




一、什么叫DDL语法?
数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database(schema)、table、view、index等。核心语法由CREATE、ALTER与DROP三个所组成。DDL并不涉及表内部数据的操作。
二、Hive完整的建表语法树
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db name.]table_name
[(col_name data_type [COMMENT col_comment], ... ]
[COMMENT table_comment]
[PARTITIONED BY (col name data_type [COMMENT col comment], ...)]
[CLUSTERED BY (col_name, col_name, ..) [SORTED BY (col_name [ASC|DESC,..)]
[lNTO num_buckets BUCKETSI]
[ROW FORMAT DELIMITED|SERDE serde _name WITH SERDEPROPERTiES (property_name=property_value...)]
[STORED AS file format]
[LOCATlON hdfs_path]
[TBLPROPERTES (property_name=property_value...)];
- 红色字体是建表语法的关键字,用于指定某些功能。
- []中括号的语法表示可选。
- |表示使用的时候,左右语法二选一。
- 建表语句中的语法顺序要和上述语法规则保持一致。
- 说明:TEMPORARY(temporary,指临时表。它的生命周期仅仅在当前的Hive会话中,当会话关闭时(Hive客户端连接被关闭或者退出),临时表就会自动地被删除。临时表通常用于存储一些中间结果,对于一些复杂的查询操作,可以首先将中间结果生成为临时表,然后基于临时表进行后续的查询,可以提高查询的效率。)EXTERNAL(外部表)IF NOT EXISTS(它是一个条件判断语句。如果使用"IF NOT EXISTS",那么在表或数据库已经存在的情况下,该CREATE语句就不会执行,也就是说它不会改变原有的表或数据库,也不会报错。而如果不使用"IF NOT EXISTS",在表或数据库已经存在的情况下,尝试再次创建会导致错误。 )
三、Hive中的数据类型
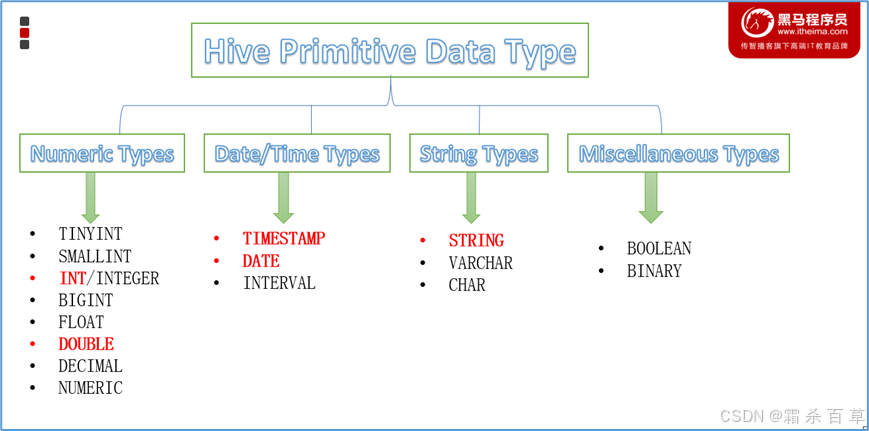
1.hive有哪些数据类型
Hive数据类型整体分为两个类别:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
原生数据类型包括:数值类型、时间类型、字符串类型、杂项数据类型;
复杂数据类型包括:array数组、map映射、struct结构、union联合体。
关于Hive的数据类型,需要注意:
- 英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如:string;
- int和string是使用最多的,大多数函数都支持;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用。
- 如果定义的数据类型和文件不一致,hive会尝试隐式转换,但是不保证成功。
2.原生数据类型
(1)整数型:
a. TINYINT(tinyint): 1字节有符号整数,范围-128 ~ 127。
b. SMALLINT(smallint): 2字节有符号整数,范围-32,768 ~ 32,767。
c. INT(int): 4字节有符号整数,范围-2,147,483,648 ~ 2,147,483,647。
d. BIGINT(bigint): 8字节有符号整数,范围-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807。
(2)浮点型:
a. FLOAT(float): 单精度浮点数。
b. DOUBLE(double): 双精度浮点数。
(3)定长字符串型:
a. STRING(string)
(4)时间戳型:
a. TIMESTAMP(timestamp)
(5)布尔型:
a. BOOLEAN(boolean)
在实际应用中,最常使用的通常是INT、BIGINT、FLOAT、DOUBLE和STRING。
 引申:数据类型中的字节是什么意思?
引申:数据类型中的字节是什么意思?
