




开篇语:为什么我们要重读经典?
最近很忙,但还是在抽时间看这本神书——《数据密集型应用系统设计》。在技术迭代如此迅速的今天,我们为什么还要花时间研读一本出版于2017年的技术书籍?答案很简单:底层原理从未改变。
《数据密集型应用系统设计》(DDIA)就像分布式系统领域的《算法导论》,它不教你具体工具的API使用,而是揭示那些五年后、十年后依然适用的核心原则。当我读这本书时,最深的感受是:"原来大浪淘沙后的系统设计,在8年前就被这本书预言了。"
这本书的适合所有后台开发工程师、大数据工程师,也很适合面试前复习系统设计的同学,或者是想要提升计算机底层认知的同学。
文章目录
一、本系列的特殊视角
这不是普通的读书笔记,而是一个后端开发的深度批注版。你将看到:
- 理论到实践的映射:比如"为什么MongoDB的默认隔离级别恰好对应书中提到的read uncommitted?"
- 行业演进验证:书中2017年的预言(如Stream Processing的兴起)如何被近年的Flink、Kafka Streams等工具验证
- 反常识洞见:“原来用JSON做数据交换格式在某些场景下比Protocol Buffers更合适?”
二、前言:什么是「数据密集型应用系统设计」?
“不是所有的系统都是数据密集型的,但所有重要的系统都是。” —— Martin Kleppmann
当我在学习分布式系统时,曾经天真地认为只要把数据库换成 MongoDB 就能解决所有性能问题。直到自己做的系统在集成测试时反复崩溃,我才真正明白:数据系统的复杂性不在于工具的选择,而在于对底层原理的理解。这正是《数据密集型应用系统设计》这本书的价值所在。
这本书不是一本工具手册,而是一把打开系统设计思维的钥匙。它从三个维度构建了数据系统的完整认知框架:
- 数据系统基础:数据如何被组织、写入和查询。这里藏着所有数据库共通的秘密,比如为什么Redis用跳表而不用B树实现有序集合。
- 分布式数据系统:当数据分散在不同机器上时,如何保持系统的一致性。你会发现Kafka和Zookeeper解决的是同一个本质问题,只是方式不同。
- 派生数据:从批处理到流式计算,现代数据系统的演进路线。理解这一点,就能明白为什么Flink会逐渐取代Spark Streaming。
与其他技术书籍不同,这本书最珍贵的地方在于它教会你如何思考,而不是告诉你该怎么做。当我在工作中遇到各类不同数据库时,书中的原理帮助我跳出了" MySQL 还是 Redis "的二元选择,转而思考:我们的数据访问模式到底是什么?需要什么样的一致性保证?
个人建议:不要试图一次性消化所有内容。我的方法是每读一章就停下来,对照工作中的实际系统思考:这个设计在什么情况下会出问题?有没有更好的替代方案?
在我看来,好的系统不是凭空出现的,而是建立在深刻理解这些基本概念之上的。现在,让我们从数据系统的基础特性开始,探索可靠、可扩展和可维护的系统究竟应该如何设计。
三、本篇核心路线
这篇博客将从以下四个方面介绍数据密集型应用系统的第一部分——数据系统基础:
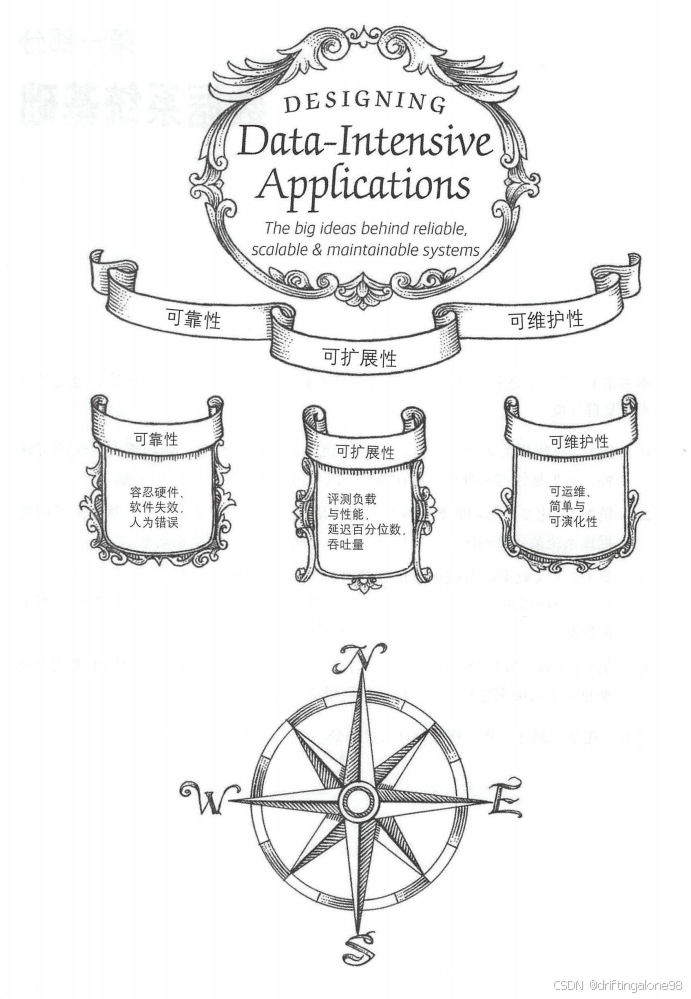
- 数据系统的核心特性:可靠性/可扩展性/可维护性,看似简单的三个词,如何在系统设计中形成"不可能三角"?(附真实经历案例)
- 数据模型与查询语言:从关系型到文档型,本质是处理什么核心矛盾?
