




 本文探讨了在机器学习中处理缺失值的各种方法,包括删除、填充固定值、平均值、中位数、众数填充等,并通过泰坦尼克号数据集示例,展示了如何使用pandas和missingno进行缺失值的统计与可视化。
本文探讨了在机器学习中处理缺失值的各种方法,包括删除、填充固定值、平均值、中位数、众数填充等,并通过泰坦尼克号数据集示例,展示了如何使用pandas和missingno进行缺失值的统计与可视化。
机器学习中缺失值处理小记。样例采用的是kaggle 泰坦尼克号数据。
发现缺失值
使用pandas统计
data = pd.read_csv(pathUtil.train_path)
print(data.isnull().sum())
==>
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
使用可视化的第三方库missingno
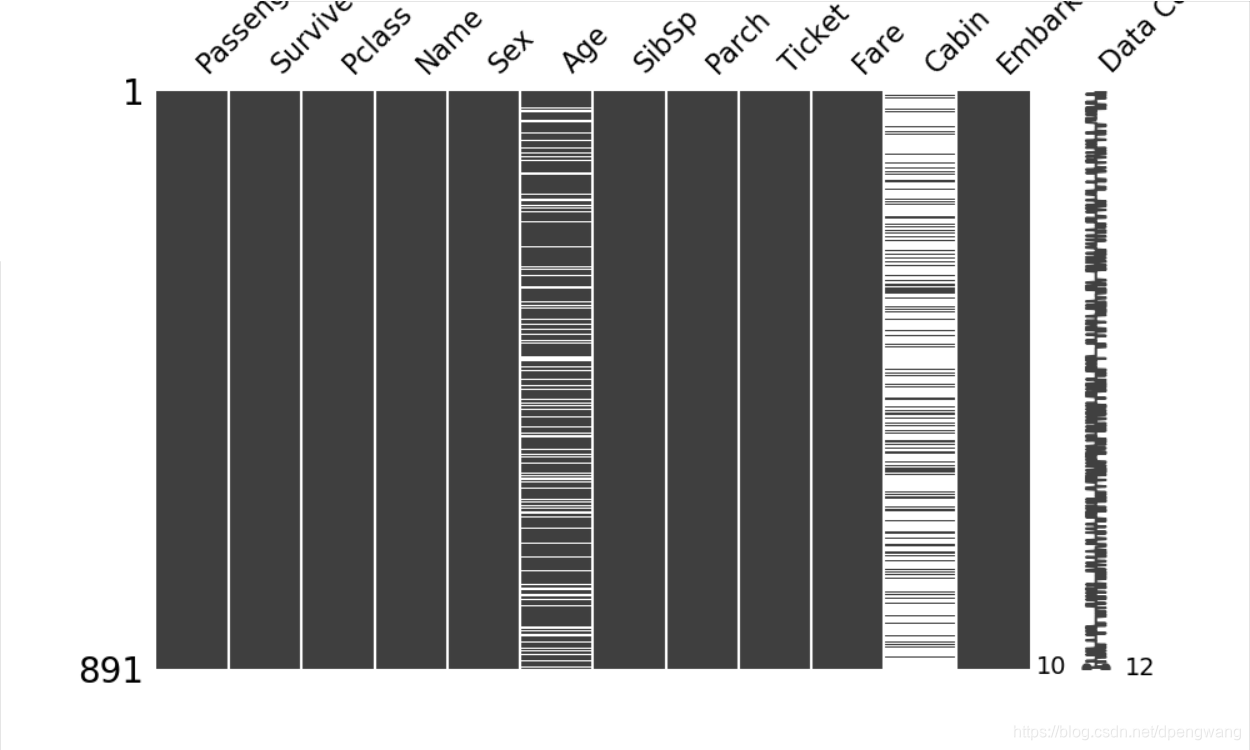
矩阵图
白色表示数据缺失,最右侧的一列,表示每一行的数据完整程度
data = pd.read_csv(pathUtil.train_path)
msno.matrix(data,labels=True,figsize=(10,6))
plt.show()
柱状图
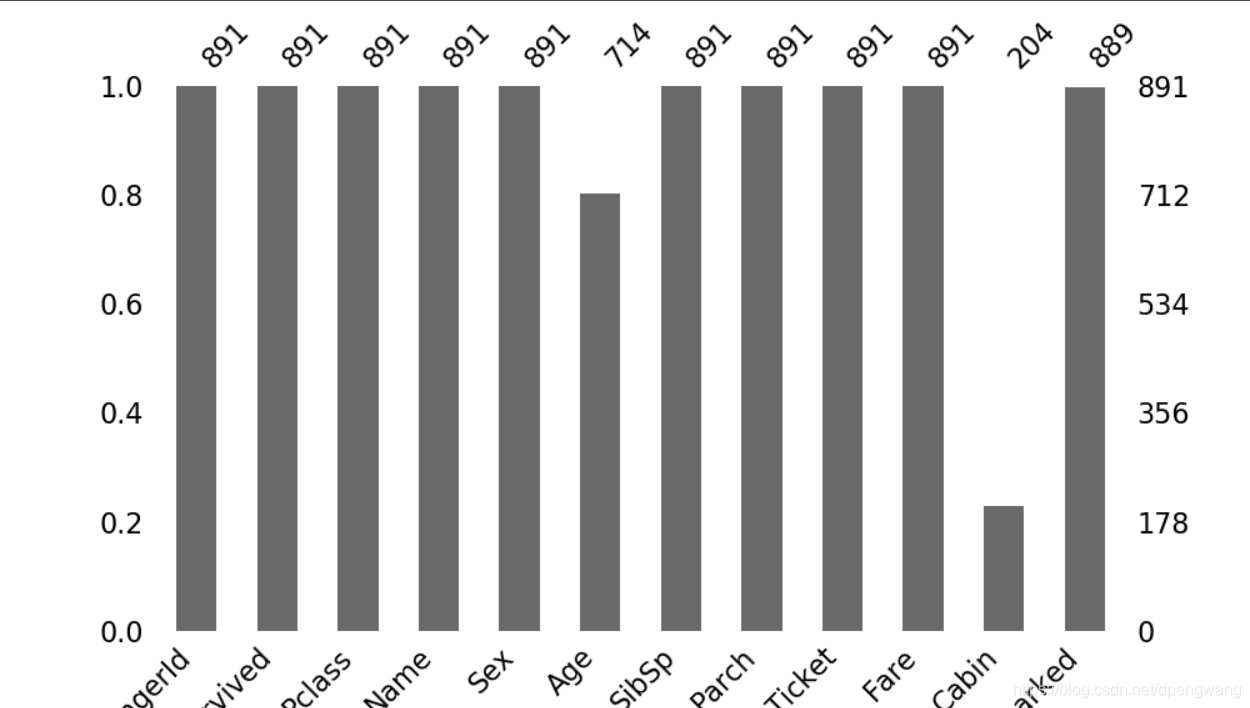
还有其他的方法,需要使用的话查官方文档
缺失值的处理
这里为了显示方便,我们只取两个属性,离散的Cabin和连续的Age属性。
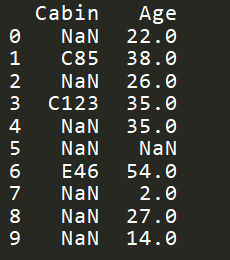
1)删除法
如果一列中的缺失值太多,比如缺失比列超过了80%那么我们可以把该属性删除,有时可以获得很好的提升效果
2)固定值填充
data["Age"].fillna(0,inplace=True)
3) 平均值填充
data["Age"].fillna(data["Age"].dropna().mean(),inplace=True)
4)中位数填充
data["Age"].fillna(data["Age"].dropna().median(),inplace=True)
5)众数填充
data["Age"].fillna(data["Age"].dropna().mode(),inplace=True)
6)上一条、下一条数据填充
用上一条不为NaN的数据填充,如果上面没有不为N的数据,那么还是NaN
data["Age"].fillna(method="pad",inplace=True)
data["Age"].fillna(method="bfill",inplace=True)
用这种方法填充以后建议再使用一次fillna填充一个常数值,因为填充完还有可能出现NaN的情况。
7)还有其他比较复杂的方法比如KNN聚类,模型预测等等,上面的几种方法比较常用,一行代码基本就能搞定。
下面几点要注意:
- 上述几种方法要注意的是,只有众数方法mode能对离散值使用,其他的不行。在求中位数、众数、平均值的时候最好先dropna()再求。
- 在使用mode()方法时,返回的可能是一个list,所以后面最好加个
[0],不加 话填充的结果可能还是NaN - 不建议使用整个df.fillna()方法,建议一列列的填充


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