答:在Hive中,数据类型的字节表示用于存储该类型数据所需要的空间大小。比如,"TINYINT"类型需要1字节的存储空间,"INT"类型需要4字节等。
在计算机中,数据被存储为二进制位(bit),而1字节(byte)等于8位。比如,"TINYINT"类型需要1字节,也就是8位,可以表示2^8=256个不同的值,由于是有符号的整数(可以为正或为负),所以其取值范围是-128到127。这种定义可以帮助我们理解不同数据类型的存储需求和取值范围,以便我们在设计表结构和选择数据类型时,可以根据具体需求来选择合适的数据类型,优化存储空间。
3.复杂数据类型
3-1 hive支持哪些复杂数据类型
复杂数据类型是什么:
是指由基础数据类型(如整型、浮点型、布尔型和字符串类型等)组合而成的更复杂的数据类型。这种数据类型可以用来存储和处理更复杂的数据结构。
常用的复杂数据类型:
(1)数组(ARRAY):数组是有序的元素集合。在Hive中,数组的元素可以是任何数据类型,包括复杂数据类型。例如,有一个ARRAY<int>类型的列,名为"numbers",数据如下: `{1,2,3,4,5}` 这是一个整型数组,花括号内的是数组中的元素,由逗号分隔。
(2)映射(MAP):映射是无序的键-值(key-value)对集合。例如一个MAP<STRING, INT>类型的列,如"name_age_map",数据如下: `{"John":30, "Mike":40}` 这是一个字符串到整数的映射,其中"John"和"Mike"是键,30和40是相应的值,花括号{}包围整个映射,键和值之间用冒号分隔,不同的键值对之间用逗号分隔。
(3)结构体(STRUCT):结构体是一种包含命名字段的数据类型,每个字段可以有不同的类型。例如,有一个STRUCT<name: STRING, age: INT>类型的列,数据如下: `{"name":"John", "age":30}` 这是一个结构体,有一个"name"字段和一个"age"字段,":"用于分隔字段名和值,不同字段间用逗号分隔,花括号{}包围整个结构体。
3-2 hive如何创建有复杂类型数据的表?
答:创建复杂类型数据的字段需要用特定的函数ARRAY、MAP、STRUCT。
下图为建复杂类型数据字段涉及到的代码,注意,不同类型的复杂数据用到的代码会有区别。

(1)创建数组(Array) 类型数据的表:
CREATE TABLE tablename (int_array ARRAY<int>);
其中,ARRAY<int>表示int_array字段是一个整型数组。
案例:
CREATE TABLE test_array ( id INT, numbers ARRAY<INT>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
这段代码表达的含义是: 创建一个名为 test_array 的表,该表具有两个字段,id和numbers。其中,id是整数类型,而numbers是一个数组。在这个数组中,每个元素都是整数类型。 行格式被定义为分隔的,字段之间是用制表符('\t')分隔的,数组内的元素之间则是用逗号(',')分隔的。
注意:ARRAY<INT> 表示数组中的每个元素都是 INT 类型。您可以更改 <INT> 为任意其他您需要的数据类型。
(2)创建映射(Map)类型数据的表:
CREATE TABLE tablename (string_int_map MAP<STRING, INT>);
其中,MAP<STRING, INT>表示string_int_map字段是一个由字符串映射到整数的映射,字符串为此映射的键,整数为值。
案例:
CREATE TABLE test_map ( id INT, mapping MAP<STRING, INT> )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ':'
MAP KEYS TERMINATED BY ',';
这段代码表达的含义是: 创建一个名为 test_map 的表,该表有两个字段 - id和mapping。其中,id是整数类型,mapping是一个映射字段,其键值是字符串,值为整型。 行格式被定义为分隔的,字段之间是用制表符('\t')分隔的,映射字段的键值对之间是用逗号(',')分隔的,并且映射的键和值之间用冒号(':')分隔。
让我们看一个具体的示例。假设我们有这样一条记录:
1 jack:20,jill:22,bob:25
这条记录将在 test_map 表中表示为:
id = 1 mapping = {"jack" : 20, "jill" : 22, "bob" : 25}
(3)创建结构体(Struct)类型数据的表:
CREATE TABLE tablename (person_info STRUCT<name:STRING, age:INT>);
其中,STRUCT<name:STRING, age:INT>表示该person_info字段是一个结构体,该结构体有两个字段:字符串类型的name字段和整数类型的age字段。
案例:
CREATE TABLE test_struct ( id INT, details STRUCT<name: STRING, age: INT> )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
这段代码的意义是: 创建一个名为 test_struct 的表,该表有两个字段 - id和details。其中,id 是整数类型,details 是一个结构体字段,结构体内包含 name 和 age 两个字段,name 是字符串类型,age 是整数类型。 行格式被定义为分隔的,字段之间用制表符 ('\t') 分隔,结构体中的项用逗号 (',') 分隔。
让我们考虑一个具体的例子:
假设我们有这样一条记录:
1 john,25
对于 test_struct 表,这条记录将表示为:
plaintext id = 1 details = { "name" : "john", "age" : 25 }
3-3 hive中,如何读取(查询)复杂类型的数据?
