




并行方式
查询并行
查询并行是指将一个查询分解为多个子查询,在多个处理器上同时执行这些子查询。查询并行通常用于处理计算密集型和IO密集型的查询,例如,涉及多个表连接、聚合、表扫描等操作的查询。查询并行可以有效地提高查询性能,因为每个处理器只需要处理查询的一部分。
这种并行方式在传统数据库中使用比较多,比如Oracle、PostgreSQL, Tbase 也采用的是这种并行方式。这种方式的好处是能将查询任务分解为多个任务,分布在多个处理器(甚至跨服务器的处理器)上并行执行,最终通过 Gather 节点将结果汇总。
相比其他的并行方式,查询并行的调度更简单,正因为如此,资源的使用效率不是最高的。另外,这种并行方式需要在处理器之间传输和同步数据,系统开销较大。
pipeline并行
管道 (pipeline) 并行是指将一个操作的输出作为另一个操作的输入,这样多个操作可以同时进行。这种并行方式通常用于数据库查询处理中的多个阶段,例如,从磁盘读取数据、过滤数据、排序数据等。
pipeline并行可以提高资源利用率,因为 pipeline 中的各个阶段、pipeline 之间可以并行、异步执行,而不是等待前一个阶段完成。
ClickHouse、Doris 等使用的就是这种并行方式。pipeline 并行的好处是能充分的利用资源,结合线程池技术,可以非常精细的调度任务,目的是提升数据处理的吞吐量。
但是这种并行方式不够灵活,因为每个处理阶段的输入输出是固定的,限制了处理阶段之间的交互和协作,同时还需要管理和协调好各个处理阶段,提升了调度的复杂度。与之对应的是 DAG(Directed Acyclic Graph) 方式,典型的产品就是 Spark。
任务并行
任务并行是指在多个处理器上同时执行不同的任务。这种并行方式通常用于处理多个独立的查询或事务。任务并行可以提高系统的吞吐量,因为多个查询或事务可以同时进行。
TDSQL for PG 的后台任务,比如 autovacuum、checkpointer 等就是这种并行方式,任务之间独立执行,互不干扰。
数据并行
数据并行是指在多个处理器上同时对数据集的不同部分执行相同的操作。这通常是通过将数据划分为多个分区来实现的,每个处理器负责处理一个分区。
数据并行可以有效地提高查询性能,因为每个处理器只需要处理数据的一部分。通常来说,上面的并行方式都会结合数据并行来执行。
指令并行
本文指的指令并行是利用SIMD指令的并行,SIMD指令可以减少分支预测的开销,提高内存访问的局部性、cache的命中率。数据库中的排序算法可以利用 SIMD 指令进行并行比较和交换,join 也可以使用 SIMD 进行并行的匹配,最常用的是压缩和编码用 SIMD 提升性能。
TDSQL for PG 主要使用了查询并行、数据并行、任务并行这几种方式,本文重点要分析的是查询并行的框架和原理。
![]()
并行框架概述
![]()
TDSQL for PG 并行框架总体流程
在并行框架中有三种进程角色,分部是 server 进程,backend 进程(也称作 leader 进程)和 Background Worker 进程。
-
server 进程是资源调度进程,负责进程的分配
-
backend 是并行任务的发起进程,负责并行执行环境的初始化,也负责通过 Gather 和 GatherMerge 节点汇总结果
-
Background Worker 进程是任务的具体执行者,并返回结果给backend 进程。
执行的流程跟单进程时一样,都会依次调用 CreateQueryDesc(), ExecutorStart() , ExecutorRun(), ExecutorFinish(), ExecutorEnd() 函数。
区别在于 Background Worker 需要先从动态共享内存中恢复执行需要的环境,以及执行结束后清理动态内存。
TDSQL for PG 的并行框架主要流程如下图所示:
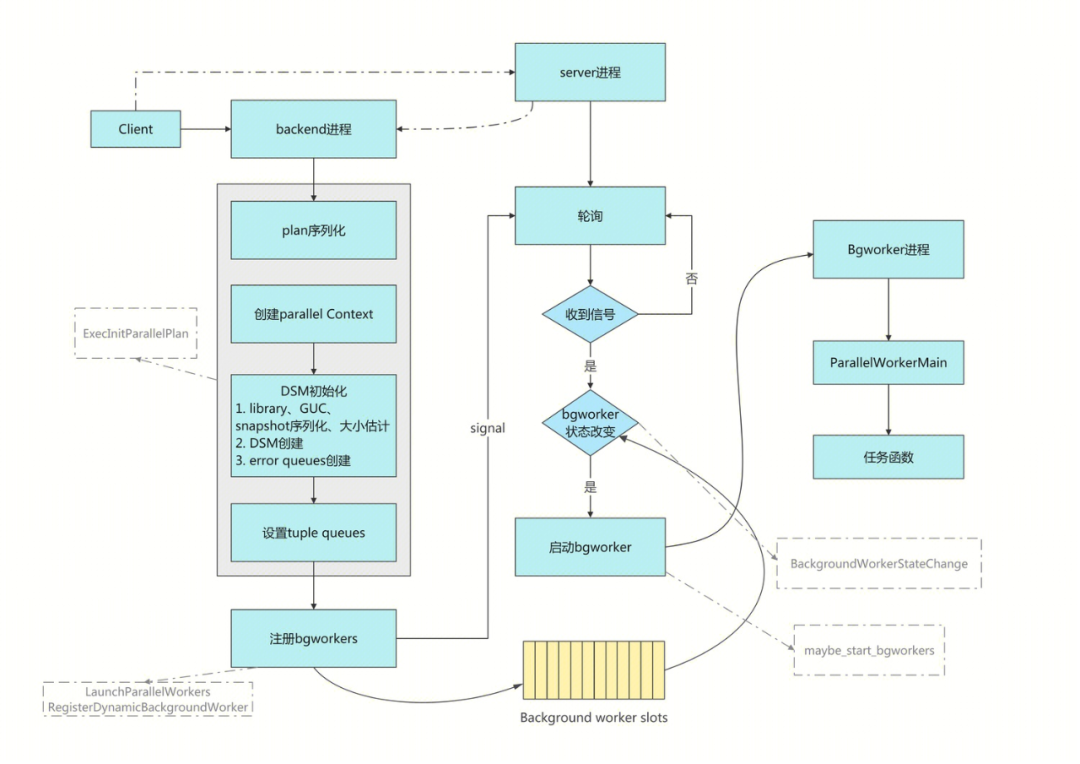
1. Client 连接到 server 以后 server 进程为其创建一个 backend 进程,banckend 进程在生成执行计划的过程中识别出是否需要并行执行,如果能并行执行就会创建 Background Worker 进程。
2. 如果并行执行,backend 进程先调用ExecInitParallelPlan()函数初始化并行执行需要的环境。
包括执行计划的序列化(ExecSerializePlan()),动态共享内存初始化InitializeParallelDSM(), 动态共享内存初始化又包含动态共享内存段的创建,library、GUC、snapshot 等的序列化和拷贝。
3. 接着后端进程调用LaunchParallelWorkers()注册 Background Worker。
注册的方式是调用RegisterDynamicBackgroundWorker()查找可用的 Background Worker 槽位,如果找到就向 server 进程发送PMSIGNAL_BACKGROUND_WORKER_CHANGE信号。
4. server 进程处理信号(sigusr1_handler())。
调用BackgroundWorkerStateChange()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









