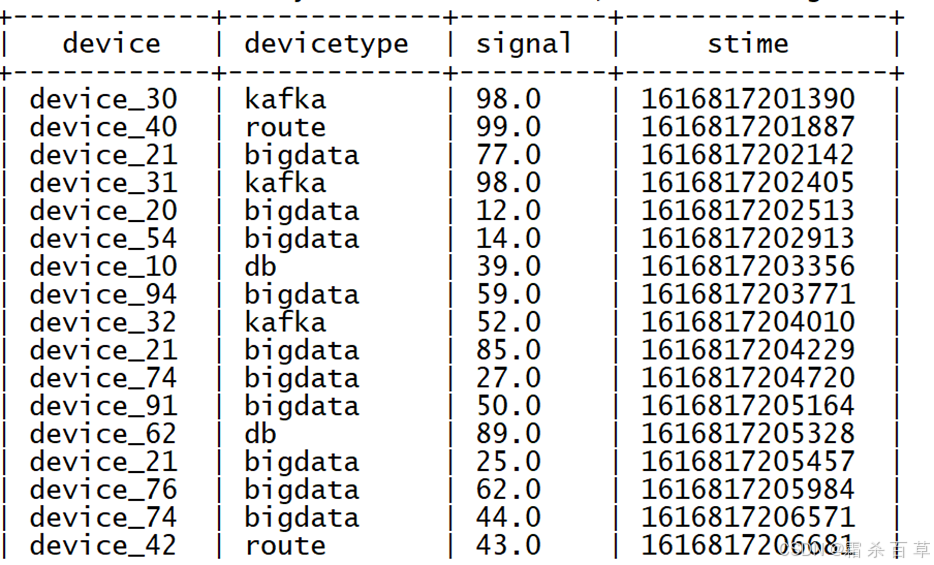
以下为一个JSON格式的数据,

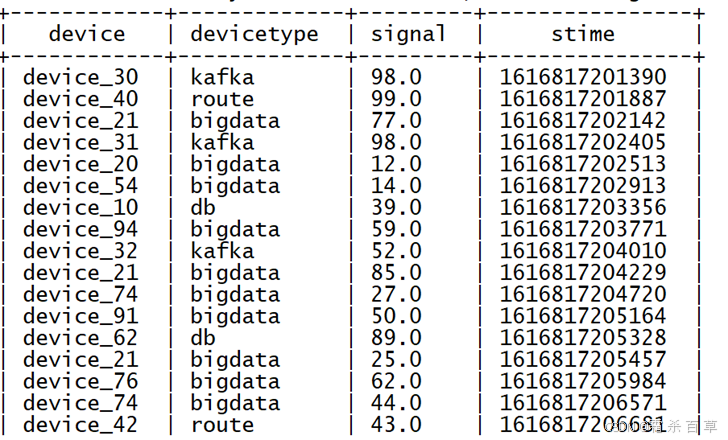
需求:以上每条数据都以JSON形式存在,每条数据中都包含4个字段,分别为设备名称【device】、设备类型【deviceType】、信号强度【signal】和信号发送时间【time】,现在我们需要将这四个字段解析出来,在Hive表中以每一列的形式存储,最终得到以下Hive表:
实现方式
实现方式1 使用 get_json_object 函数
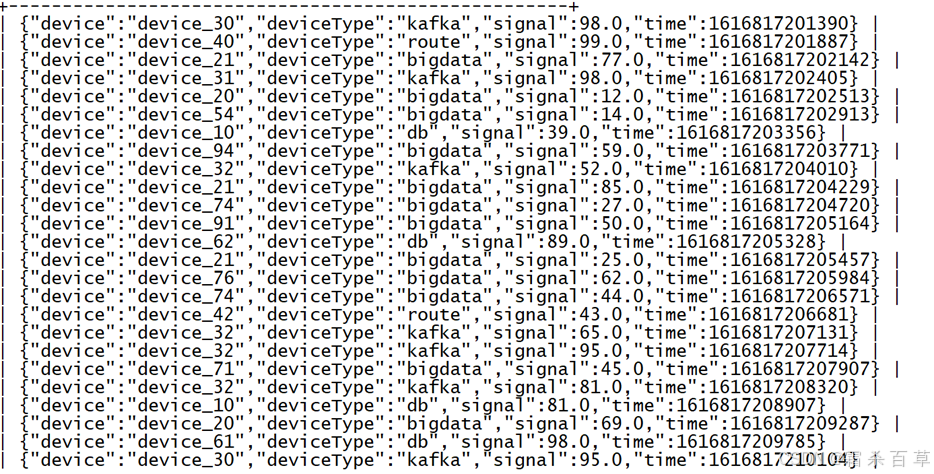
步骤 1:创建普通表,将数据文件加载上去;表中的内容如下所示
create table tb_json_test1 ( json string);
步骤2 实现需求
|
select |
实现方式2 使用 json_tuple 函数
步骤 1:创建普通表,将数据文件加载上去;表中的内容如下所示
create table tb_json_test1 ( json string);
步骤 2:实现需求
情况1:不搭配侧视图使用
|
select |
情况2:搭配侧视图使用,会比上面那种情况多一个字段json
|
select |
实现方式3 使用 Hive内置的JSON Serde加载数据
create table tb_json_test2 ( device string, deviceType string, signal double, `time` string
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
- - 直接用JSON对应的 Serde建表,建完之后load data (local)正常加载数据;此时,这份儿json数据文件加载完成