答:对于复杂数据类型(例如数组、映射或结构体类型),需要使用特殊的语法来访问它们。
例子:我在hive中有一张表 ceshi_6 , select * from ceshi_6 结果如下:相当于有4个字段(原生数据类型,数组,结构体,映射)--注:结构体&映射可以有多个键值对,用分隔符分开就行。

(1)数组:通过数组索引访问的,数组索引从 0 开始
SELECT id, numbers[0] FROM test_array;
--返回表 test_array 中 id 和 numbers 数组的第一个元素。
SELECT id, size(numbers) FROM test_array;
-- 这将返回数组的大小
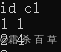
例1:SELECT id,int_array[0] FROM ceshi_6; 结果如下
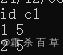
例2:SELECT id,size(int_array) FROM ceshi_6; 结果如下
(2)Map:使用键来访问。
SELECT id, mapping['key'] FROM test_map;
--这将返回表 test_map 中 id 和 mapping 映射中键为 'key' 的元素。
SELECT id, size(mapping) FROM test_map;
-- 这将返回映射中的键值对数
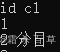
例1:SELECT id,string_int_map['地方'] FROM ceshi_6; 结果如下
例2:SELECT id, string_int_map['地方'] ,string_int_map['情况'] FROM ceshi_6; 结果如下
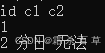
例3:SELECT id,size(string_int_map) FROM ceshi_6; 结果如下
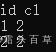
(3)Struct:使用"."来访问。
SELECT id, details.name FROM test_struct;
--这将返回表 test_struct 中的 id 和 details 结构中的 name 字段。
例:SELECT id, person_info.name, person_info.grade FROM ceshi_6; 结果如下
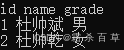
请注意,这些查询返回的结果仍然是表格式的,即使查询的是数据的子集。用这种方式,你可以在 Hive 中查询复杂数据类型的特定部分,这是 Hive 它的一大优点。某些复杂数据类型可能包含其他复杂类型的元素 (例如,你可能有一个 ARRAY of STRUCT 或一个 STRUCT of ARRAY),对于这种情况,只需将上述访问复杂数据类型的语法组合起来即可,可以使用子查询的方式。
3-4 原生数据类型的隐式、显式转换
问题1:什么叫窄类型&宽类型数据?(大数据领域的概念,宽泛型的定义)
答:窄类型数据(Narrow data)为长格式,是指具有较大数量行,但较小数量列的数据。例如, 你可能有一个包含千万人姓名的数据,只剩下两列:ID和名字。 宽类型数据为宽格式,此类型数据拥有较少的行但是大量的列。例如,一个包含几十个观测值,但是每个观测值都有几千个变量。在很多情况下,需要将数据从宽类型转换为窄类型,或者反过来,以便在数据分析和数据可视化中使用。
问题2:hive中的数据类型从窄到宽是什么?
答:在Hive中的原生数据中,数据类型从窄到宽的顺序是:
1. TINYINT: 1 字节整型,取值范围为 -128 到 127。
2. SMALLINT: 2 字节整型,取值范围为 -32768 到 32767。
3. INT: 4 字节整型,取值范围为 -231 到 231-1。
4. BIGINT: 8 字节整型,取值范围为 -263 到 263-1。
5. FLOAT: 单精度 32 位 IEEE 754 浮点数。
6. DOUBLE: 双精度 64 位 IEEE 754 浮点数。
7. DECIMAL: Hive 0.11.0 开始开始提供的精确的数值数据类型,用户可以指定总的位数和小数位数。适用于需要精确计算的领域。
8. TIMESTAMP: 时间戳类型,精确到毫秒。
9. DATE: 日期类型,格式为:YYYY-MM-DD。
10. STRING: 字符串类型,用于包含字母、数字等的文本,字符数限制主要由内部存储和处理能力决定。
11. VARCHAR: Hive 0.12.0 开始提供的变长字符串,用户可以指定字符串的最大长度。
12. CHAR: Hive 0.13.0 开始提供的定长字符串,用户可以指定字符串的长度。
13. BOOLEAN: 用于表示 true 或 false 的逻辑类型。
问题3:hive中允许的数据类型转换?
答:从窄到宽,数据类型的取值范围是增大的,窄的数据类型可以无损地转换为较宽的数据类型。而从较宽的数据类型向较窄的数据类型进行转换,可能会导致数据溢出或精度损失。
原生类型从窄类型到宽类型的转换(即隐式转换),是指更小范围的类型(如整型)自动转换为更大范围的类型(如长整型),系统可以自动完成这种转换,无需用户进行手动操作。比如你可以将一个Int类型的字段值赋给一个BIGINT类型的变量,系统不会报错,并且这种转换通常不会有信息丢失。
反过来,如果你尝试将一个宽类型转换为窄类型(即显式转换),比如将BIGINT转换为Int,由于BIGINT类型的取值范围比Int类型大,如果数值超过了Int类型的取值范围,就可能导致数据溢出,因此Hive默认不允许这种转换。 也就是说,这句话的意思是,Hive中在默认情况下只允许原生类型进行从窄类型到宽类型的转换,而不允许从宽类型向窄类型进行转换,除非用户明确指定并确认接受可能出现的风险
问题4:hive中如何对原生数据进行隐式转换和显示转换?
