







 本文介绍了C++中实现KMP算法的过程,包括KMP算法的基本思想、NEXT数组的构造和匹配原理,以及代码实现。KMP算法通过避免不必要的字符比较,提高了字符串匹配的效率,时间复杂度达到O(m+n)。
本文介绍了C++中实现KMP算法的过程,包括KMP算法的基本思想、NEXT数组的构造和匹配原理,以及代码实现。KMP算法通过避免不必要的字符比较,提高了字符串匹配的效率,时间复杂度达到O(m+n)。
C++题解 KMP字符串
题目描述
给定一个模式串 S S S,以及一个模板串 P P P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串 P P P 在模式串 S S S 中多次作为子串出现。
求出模板串 P P P 在模式串 S S S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N N N,表示字符串 P P P 的长度。
第二行输入字符串 P P P。
第三行输入整数 M M M,表示字符串 S S S 的长度。
第四行输入字符串 S S S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1
≤
N
≤
105
1≤N≤105
1≤N≤105
1
≤
M
≤
106
1≤M≤106
1≤M≤106
输入样例:
3
aba
5
ababa
输出样例:
0 2
思路
一、初识KMP
KMP介绍
KMP是一种字符串匹配算法,通常我们对于两个字符串匹配,一般使用两个循环嵌套进行暴力求解,很显然时间复杂度为 O ( m ∗ n ) O(m*n) O(m∗n),是非常不乐观的,而KMP的时间复杂度可以优化到 O ( m + n ) O(m+n) O(m+n)。
KMP算法由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)
KMP相关概念
我们称要匹配的字符串 s[] 为模式串, 类似地,称 p[] 为模板串,同时有一个 next[] 数组。
字符串前一部分 与 字符串后一部分 的一串字符相等时,我们分别称之为 **匹配前缀 ** 和 匹配后缀。
KMP匹配原理
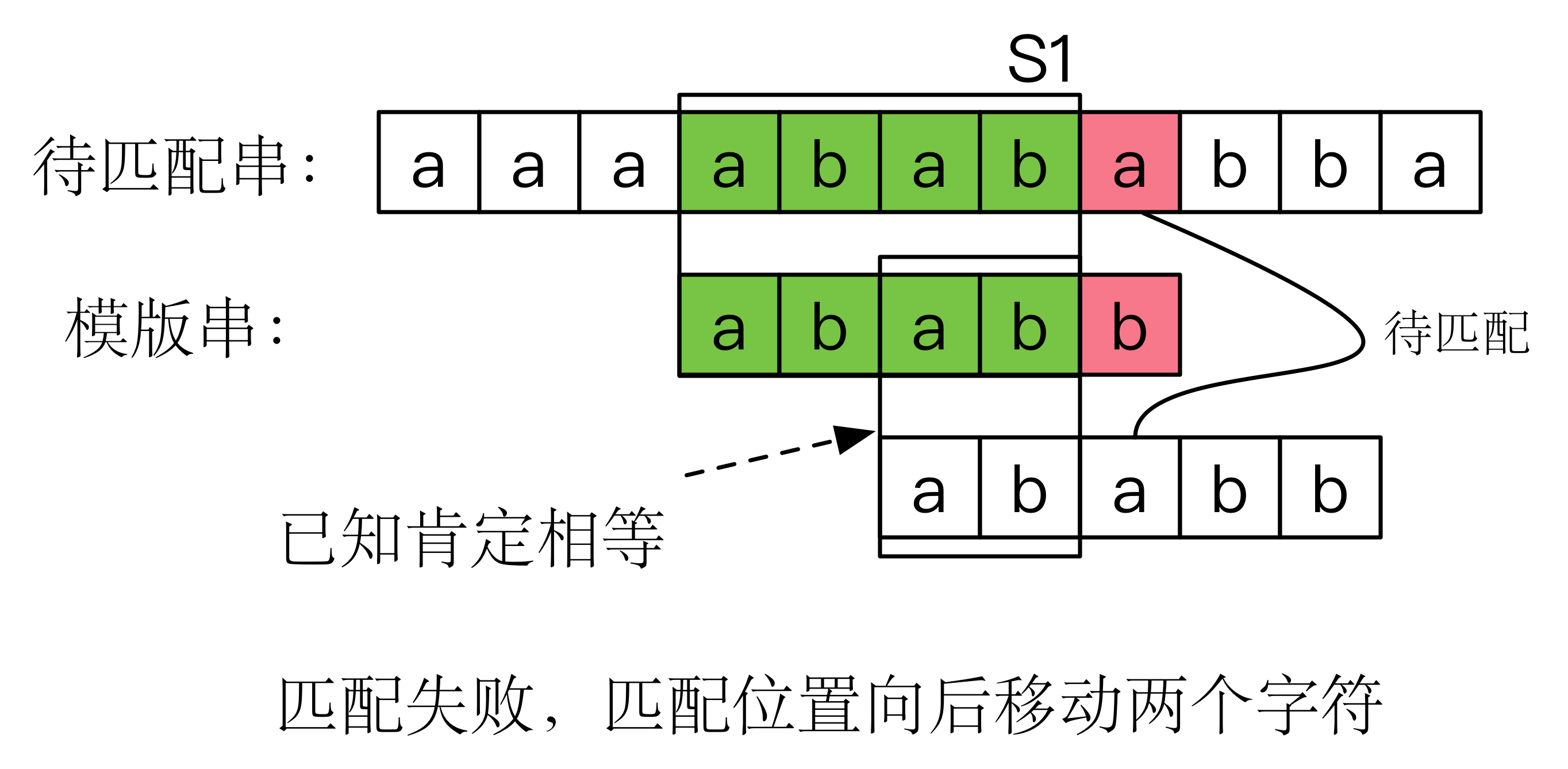
如上文所述,朴素算法我们使用两个循环暴力匹配,每次匹配失败,将模板串移动一位继续匹配但是这会造成许多无意义的匹配。为了解决这个问题,我们一定想要模板串能向后移动一段较长距离,这样就能减少时间消耗。那么这么最长距离怎么获得呢?