- - JSONSerde不需要额外指定分隔符,系统会自动处理
五、拉链表的应用
5-1 拉链表的应用场景
案例:实际工作中,hive需要定期的从各种数据源中同步采集数据到Hive中,经过分层转换提供数据应用。例如,每天需要从MySQL中同步最新的订单信息、用户信息、店铺信息等到数据仓库中,进行订单分析、用户分析。
MySQL中有一张用户表:tb_user,每个用户注册完成以后,就会在用户表中新增该用户的信息,记录该用户的id、手机号码、用户名、性别、地址等信息。
每天都会有用户注册,产生新的用户信息,我们每天都需要将MySQL中新增的用户数据同步到Hive数据仓库中,以便后续的分析。
这个时候就会涉及到数据同步的问题
在实现数据仓库数据同步的过程中,我们必须保证Hive与MySQL中的数据是一致的。这里会面临一个问题:如果MySQL中除了新增数据外,原有的数据发生了修改,那么Hive中如何存储被修改的数据?
例如以下的情况
2021-01-01:MySQL中有10条用户信息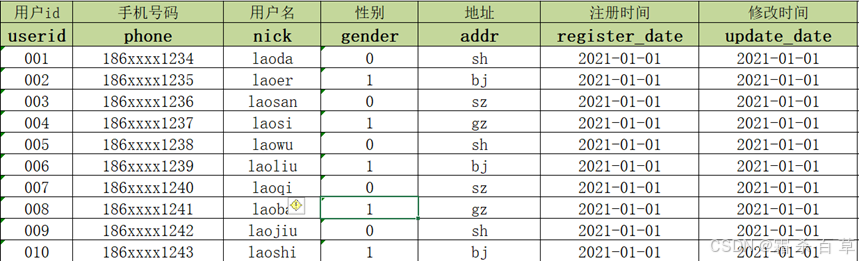
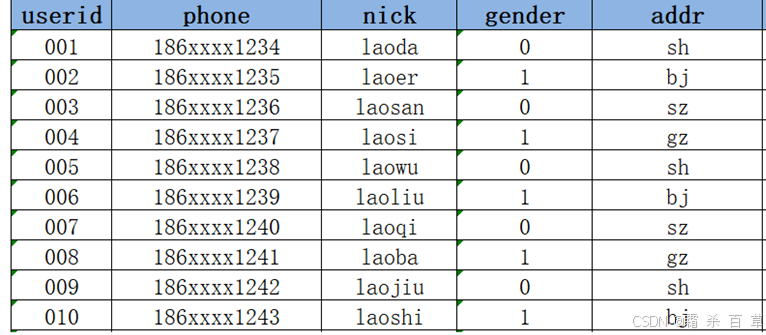
2021-01-02:Hive进行数据分析,将MySQL中的数据同步
2021-01-02:MySQL中新增2条用户注册数据,并且有1条用户数据发生更新
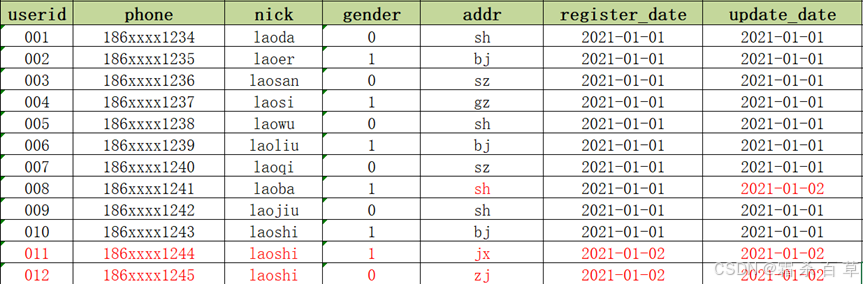
1)新增两条用户数据011和012
2)008的addr发生了更新,从gz更新为sh
2021-01-03:Hive需要对2号的数据进行同步更新处理
这样的话,问题来了,新增的数据可以直接加载到Hive表中,但是更新的数据如何存储在Hive表中?