答:在Hive中,原生数据类型之间的隐式转换是系统根据需要自动进行的,并且不需要任何用户交互。
举例来说,如果你试图将一个INT类型的值赋给一个BIGINT类型的变量,系统会自动将INT值转换为BIGINT。这是因为从窄类型(INT)到宽类型(BIGINT)的转换不会导致数据丢失。
对于显示转换(也称显式转换),你需要使用CAST函数。CAST函数允许你将一种数据类型转换为另一种数据类型,语法如下: CAST ( expression AS TYPE ) expression是你想要转换的表达式,TYPE是你想要转换为的数据类型。 例如,你可以使用以下查询将double类型转换为int: SELECT CAST(123.456 AS INT); 以上查询会返回123,因为在将double转换为int时,小数部分会被舍去。
请注意,从宽类型到窄类型的转换可能会导致数据丢失或溢出,因此在进行此类转换时要特别小心。
四、hive的读写机制
问题1:hive中什么叫序列化,什么叫反序列化?
答:在Hive中,序列化和反序列化是数据读写过程中非常重要的两个步骤。
(1)序列化(Serialization):是指将数据从内存表示(例如,Hive中的字段)转换为可以存储或传输的格式的过程。序列化后的数据可以写入磁盘,或通过网络发送到另一台机器。序列化是在写入Hive数据(例如,执行INSERT操作)时发生的。
(2)反序列化(Deserialization):是序列化的逆过程,将数据从存储或传输的格式转换回内存表示。当从Hive表中读取数据(例如,执行SELECT操作)时,Hive会从磁盘文件中读取序列化的数据,然后进行反序列化,以便进一步的处理和分析。
序列化和反序列化的具体实现是由Hive的SerDe(Serializer/Deserializer)完成的。Hive提供了多种内置的SerDe,允许用户以多种数据文件格式(如TEXTFILE、SEQUENCEFILE、RCFILE、AVRO、PARQUET等)来存储数据。此外,用户也可以开发自定义的SerDe以支持自定义的数据格式。
问题2:SerDe是什么
答:SerDe是序列化(Serialization)和反序列化(Deserialization)的缩写。在Hive中,SerDe用于指定如何将数据从字段转换为用于写入磁盘的字节,以及如何从磁盘的字节回转为字段。 SerDe在Hive中起到非常重要的作用,主要包括以下几点:
(1) 让Hive理解数据: SerDe使Hive能理解用户数据的存储格式,并在查询时将这些数据转换成一个适合Hive处理的格式。
(2)支持多种数据格式: Hive通过使用不同的SerDe,可以支持多种数据格式的读写,包括但不限于CSV、JSON、Avro、Parquet等。
(3)扩展适应新的数据格式: Hive用户可以编写自定义的SerDe来对付一些无法被内置SerDe处理的数据格式,或者针对特殊的应用优化数据读写。
(4)数据压缩和优化: 在某些情况下,合适的SerDe还可以帮助用户提高数据的存储效率和查询性能。
问题3:什么时候会用到SerDe?
答:在以下几种情况下,你可能需要使用到SerDe相关的语法:
(1)当数据被存储在非标准的或者自定义的文件格式中: 对于标准的文本文件、Parquet、ORC等文件格式,Hive已经有内置的SerDe进行处理。但若碰到一些特殊的或者自定义的文件格式,那就需要自行指定SerDe。例如,可以使用Hive自带的`org.apache.hadoop.hive.serde2.OpenCSVSerde`来处理CSV的数据。
(2)当你需要对数据进行预处理: SerDe也可以用来进行一些数据预处理的操作。例如,你可能有一个日志文件,其中每一行都是一条记录,记录按照某个特定的分隔符进行分隔,但是其中一部分数据你并不需要。这种情况下,你就可以写一个自定义的SerDe,在反序列化数据的时候仅提取你需要的部分。
(3)当你需要优化查询性能: 不同的文件格式和SerDe在性能上有所差异。通过选择适合你的数据特性和查询需求的SerDe,可以优化查询性能。
(4)当你需要处理复杂的嵌套数据结构: 如果你的数据是复杂的嵌套数据结构,例如JSON或者XML,那么你就需要使用特定的SerDe来进行处理。
问题4:hive中,如果数据文件是标准的(比如文本文件),会用到SerDe相关的语法吗?