如上图,在匹配失败处的前一串字符,我们可以找到最长 匹配前缀 和 匹配后缀 ,它们是 ab ,匹配失败处前这段字符串我们已经和匹配串匹配了,意味着我们不需要再次匹配,于是我们移动整个模板串向后,使得 匹配前缀 对齐 匹配后缀 ,于是我们可以继续从 匹配前缀 的后一个字符继续开始匹配了,这段操作为我们节省了不少时间。
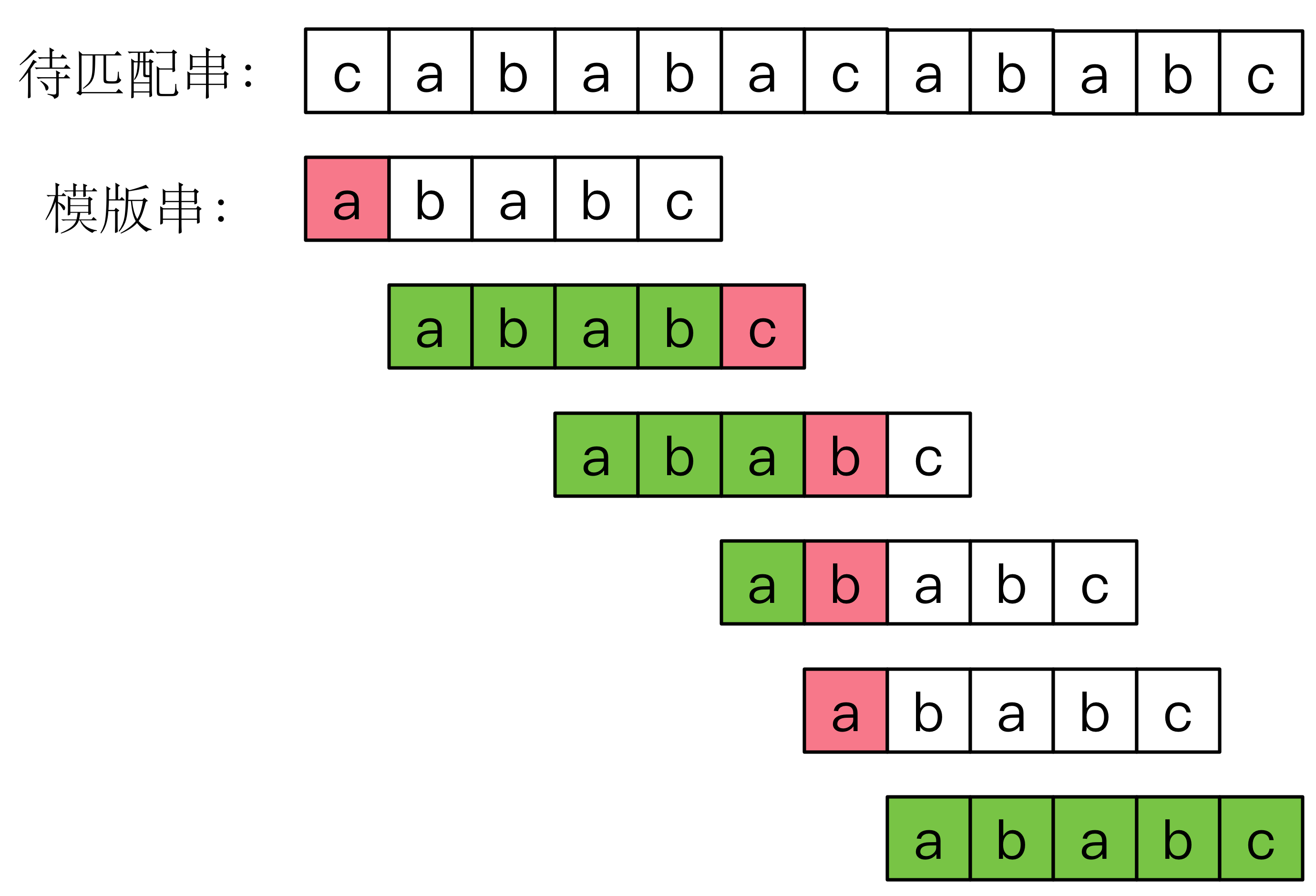
下面放一个KMP匹配过程,大家再体验一下。
二、NEXT数组
我们对上述 移动模板串使得匹配前缀与匹配后缀对齐 这一行为进行量化,得到的是 NEXT数组。
NEXT 数组的含义即:当前位置的字符不匹配时,我们应该返回到哪个位置继续进行匹配。
NEXT数组的构造
在这里举个例子,对于模板串 ababc ,我们构造得出以下 NEXT 数组:
注意:此处模板串数组下标从1开始
| 字符 | a | b | a | b | c |
|---|---|---|---|---|---|
| 下标 | 1 | 2 | 3 | 4 | 5 |
| 返回位置 | 0 | 1 | 1 | 2 | 3 |
这里先贴出NEXT构造函数的代码,此处模板串数组下标从1开始
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
此处以对 next[n + 1] 求解举例,我们求解 next[n + 1] ,说明对于 next[1]...next[n] 我们肯定是已知的。
很显然我们有三种情况:
1. n + 1 == next[n]
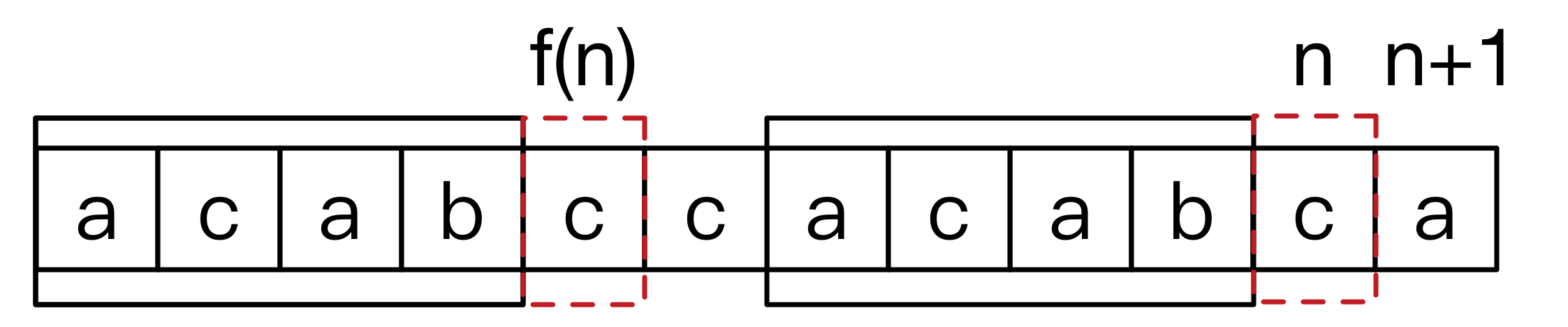
这种情况很显然, next[n + 1] = next[n] + 1 , 因为每往后一位,最长匹配前后缀 最多只能加1。
2. n + 1 != next[n]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ww4gHVd3-1636740373340)(https://blog.sengxian.com/images/kmp/k6.png)]
