




 本文深入解析HTTP响应机制,涵盖响应行、响应头与响应体的设置方法,探讨编码问题及中文文件下载的处理策略,旨在帮助开发者掌握Response核心操作。
本文深入解析HTTP响应机制,涵盖响应行、响应头与响应体的设置方法,探讨编码问题及中文文件下载的处理策略,旨在帮助开发者掌握Response核心操作。
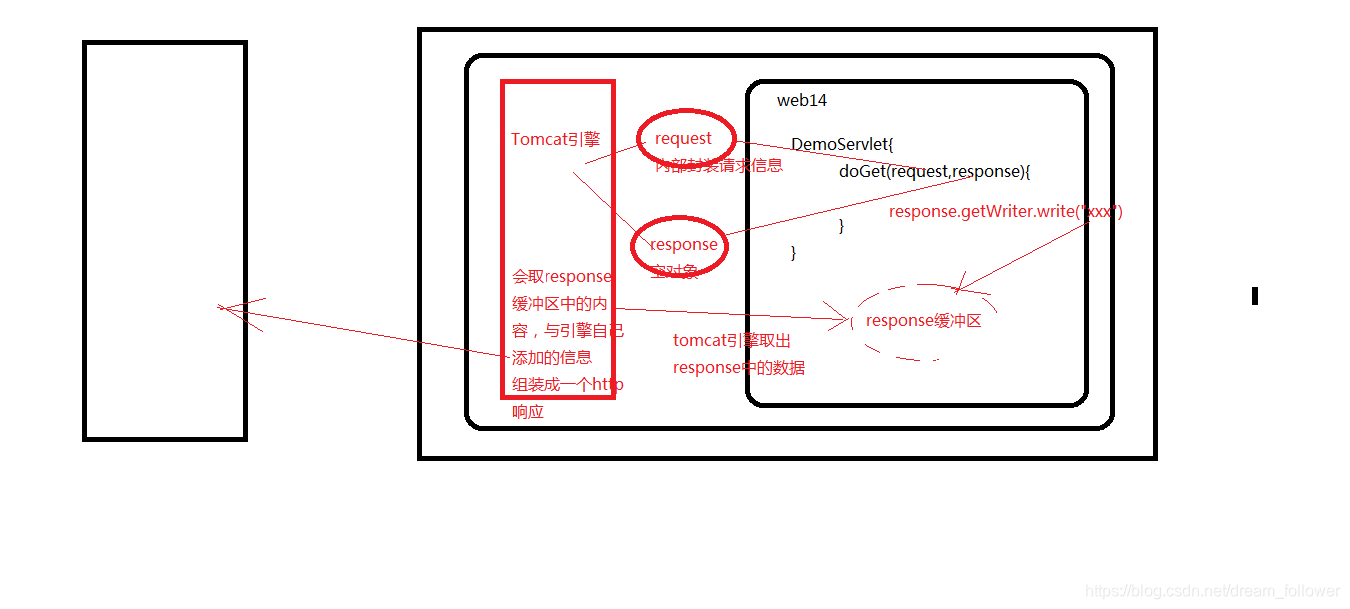
response的运行流程
response设置响应行
response设置响应行状态码
setStatus(int sc);
response设置响应头
addHeader(String name, String value)
addIntHeader(String name, int value)
addDateHeader(String name, long date)
setHeader(String name, String value)
setDateHeader(String name, long date)
setIntHeader(String name, int value)
add和set的区别就是:add是添加,如果里面已经有了一个标签,它会再加一个,而set是修改它的值。
response设置响应体文本
设置响应体文本
PrintWriter getWriter()
获得字符流,通过字符流的write(String s)方法可以将字符串设置到response 缓冲区中,随后Tomcat会将response缓冲区中的内容组装成Http响应返回给浏览 器端。
关于设置中文的乱码问题
原因:response缓冲区的默认编码是iso8859-1,此码表中没有中文,可以通过 response的setCharacterEncoding(String charset) 设置response的编码
但我们发现客户端还是不能正常显示文字
原因:我们将response缓冲区的编码设置成UTF-8,但浏览器的默认编码是本地系 统的编码,因为我们都是中文系统,所以客户端浏览器的默认编码是GBK,我们可以 手动修改浏览器的编码是UTF-8。
我们还可以在代码中指定浏览器解析页面的编码方式,
通过response的setContentType(String type)方法指定页面解析时的编码是UTF-8
response.setContentType(“text/html;charset=UTF-8”);
上面的代码不仅可以指定浏览器解析页面时的编码,同时也内含 setCharacterEncoding的功能,所以在实际开发中只要编写 response.setContentType(“text/html;charset=UTF-8”);
设置响应体字节
ServletOutputStream getOutputStream()
获得字节流,通过该字节流的write(byte[] bytes)可以向response缓冲区中写入字 节,在由Tomcat服务器将字节内容组成Http响应返回给浏览器。
response 细节点
- response获得的流不需要手动关闭,Tomcat容器会帮助我们关闭
- getWriter和getOutputStream不能同时调用
下载文件的案例
//获得要下载的文件的名称
String filename=request.getParameter("filename");
//解决文件的中文乱码
filename=new String(filename.getBytes("ISO8859-1"),"utf-8");
//获得请求头中的user-agent
String agent=request.getHeader("User-Agent");
String filenameEncoder="";
if (agent.contains("MSIE")) {
// IE浏览器
filenameEncoder = URLEncoder.encode(filename, "utf-8");
filenameEncoder = filenameEncoder.replace("+", " ");
} else if (agent.contains("Firefox")) {
// 火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filenameEncoder = "=?utf-8?B?"
+ base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filenameEncoder = URLEncoder.encode(filename, "utf-8");
}
//要下载文件的文件类型
response.setContentType(this.getServletContext().getMimeType(filename));
//告诉客户端文件不是直接解析而是下载
response.setHeader("Content-Disposition", "attachment;filename="+filenameEncoder);
//获得该文件的绝对路径
String path=this.getServletContext().getRealPath("download/"+filename);
//获得该文件的输入流
System.out.println(path);
InputStream in=new FileInputStream(path);
//获得输出流
ServletOutputStream out=response.getOutputStream();
//文件拷贝
int len=0;
byte[] buffer=new byte[1024];
while((len=in.read(buffer))>0){
out.write(buffer,0,len);
}
in.close();
out.close();
下载中文文件,页面在下载时会出现中文乱码或不能显示文件名的情况, 原因是不同的浏览器默认对下载文件的编码方式不同,ie是UTF-8编码方式,而火狐 浏览器是Base64编码方式。所里这里需要解决浏览器兼容性问题,解决浏览器兼容 性问题的首要任务是要辨别访问者是ie还是火狐(其他),通过Http请求体中的一 个属性可以辨别,通过User-Agent属性


















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