答:即使是标准的数据文件,比如文本文件,Hive也默认使用SerDe来进行序列化和反序列化操作。于文本文件,默认使用的是`org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe`这个SerDe。 但是在创建表时,你通常不需要显式地指定SerDe。除非你需要改变默认行为,比如更改字段分隔符,否则,你可以省略`ROW FORMAT SERDE`子句。例如: CREATE TABLE my_table (col1 INT, col2 STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 以上语句创建了一个新表,每个字段由逗号分隔。尽管我们没有显式地指定SerDe,但Hive仍然使用`LazySimpleSerDe`来处理数据。
请注意,如果你没有指定任何SerDe,Hive会使用默认的SerDe。 在Hive中,默认的SerDe是`org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe`。 LazySimpleSerDe可以处理所有原生的Hive类型(包括整型、浮点数、字符串、数组等),并且支持将这些类型序列化为可通过ASCII码表示的类型。默认情况下,它使用制表符作为字段分隔符,用`\n`作为行分隔符。不过,也可以通过`ROW FORMAT`子句来改变这些设置。 例如,在创建表的时候,你可以使用以下语句: `CREATE TABLE myTable (column1 INT, column2 STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; ` 以上语句实际上在后台使用了LazySimpleSerDe,它将用逗号作为字段的分隔符。
请注意,对于某些非标准但常见的文件格式,比如JSON、CSV,Hive也提供了内置的SerDe,你可以用`ROW FORMAT SERDE`子句来指定它们。如果你处理的数据文件具有自定义的格式,或者内置的SerDe无法满足需求,那么你也可以编写并使用自定义的SerDe。
问题5:hive内置的SerDe都有哪些,它们支持什么文件格式?
答:以下是一些Hive默认内置的SerDe及支持的文件格式:(1) 对于纯文本文件("TEXTFILE"):默认的SerDe是org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe。(2)对于序列文件("SEQUENCEFILE"):默认的SerDe是org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe。(3)对于RCFILE:"RCFILE"文件格式使用的是org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe。(4)对于ORCFILE:"ORC"文件格式使用的是org.apache.hadoop.hive.ql.io.orc.OrcSerde。(5)对于PARQUET:"PARQUET"文件格式使用的是org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe。注意,这里的“处理”是指对数据的序列化和反序列化。比如,对于Text File,其实质上是使用`LazySimpleSerDe`来进行数据的解析或生成。
对于一些Hive默认未支持的文件格式,例如JSON和XML,你需要使用外部的库(如`Hive-HBase-Handler`, `Hive-JSON-SerDe`,`XmlInputFormat`等)。至于这些库是否符合你的需要,你可能需要稍作研究。有时,你可能需要自己写一个SerDe来处理特殊的文件格式。
问题6:SerDe相关的语法使用和说明
答:(情形1):使用hive默认支持的文件格式:
在创建表时,不需要显式地指定SerDe,Hive会自动使用对应文件格式的默认SerDe。除非你需要改变默认行为,比如更改字段分隔符,否则,你可以省略`ROW FORMAT SERDE`子句。例如: CREATE TABLE my_table (col1 INT, col2 STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 以上语句创建了一个新表,每个字段由逗号分隔。
(情形2):使用hive默认未支持的文件格式:
那么就需要自己显式指定SerDe或者自己写一个SerDe。

五、关于分隔符
5-1 分隔符的类型
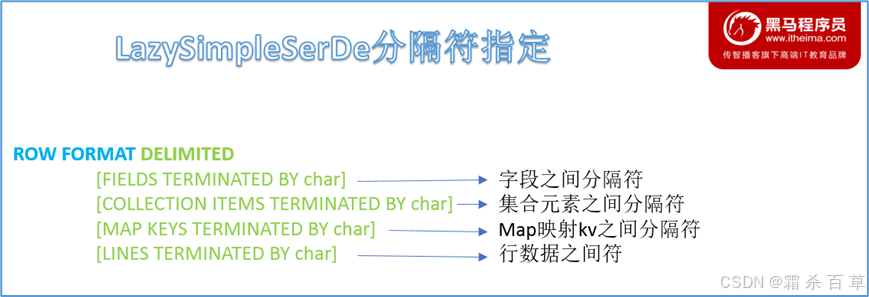
答:(1)字段分隔符:在把数据导入Hive表时,定义各个字段之间的分隔符。默认为'\001',也可以使用其他符号。(2)集合项分隔符:在把数据导入Hive表时,如果字段是数组类型,定义数组内各元素之间的分隔符。默认为'\002'。(3)映射键分隔符:在把数据导入Hive表时,如果字段是映射类型(Map类型),定义映射内的key和value之间的分隔符。默认为'\003'。(4)映射项目分隔符:在把数据导入Hive表时,如果字段是映射类型,定义映射内各节点之间的分隔符。默认为'\002'。(5)行分隔符:被用于区分数据文件中的不同行记录。默认的行分隔符是'\n',即换行符。需要注意的是,在最新的Hive版本中,行分隔符是不能被用户自定义的。尽管Hive的建表语句中有'lines terminated by'这样的语句,但实际上并不支持这个功能。
5-2 分隔符的应用
答:例子:
创建一个简单的表,表的字段名称为id,name和age,字段之间的分隔符为逗号:
CREATE TABLE test_table( id string, name string, age int )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE; --上传的文件存储到hdfs的格式为TEXTFILE,这个格式必须要和需要上传的文件类型保持一致。
