




系列文章介绍
本系列是我作为一名后端开发,在日常工作中积累的技术学习与实践笔记。在这里,我将分享工作中后端开发领域的技术栈、架构设计、代码实现以及问题解决的经验与心得。出于保护公司隐私的原因,实际业务场景无法详细展开,但我会通过抽象化的需求和通用的技术问题,来介绍与探讨如何在实际工作中应用这些技术。
文章目录
前言
K8S中有非常多的概念和专业术语,许多小伙伴上手会感觉知识点又多又杂,难以理解。我推荐的方式是,先学习理论知识,再去实操,再回来复习一遍理论知识,达到融汇贯通的境界。在这篇博客中,我会详细介绍K8S的核心概念和专业术语。
近些年我们正越来越多地听到一个概念——“云原生”,而Kubernetes(下文简称为K8S)作为云原生技术的核心组件之一,是现如今企业云原生系统的主流解决方案,也正在成为后端开发所必须要了解和使用的一项技术。现在实习公司的基础架构平台正是基于K8S所搭建的,为了更好上手公司业务,并拓展自己的技术深度与广度,特此开辟K8S专题技术博客,记录自己的所学、所想、所悟。
一、前置知识
在正式进入K8S核心概念前,需要先介绍两个前置知识。
1. 服务的分类
在讨论 Kubernetes(K8S)的核心概念前,我们需要明确服务可以划分为两类:
- 有状态服务(Stateful Services)
- 无状态服务(Stateless Services)
下面将详细说明这两类服务的特点,并通过列表和表格进行对比。
1.有状态服务(Stateful Services)
有状态服务需要维护上下文信息或状态,例如用户会话或数据更新记录,代表是MySQL与Tomcat。需要确保状态在服务实例间或持久存储中保持一致。它具有如下特点:
a.状态管理:每个请求可能依赖于先前的请求结果或上下文数据。
b.扩展难度较大:由于需要同步或共享状态,扩展时常常需要额外的协调机制。
c.数据一致性:对于数据一致性有较高要求,通常依赖于持久存储解决方案(如数据库)。