方案1:在Hive中用新的addr覆盖008的老的addr,直接更新
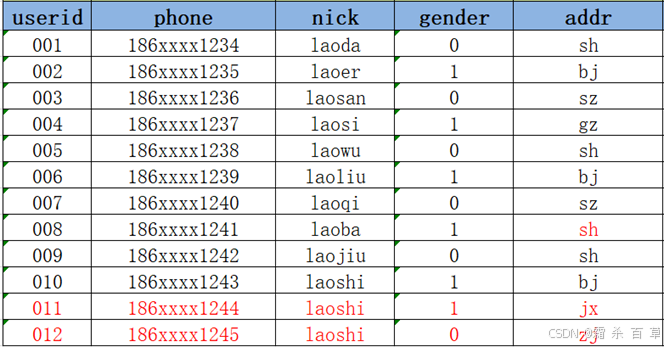
- 优点:实现最简单,使用起来最方便
- 缺点:没有历史状态,008的地址是1月2号在sh,但是1月2号之前是在gz的,如果要查询008的1月2号之前的addr就无法查询,也不能使用sh代替
方案2:每次数据改变,根据日期构建一份全量的快照表,每天一张表
- 优点:记录了所有数据在不同时间的状态
- 缺点:冗余存储了很多没有发生变化的数据,导致存储的数据量过大
方案3:构建拉链表,通过时间标记发生变化的数据的每种状态的时间周期(和之前的方案比较,数据表中多了两个时间字段)
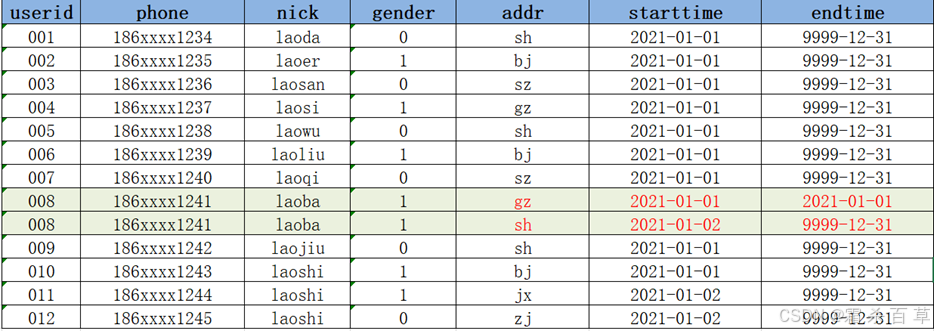
5-2 拉链表的设计与实现
5-2-1 拉链表的应用场景
拉链表专门用于解决在数据仓库中已有数据发生变化如何实现数据存储的问题,如果直接覆盖历史状态,会导致无法查询历史状态,如果将所有数据单独切片存储,会导致存储大量非更新数据的问题。拉链表的设计是将更新的数据进行状态记录,没有发生更新的数据不进行状态存储,用于存储所有数据在不同时间上的所有状态,通过时间进行标记每个状态的生命周期,查询时,根据需求可以获取指定时间范围状态的数据,默认用9999-12-31等最大值来表示最新状态。
5-2-2 拉链表的实现过程
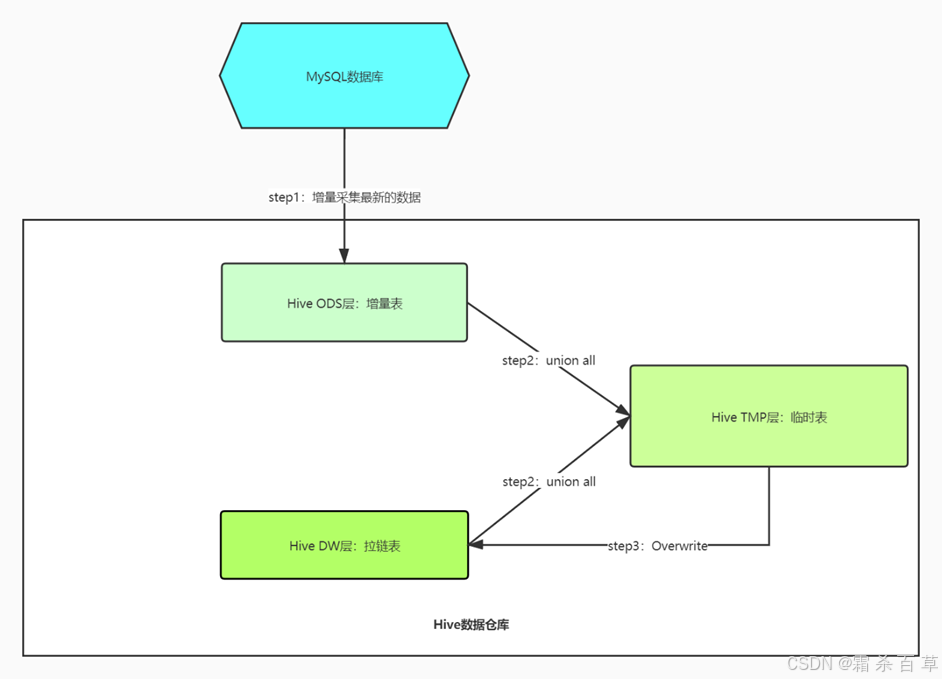