如果我们有一个更复杂的数据结构,其中包含了map或者array类型的列,这时就需要用 到其他的分隔符。例如,我们现在有一个表,其中包含一个数组类型的列,数组的每个 元素之间是用冒号分隔的:
CREATE TABLE test_table( id string, name string, scores array<int> )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ':'
STORED AS TEXTFILE;
在这个例子中,FIELDS TERMINATED BY ',' 表示字段之间以逗号进行分割, COLLECTION ITEMS TERMINATED BY ':' 表示数组中的每个元素之间以冒号分割
如果我们有一个包含了map类型列的表,其中map的每个键值对以冒号分隔,键值对之间 以分号分隔:
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY ';'
MAP KEYS TERMINATED BY ':'
STORED AS TEXTFILE;
在这个例子中,FIELDS TERMINATED BY ',' 表示字段之间以逗号进行分割,COLLECTION ITEMS TERMINATED BY ';' 表示map中的每对键值对之间以分号进行分割,MAP KEYS TERMINATED BY ':' 表示map中的键和值之间以冒号进行分割。
六、hive数据存储路径
6-1 默认存储路径
Hive表默认存储路径是由${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定。默认值是:/user/hive/warehouse。如果在配置文件中没有明确指定的话,Hive会使用这个默认路径
在该路径下,文件将根据所属的库、表,有规律的存储在对应的文件夹下。

6-2 指定存储路径
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便。
语法:LOCATION '<hdfs_location>'。
对于已经生成好的数据文件,使用location指定路径将会很方便。
例子:
CREATE TABLE tablename ( column1 datatype, column2 datatype, ...
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/path/to/hdfs/directory';
以上SQL将在'/path/to/hdfs/directory'路径下创建一个名为'tablename'的表,并且表中有两列,数据以逗号为分隔符,存储为文本格式。
注意: (1) '/path/to/hdfs/directory'必须是一个有效的HDFS路径,并且Hive用户需要有在该路径下创建文件的权限。(2)如果路径已经存在并且里面有数据,Hive会试图将数据映射到新创建的表结构。数据需要符合定义在表结构中的格式。(3)如果路径不存在,Hive会在HDFS上创建一个新目录。(4)当删除表时,不会删除HDFS中的数据文件。也就是说如果你删除了表,你需要手动删除目录和目录里的文件(通常针对的外部表,内部表通常不回去自定义存储路径)。
七、内部表&外部表
7-1 什么是内部表&外部表?
答:内部表(Internal table):也称为被Hive拥有和管理的托管表(Managed table)。默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。当您删除内部表时,它会删除数据以及表的元数据。
可以使用DESCRIBE FORMATTED itcast.student;来获取表的描述信息,从中可以看出表的类型。
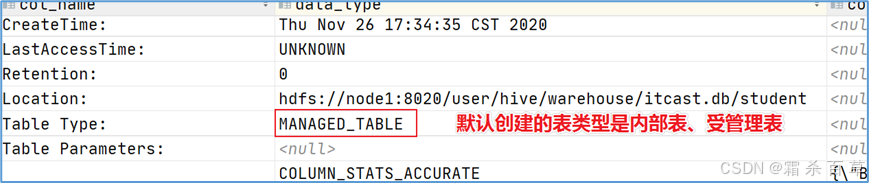
外部表(External table):数据不是Hive拥有或管理的,只管理表元数据的生命周期。要创建一个外部表,需要使用EXTERNAL语法关键字。删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。外部表更为方便的是可以搭配location语法指定数据的路径。
create external table student_ext(num int, name string)
row format delimited fields terminated by ','
location '/stu'; |
7-2 外部表&内部表存储路径相关问题
问题1:hive中,内部表可以指定数据存储路径吗?
答:在 Hive 中,有两种类型的表,分别是内部表和外部表。
在创建内部表时,Hive 会在 Hive 的 warehouse_directory 下为该表创建一个目录。warehouse_directory 是在 Hive 配置文件 hive-site.xml 中由属性 hive.metastore.warehouse.dir 指定的,其默认值是/user/hive/warehouse。因此,通常情况下,你不能直接为内部表指定数据路径。当你删除一个内部表时,Hive 会删除该表对应的目录及其所有数据。总结起来就是,可以但没有必要。
然而,对于外部表,你可以使用 LOCATION 关键字指定数据的存储路径。创建外部表时,不会把数据存储到默认目录,而是存储到用户指定位置,当删除外部表时,只是删除了表的元数据,不会删除数据。
以下是创建外部表的例子:
CREATE EXTERNAL TABLE my_table (column1 string, column2 string) LOCATION '/my/custom/location';
--这将会在 /my/custom/location 路径下创建一个新的外部表 my_table
问题2:hive中,外部表如果没有指定数据存储路径,它会存储到哪儿?