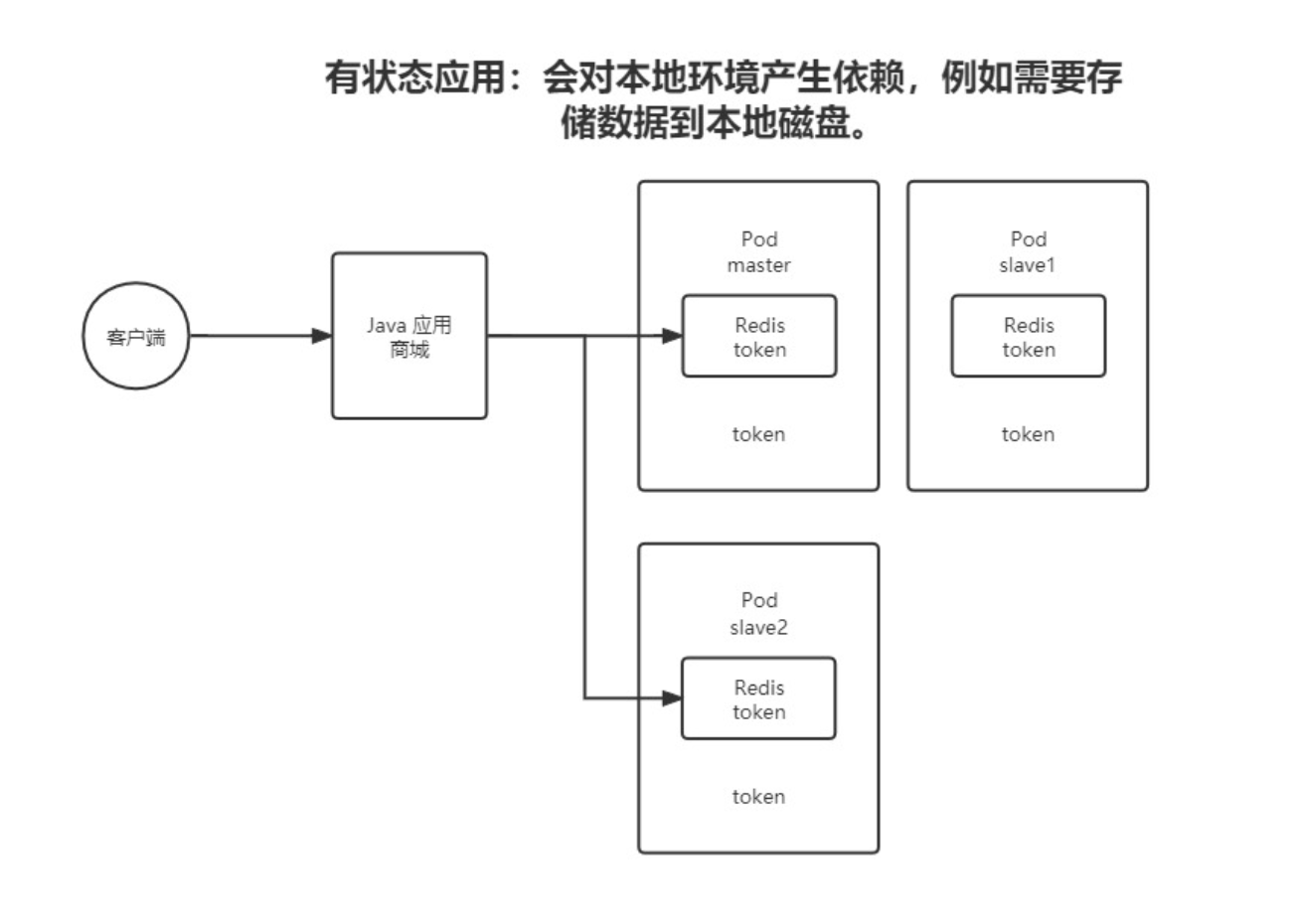
在K8S中,通常使用 StatefulSet 部署,借助持久卷(Persistent Volume)来管理和共享状态数据,以保证服务的正确运行。
2.无状态服务(Stateless Services)
无状态服务的核心特点是不依赖于内部或外部保存的状态,代表是Nginx与Tomcat。每次请求都是独立的,即使请求之间没有共享任何信息,服务依然能够正确响应。它具有如下特点:
a.独立性:每个请求都是独立处理,不依赖先前的交互历史。
b.扩展性:容易进行水平扩展,因为不需要在多个实例间同步状态。
c.容错性:单个实例出问题不会影响其他实例,重试生效率较高。
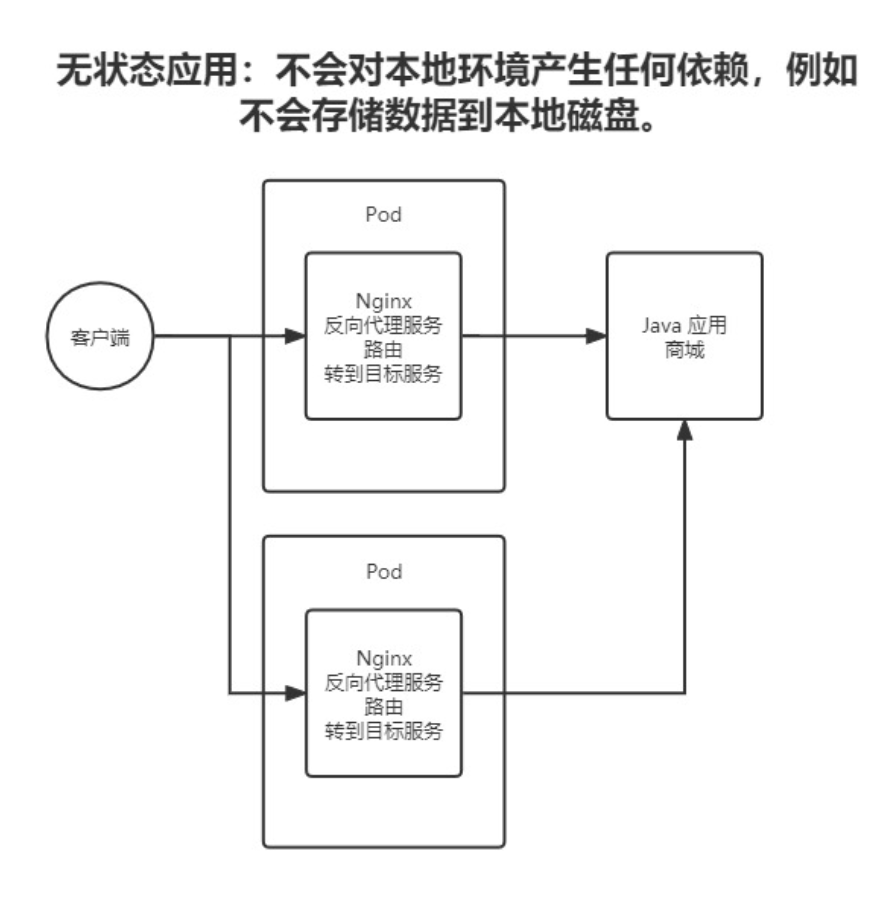
在K8S中,通常使用 Deployment 或 ReplicaSet 部署,实例之间是相互独立的。
2. 资源与对象
在 K8S 中,我们常说“一切皆资源”,而每个资源创建后就会生成一个“对象”。这种设计使得对集群中各个组件的管理更加统一和抽象。下面分别介绍两个概念。
1.资源(Resource)
资源指的是 Kubernetes API 中的一类实体,是对系统中各类对象类型的抽象描述。资源定义了一种操作接口的行为与规范,它不是具体的数据实例,而是定义了集群中能够管理的各种实体。每一种资源都在API中有统一的表示,例如Pod、Service、Deployment等。
个人理解中 ,可以将资源类比于面向对象编程的“类”,它定义了对象的蓝本。
2.对象(Object)
对象是根据资源类型创建出的实际实例,代表着集群中被持久存储和管理的具体数据单元。对象是用户提交资源相应资源配置后才生成的。每个对象都有唯一标识,作为集群实际运行和管理的单元。在K8S中,我们通过各类控制器对操作对象的创建、修改和删除。