四、数据系统的核心特性
当我第一次在生产环境部署数据库时,面对监控面板上跳动的指标突然意识到:一个可靠的数据系统,本质上是在解决三个永恒的问题:
- 当硬盘损坏时,数据会不会丢失?(可靠性)
- 用户量暴涨十倍时,系统会不会瘫痪?(可扩展性)
- 三年后接手的新人,能不能看懂我的设计?(可维护性)
在分布式系统领域,这三个核心特性构成了所有技术决策的基础框架。Martin Kleppmann在《数据密集型应用系统设计》中通过大量工业级案例,揭示了这些抽象概念背后的工程实践。
1. 可靠性的本质
书中开篇就讲述了这样一个案例:NASA的火星探测器在2004年遭遇文件系统损坏,由于设计了完善的错误恢复机制,系统自动切换到备份存储器,挽救了价值4亿美元的任务。
去年实习时也曾经历过一次严重的线上事故:数据库主节点宕机后,从节点因为网络分区无法接替服务。正如书中所说,可靠性不是指"永不故障",而是"故障时能优雅降级"。
现代系统通常通过以下方式保证可靠性:
- 数据冗余:采用多副本机制,比如PostgreSQL的流复制
- 故障转移Kubernetes实现自动故障检测和切换
- 恢复测试:每月定期演练数据库恢复流程
2. 可扩展性的两个维度
书中详细分析了Google搜索引擎的演化历程。早期版本使用单机索引,当网页数量突破1亿时完全无法应对。后来采用分片(sharding)设计,将索引分布在数百台机器上,才解决了扩展性问题。
Kleppmann特别强调:真正的可扩展性来自**无共享架构(shared-nothing)**设计,如Amazon DynamoDB的分区策略。
可扩展性必须考虑到以下两个维度:
- 吞吐量:系统每秒能处理多少请求
- 延迟:单个请求的响应时间
例如,当我们要优化一个商品搜索服务的接口时,不仅要考虑 QPS 数值的高低,也需要考虑到单个请求的响应延迟,就如同下面这段代码所做。
# 采用分级缓存策略
func get_product(id):
result = cache.get(id)
if not result:
result = db.query(id)
cache.set(id, result, timeout=60) # 热数据缓存1分钟
return result
3. 可维护性的实践
2012年Twitter的"Fail Whale"错误页面频繁出现,根源在于系统过于复杂难以维护。书中分析这个案例时指出,他们后来通过以下改进解决了问题:
- 将单体应用拆分为微服务
- 统一日志格式和监控系统
- 建立完善的文档文化
我也曾接手过一个遗留系统,其存储过程竟有1000多行。这让我切身体会到:可维护性差的系统就像负债,会持续消耗开发资源。在我看来,可维护性来自于以下三点:
- 统一接口规范(例如,统一使用gRPC + Protobuf)
- 完善的监控埋点(例如,使用Prometheus指标+Jaeger追踪)
- 详细的变更文档(例如,每个DDL都附带设计说明)
4. 经典三难选择
书中用数据库领域著名的CAP定理说明,任何系统都只能在一致性、可用性、分区容错性三者中满足两项。例如:

这个框架也解释了为什么金融系统通常选择PostgreSQL,而社交网络偏爱Cassandra。
"好的系统设计不是选择完美的方案,而是做出明智的妥协。" —— 这正是本章的精髓所在。下一章我们将深入数据模型的世界,探索关系型与文档型数据库的本质区别。