答:在 Hive 中,创建外部表时如果没有指定数据路径(即没有使用 LOCATION 子句),那么 Hive 将会使用默认的仓库路径来存储数据。
这个默认路径通常是 "/user/hive/warehouse"。
例如,如果你创建了一个名为 external_table 的外部表而没有指定路径,Hive 将在 "/user/hive/warehouse" 目录下创建一个名为 external_table 的子目录来存储此表的数据。
这是因为 Hive 的元数据存储包括了表的数据的位置。当你创建表但没有显式指定路径时,Hive 即默认其为在默认的仓库路径。
请注意,对于外部表,如果表被删除,Hive 只会删除元数据,而不会删除存放数据的文件。这是它与内部表的主要区别之一。
问题3:hive中,创建数据库能分内部和外部吗?创建数据库额可以指定创建路径吗?
答:在Hive中,数据库的概念主要是用来组织表和其他数据库对象的,并没有"内部"或"外部"的区别,这种区别主要用于表。
创建 Hive 数据库的语句如下:
CREATE DATABASE IF NOT EXISTS database_name;
--上述命令将创建一个新的数据库。如果数据库已存在,并且指定了`IF NOT EXISTS`,则命令不会执行任何操作,也不会返回错误。
每个数据库在 Hive 中都有一个对应的目录,你可以在创建数据库时指定这个目录,如果不指定,则该数据库的目录默认在 Hive 仓库的根目录下。
你可以用如下命令指定目录路径:
CREATE DATABASE IF NOT EXISTS database_name
LOCATION '/custom/location/';
尽管不像表的内部和外部那样,数据库和文件系统目录之间的关系并没有那么紧密,但你删除数据库的时候也需要小心。如果使用了 `DROP DATABASE name;` 命令并且数据库中还有表,这个命令会失败。但如果使用了 `DROP DATABASE name CASCADE;` 命令,Hive 将会删除这个数据库中的所有表(同时也会删除那些表中的数据)然后删除数据库。
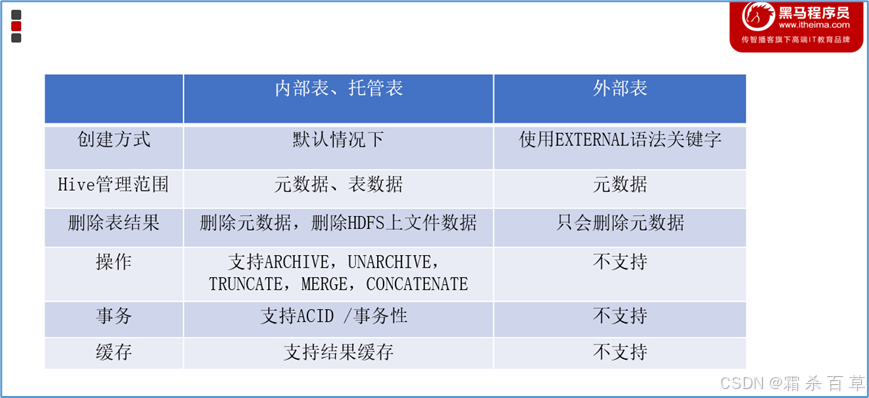
7-3 内部表&外部表的区别?
八、分区表
8-1 为什么要分区
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据,Hive支持根据用户指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。
8-2 分区表的建表语法
| CREATE TABLE table_name (column1 data_type, column2 data_type) PARTITIONED BY (partition1 data_type, partition2 data_type,….); |
需要注意:分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上。
8-3 静态分区、动态分区加载数据
见Hive语句大全(超级详细的案例大全,持续完善中) -- 自有博客
8-4 多重分区表
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。
--单分区表,按省份分区
create table t_user_province (id int, name string,age int) partitioned by (province string);
--双分区表,按省份和市分区
create table t_user_province_city (id int, name string,age int) partitioned by (province string, city string);
--三分区表,按省份、市、县分区
create table t_user_province_city_county (id int, name string,age int) partitioned by (province string, city string,county string); |
九、分桶表
9-1 分桶表的概念
分桶表也叫做桶表,源自建表语法中bucket单词。是一种用于优化查询而设计的表类型,可以在查询时避免全表扫描。
在分桶时,我们要指定根据哪个字段将数据分为几桶(几个部分)。默认规则是:Bucket number = hash_function(bucketing_column) mod num_buckets。可以发现桶编号相同的数据会被分到同一个桶当中。
分桶规则解释:hashfunc(字段) % 桶个数,余数相同的分到同一个文件(解释一下:将需要进行分桶的字段中每一个值都除以需要分桶的个数,然后将余数相同的分到同一个文件;比如我们按照id字段进行分桶,分3桶,每个id号除以3余数只有3种情况,把余数相同的编到一桶里面,总共是3桶)。
9-2 分桶表的创建语法
CREATE [EXTERNAL] TABLE [db_name.]table_name
[(col_name data_type, ...)]