整体实现过程一般分为三步,第一步先增量采集所有新增数据【包括增加的数据和发生变化的数据这两部分】放入一张增量表。第二步创建一张临时表,用于将老的拉链表与增量表进行合并。第三步,最后将临时表的数据覆盖写入拉链表中。
总结下来,其实拉链表之所以叫拉链表,是因为他比普通的表多了两列,一列是数据行的开始时间,一列是数据行的截止时间。这样就能够查看每条修改记录的截止时间了。
举例:
当前MySQL中的数据:
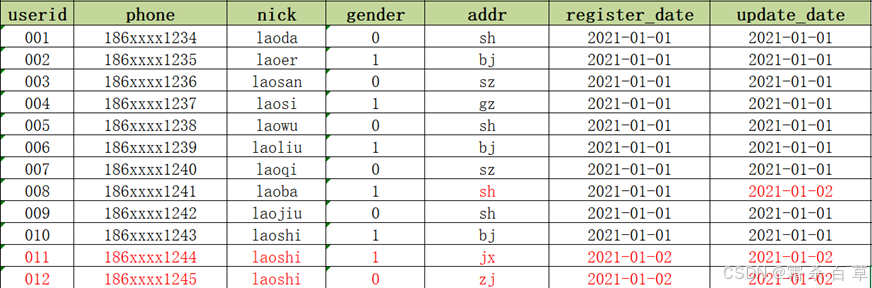
当前Hive数据仓库中拉链表 dw_zipper 的数据:
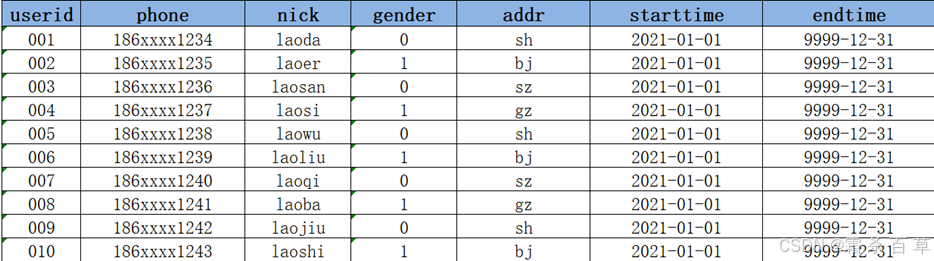
- step1:增量采集变化数据,放入增量表 ods_zipper_update 中

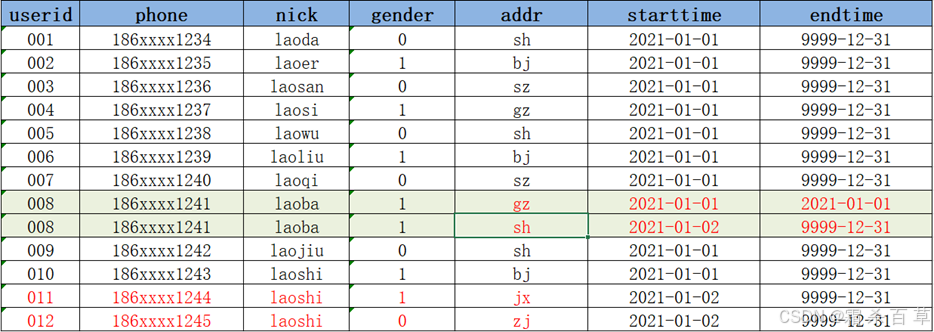
- step2:构建临时表 tmp_zipper ,将Hive中的拉链表与临时表的数据进行合并;语法如下(注意:修被修改的数据行需要跟新截止时间)
|
insert overwrite table tmp_zipper |
- step3:将临时表的数据覆盖写入拉链表中
|
insert overwrite table dw_zipper |

















 5577
5577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