五、数据模型与查询语言——从关系型到多范式融合
上图,“SQL都市圈” 和 “XML数据库废墟” 可还行
让我们暂时放下技术细节,先思考一个根本问题:为什么世界上存在这么多种数据库?答案藏在数据模型这个最基础的概念里——它决定了我们如何描述和操作数据,就像不同的语言会塑造不同的思维方式,SQL让我们用表和关系思考,而图查询语言则引导我们用节点和连接思考世界。
1. 关系模型的本质
书中用一个精妙的案例开篇:LinkedIn早期使用关系数据库存储社交网络时面临的困境。想象一下,当你想查询"朋友的朋友"这样的简单关系时,在关系数据库中需要执行多次JOIN操作。作者详细计算了这种查询在数据量增长时的成本:每增加一度关系,查询复杂度就呈指数级上升。这正是LinkedIn最终转向图数据库的根本原因——不是技术上的时髦追求,而是因为图模型与社交网络这种高度互联的数据结构有着天然的契合。
实际上,关系模型的本质就是表,或者称为元组。没有复杂的嵌套结构,也没有复杂的访问路径,并且支持任意条件查询,可以在任何表中插入新记录,而不必担心与其他表的外键关系。
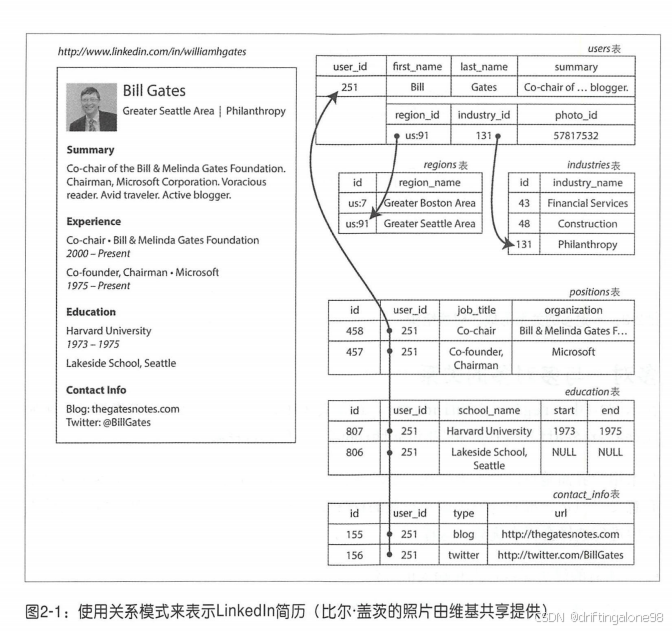
Martin Kleppmann在书中精辟地指出:"关系模型的核心价值在于它强迫我们明确数据结构之间的逻辑关系。"这种严谨性体现在:
-
规范化设计:书中以订单系统为例,展示如何通过范式分解消除冗余,但过度规范化会导致查询复杂度上升。(需要多个JOIN)
-
SQL的表达能力:详细解析了窗口函数(Window Function)的实现机制,对比了不同数据库对SQL标准的扩展。(如PostgreSQL的CTE)
-
事务保障:通过银行案例说明ACID特性的实现原理,分析了隔离级别与性能的权衡关系。
2. 文档模型的崛起

在传统关系设计中,一个社交网站的“用户”信息可能需要分散在十几个表中;而文档数据库允许将所有用户信息及其所有明细作为一个完整的文档存储。这种局部性不仅提高了查询效率,更重要的是,它反映了我们对"用户"这个概念的直觉理解。但作者也指出了代价:当需要进行多人物分析时,这种优势就可能变成劣势。
作者同样也解释了为什么我们会将一些字段,如 region_id 和 industry_id 定义为 ID,而不是文本字符串形式,本质上是因为 ID 这个字段对人类没有任何直接意义,因此永远不需要直接改变。
实际上,文档的一对多关系天然形成了一棵树。相比于关系型数据库的多次联结查询,文档型数据库只需要一次查询便可获得相同的内容。
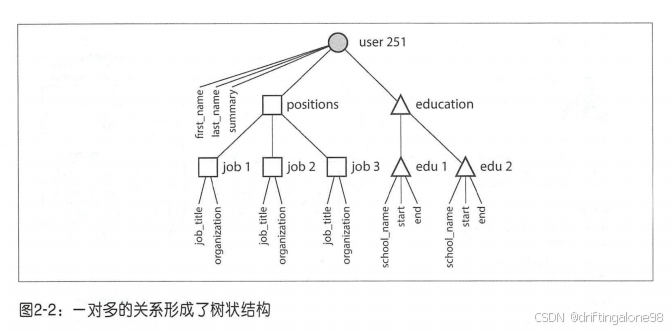
书中用MongoDB(使用Bson,Json的二进制变种)的设计哲学说明文档模型的优势:
-
模式灵活性:解释了JSON文档如何自然映射到编程语言对象,对比了模式演化在关系型和文档型中的不同表现。
-
局部性优势:详细分析了文档存储的物理布局,解释了为什么单文档操作比跨表JOIN更快。
-
局限性:书中明确指出文档模型对多对多关系的处理缺陷,分析了MongoDB如何通过$lookup模拟JOIN。
3. 图数据库的独特价值