CLUSTERED BY (col_name)
INTO N BUCKETS;
--其中CLUSTERED BY (col_name)表示根据哪个字段进行分;INTO N BUCKETS表示分为几桶(也就是几个部分)。需要注意的是,分桶的字段必须是表中已经存在的字段。
--在创建分桶表时,还可以指定分桶内的数据排序规则,例如:
CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;
--根据state州分为5桶 每个桶内根据cases确诊病例数倒序排序
9-3 分桶表的数据加载
例子:我有一份儿数据文件,包含了count_date(统计日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)这些信息。请问如何将文件加载到分桶表里面(根据state州把数据分为5桶)?
第一步:建分桶表
CREATE TABLE itcast.t_usa_covid19_bucket(count_date string,county string,state string,fips int,cases int,deaths int)
CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;
第二步:加载数据
1)开启分桶的功能
set hive.enforce.bucketing=true;
2)把源数据加载到普通hive表中
REATE TABLE itcast.t_usa_covid19(count_date string,county string,state string,fips int,cases int,deaths int)
row format delimited fields terminated by ",";
--将源数据上传到HDFS,t_usa_covid19表对应的路径下
hadoop fs -put us-covid19-counties.dat /user/hive/warehouse/itcast.db/t_usa_covid19
3)使用insert+select语法将数据加载到分桶表中
insert into t_usa_covid19_bucket select * from t_usa_covid19;
--到HDFS上查看t_usa_covid19_bucket底层数据结构可以发现,数据被分为了5个部分。
--注意: 首次加载数据时,通常使用INSERT OVERWRITE,它会删掉同名桶中的现有数据。如果接下来想再继续加载数据到该表,就可以使用INSERT INTO,它会保留已有数据,把新的插入数据也按照分桶列的哈希值分配到对应的桶。
十、view视图
10-1 视图的概念
Hive中的视图(view)是一种虚拟表,只保存定义,不实际存储数据。通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图。
创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败,并且视图不能存储数据,操作数据,只能查询。
概况起来就是:视图是用来简化操作的,它其实是一张虚表,在视图中不缓冲记录,也没有提高查询性能。
10-2 视图相关的语法
--hive中有一张真实的基础表t_usa_covid19
select *
from itcast.t_usa_covid19;
--1、创建视图
create view v_usa_covid19 as select count_date, county,state,deaths from t_usa_covid19 limit 5;
--能否从已有的视图中创建视图呢 可以的
create view v_usa_covid19_from_view as select * from v_usa_covid19 limit 2;
--2、显示当前已有的视图
show tables;
show views;--hive v2.2.0之后支持
--3、视图的查询使用
select *
from v_usa_covid19;
--能否插入数据到视图中呢?
--不行 报错 SemanticException:A view cannot be used as target table for LOAD or INSERT
insert into v_usa_covid19 select count_date,county,state,deaths from t_usa_covid19;
--4、查看视图定义
show create table v_usa_covid19;
--5、删除视图
drop view v_usa_covid19_from_view;
--6、更改视图属性
alter view v_usa_covid19 set TBLPROPERTIES ('comment' = 'This is a view');
--7、更改视图定义
alter view v_usa_covid19 as select county,deaths from t_usa_covid19 limit 2; |
10-3 视图的优点
- 将真实表中特定的列数据提供给用户,保护数据隐式
--通过视图来限制数据访问可以用来保护信息不被随意查询:
create table userinfo(firstname string, lastname string, ssn string, password string);
create view safer_user_info as select firstname, lastname from userinfo;
--可以通过where子句限制数据访问,比如,提供一个员工表视图,只暴露来自特定部门的员工信息:
create table employee(firstname string, lastname string, ssn string, password string, department string);
create view techops_employee as select firstname, lastname, ssn from userinfo where department = 'java'; |
2.降低查询的复杂度,优化查询语句
--使用视图优化嵌套查询
from (
select * from people join cart
on(cart.pepople_id = people.id) where firstname = 'join'
)a select a.lastname where a.id = 3;
--把嵌套子查询变成一个视图
create view shorter_join as
select * from people join cart
on (cart.pepople_id = people.id) where firstname = 'join';
--基于视图查询
select lastname from shorter_join where id = 3; |

















 5599
5599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