个人理解中 ,可以将对象类比于面向对象编程的“实例”,它实现了资源这一蓝本。
3. 规约与状态
在 Kubernetes 中,每个资源对象除了包含其类型信息外,还由两个核心部分组成:规约(Spec)和状态(Status)。这两者在对象的描述中各有分工,共同帮助系统实现期望与现实之间的对齐。
1.规约(Spec)
规约是自愿的声明,描述了用户希望资源具备的配置和期望状态。比如在 Pod 的配置中,规约可能包括镜像名称、容器端口、环境变量等。它具有以下特点:
- 用户主观定义:由用户在配置文件中明确指定。
- 声明目标状态:它是不变的期望目标,由控制器作为依据来驱动实际状态的调整。
- 可更新性:用户可以在运行期间通过更新规约来调整应用行为,系统随之进行变更操作。
2.状态(Status)
状态(Status)是资源的反馈部分,反映了当前资源在集群中实际运行的情况。例如,Pod 的状态信息可能包含当前运行的副本数、错误信息、健康检查状况等。它具有以下特点:
- 自动更新:状态由 Kubernetes 控制器自动进行更新,展示实际运行情况。
- 实时反馈:它帮助用户和系统及时了解当前资源是否达到规约所定义的期望状态。
- 不由用户直接修改:通常状态信息只读,用户调整资源只需修改规约,后续状态会自动更新。
简而言之,规约是用户对资源的期望,而状态是资源的实际情况。
二、核心概念
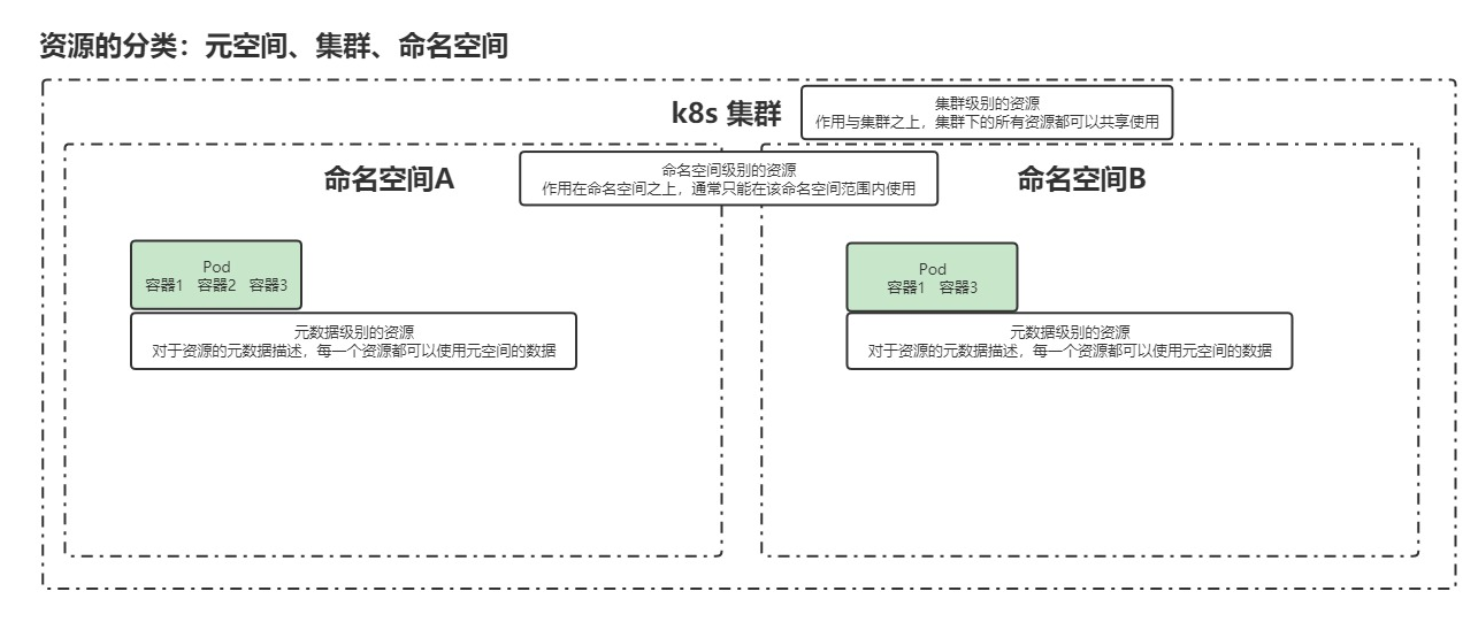
核心概念主要是各类资源,资源可以分类为三种:元数据、集群、命名空间。
- 元数据资源可以跨集群使用,比如跨测试、预发、生产集群;
- 集群级资源可以跨命名空间使用;
- 命名空间级资源只能在自己的命名空间内使用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 940
940



 到【灌水乐园】发言
到【灌水乐园】发言