引人深思的是书中对多语言存储(polyglot persistence)的讨论。通过分析大型互联网公司如Google和Amazon的实际架构,作者展示了现代系统如何混合使用不同数据模型:用关系型处理交易,用文档型存储产品目录,用图数据库管理社交关系。这种混合不是随意为之,而是基于对每种模型核心优势的认识。作者特别强调,关键在于理解数据访问模式——就像优秀的厨师会根据食材特性选择烹饪方法一样,工程师必须根据数据特性选择存储模型。
那么,为什么图数据库适合社交关系呢?
关系型数据库可以很好地表达一对一,联结可以使得其对一对多和多对多也具有一定的表达能力;文档数据库擅长大量复杂的一对多且灵活的模式。但这两者都不适用于大量复杂的多对多关系。
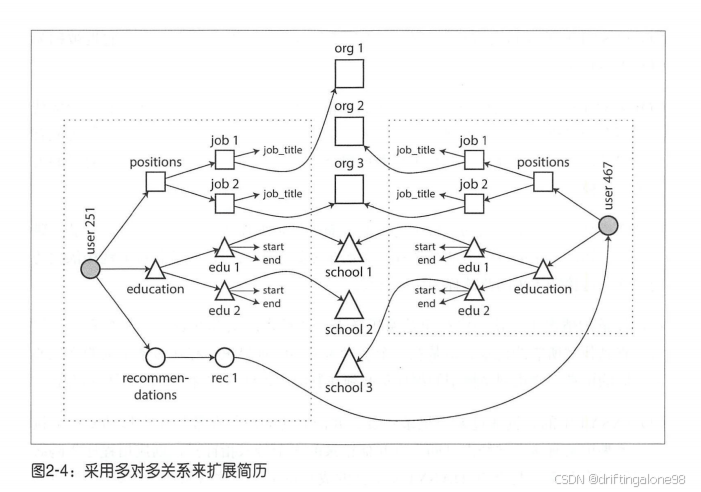
Kleppmann用社交网络案例深入讲解图模型:
-
属性图模型:解释了顶点(Vertex)和边(Edge)的存储结构,对比了Neo4j与RDF三元组存储的区别,
-
查询优化:详细说明了图遍历算法如何优化,分析了Cypher查询语言的编译过程
-
适用场景:书中明确界定了图数据库的最佳使用场景,对比了关系型与图型在处理复杂关系时的性能差异
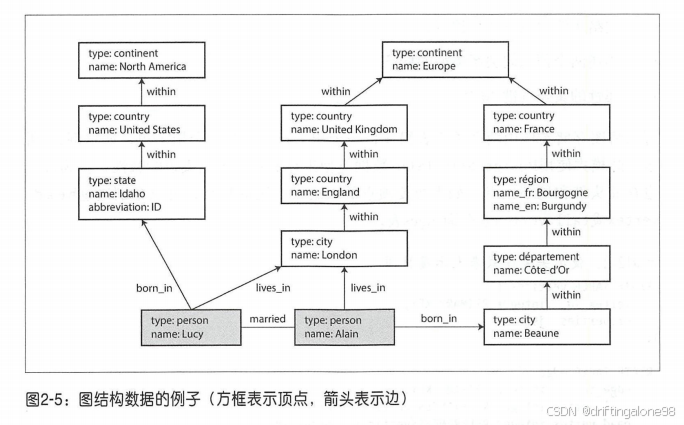
4. 查询语言的演进——从SQL到多范式融合的思考之旅
关于查询语言的范式,作者没有停留在语法比较层面,而是深入解释了为什么SQL能在几十年间保持主导地位:它的声明式特性让优化器可以自主决定执行计划。通过对比早期MapReduce的冗长代码和等效的SQL查询,生动展示了抽象层次的重要性。
1. 关系型语言的统治时代
早期的SQL语言之所以能成为行业标准,本质上是因为它完美契合了关系模型的数学基础。书中通过TPC-H基准测试中的典型查询案例,展示了声明式语言的精妙之处。比如一个简单的"找出销售额前十的产品类别"查询:
SELECT category, SUM(amount) as total
FROM sales
GROUP BY category
ORDER BY total DESC
LIMIT 10;
这种表达之所以强大,是因为它将"要做什么"与"如何做"彻底分离。但书中也尖锐指出其局限:当Google需要处理全网链接分析时,SQL的固定模式就暴露了不足——它难以表达复杂的迭代算法,这正是MapReduce诞生的背景。
2. MapReduce的革命与局限
书中详细分析了 Google 那篇著名的 MapReduce 论文(强烈建议阅读原论文),揭示了其突破性价值。通过简单的map和reduce两个原语,工程师可以自由表达各种分布式计算逻辑。比如统计网页关键词频率的典型模式:
// Map阶段
function map(doc) {
doc.text.split(' ').forEach(word => {
emit(word, 1);
});
}
// Reduce阶段
function reduce(word, counts) {
return Array.sum(counts);
}
但这种灵活性带来了新的问题:书中对比了相同功能的SQL与MapReduce实现,后者往往需要10倍以上的代码量。更关键的是,优化责任完全转移给了开发者——就像从自动挡汽车换成了手动挡。
3. 新一代混合范式的崛起
正是看到这些局限,Spark团队创造了DataFrame API这个巧妙的中层抽象。书中通过亚马逊商品推荐的案例,展示了这种演进如何兼得易用性与灵活性:
