



 博客围绕Python文件读取问题展开。发现代码运行异常,将部分代码注释后可运行。经查询资料,得知第一个read()后光标移到文件末尾,通过加入seek(0, 0),最终得到正常输出结果。
博客围绕Python文件读取问题展开。发现代码运行异常,将部分代码注释后可运行。经查询资料,得知第一个read()后光标移到文件末尾,通过加入seek(0, 0),最终得到正常输出结果。
如图:
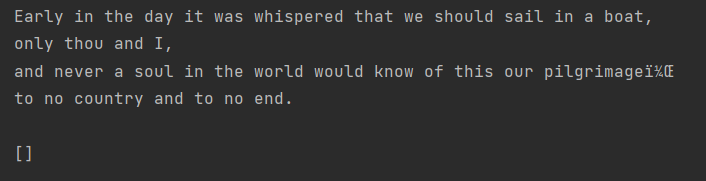 (上面的输出和这个函数无关)
(上面的输出和这个函数无关)
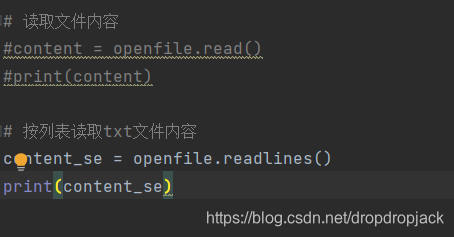
# 读取文件内容
content = openfile.read()
print(content)
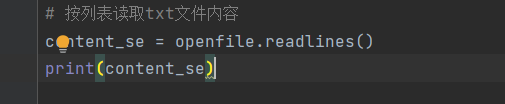
# 按列表读取txt文件内容
content_se = openfile.readlines()
print(content_se)
解决办法
发现把上面代码打上注释代码就能运行了

查询资料发现:
因为在第一个read()之后,光标移到了文件的末尾
后来加入seek(0,0)
# 读取文件内容
content = openfile.read()
print(content)
# 将光标调到文件头
openfile.seek(0, 0)
# 按列表读取txt文件内容
content_se = openfile.readlines()
print(content_se)
得到正常输出结果


















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