在图中,表现为 a != c ,这时候怎么办呢,我们会匹配 next[next[n]] ,此时匹配 a == a ,发现是匹配的,于是 next[n + 1] = next[next[n]] = 3 。
为什么会这样呢,我们看向上图,第一次匹配的时候我们发现 粉色 方框内的字符串是 n n n 之前的 最长匹配前后缀 ,而我们的 n + 1 n+1 n+1不能进行情况1那样的对前一个 最长匹配前后缀 的延长,我们退而求其次,发现粉色框中,四个蓝色框是匹配的,因为粉色 = 粉色,而蓝色属于粉色内的 最长匹配前后缀, 所以四个蓝色也相等。我们便如此递推,直到第三种情况。
3. next[n + 1] = 1
如果n + 1前没有 最长匹配前后缀, 那我们只好重头匹配了,于是next[n + 1] = 1 。
三、总结
KMP算法的精髓在于对已知信息的充分利用,这体现在待匹配串的匹配上面,更用于预处理时自己匹配自己上面,总而言之,KMP算法是非常值得学习的。
代码实现
#include <iostream>
using namespace std;
const int N = 100010, M = 1000010;
int n, m;
int ne[N];
char s[M], p[N];
int main()
{
cin >> n >> p + 1 >> m >> s + 1;
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
for (int i = 1, j = 0; i <= m; i ++ )
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == n)
{
printf("%d ", i - n);
j = ne[j];
}
}
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