# 用PySpark实现协同过滤
ratings = spark.read.parquet("s3://ratings")
user_matrix = ratings.groupBy("user").pivot("item").avg("rating")
similarity = user_matrix.crossJoin(user_matrix).computeCosineSimilarity()
这种API既保留了关系操作的简洁性,又允许嵌入自定义算法。Kleppmann特别强调,这代表了查询语言发展的关键趋势:分层抽象。就像编程语言从汇编演进到高级语言一样,数据处理语言也在向更高阶的抽象演进。
4. 图查询语言的范式突破
当分析Twitter的社交传播路径时,传统的表格式思维遇到了根本性挑战。书中用Neo4j的Cypher语言示例展示了图查询的直观性:
MATCH (user:User)-[:FOLLOWS*2..3]->(influencer)
WHERE user.id = "123" AND influencer.verified = true
RETURN influencer, COUNT(*) as path_count
ORDER BY path_count DESC
这种专门为关系遍历设计的语法,使"三度人脉分析"这类查询变得异常简单。但作者也指出代价:同样的查询如果要做聚合统计,就不如SQL方便。
5. 流式处理的语法创新
书中用Twitter实时热点分析的案例,对比了批处理与流处理的思维差异。Flink SQL的创新在于将流抽象为动态表:
SELECT window_end, hashtag, COUNT(*) as mentions
FROM TUMBLE(tweets, post_time, INTERVAL '1' MINUTE)
GROUP BY window_end, hashtag
ORDER BY mentions DESC
这种设计让开发者可以用熟悉的SQL思维处理无界数据流,背后是复杂的watermark和状态管理机制。作者认为这代表了查询语言的最新前沿:统一批流语义。
6.小结
查询语言的演进本质上是对"数据思维范式"的持续探索。从严格的表格式思维,到灵活的过程式控制,再到声明式与命令式的有机融合,每一步突破都源于对特定场景下人类思维习惯的深刻理解。这也解释了为什么现代系统如Spark和Flink都趋向于提供多层次的API——因为不同的抽象层级适合解决不同的问题,就像我们既需要诗歌也需要编程语言一样。
5. 总结
数据模型是个庞大的主题,这里我们快速介绍了各种不同的数据模型。数据模型选择本质上是对现实世界的建模方式选择。就像作者在总结时所说:"没有最好的数据模型,只有最合适的思维方式。"这种理解让我在面对不同的业务场景时,不再急于选择技术,而是先问自己:这个业务领域的本质结构是什么?我们需要如何思考和操作这些数据?这种思维转变,或许正是阅读经典最大的价值。
下节预告:
3. 存储引擎的黑魔法:为什么说B-tree和LSM-tree是现代数据库的"任督二脉"?
4. 编码的哲学:Avro/Thrift/Protobuf背后隐藏的系统演化思维

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









