




代码来自《Linux高新能服务器编程》
#include<stdio.h>
void byteorder()
{
union
{
short value; // short为2个字节,共16位
char union_bytes[sizeof(short)];
}test;
test.value = 0x0102;
if((test.union_bytes[0] == 1) && (test.union_bytes[1]==2))
{
printf("big endian\n");
}
else if((test.union_bytes[0] == 2) && (test.union_bytes[1]==1))
{
printf("little endian\n");
}
else
{
printf("unknown......\n");
}
}
int main()
{
byteorder();
char a[2] = {0x01, 0x02};
printf("a[0]: %d\n", a[0]);
printf("a[1]: %d\n", a[1]);
printf("add of a[0]: %d\n", &a[0]);
printf("add of a[1]: %d\n", &a[1]);
return 0;
}
输出结果:
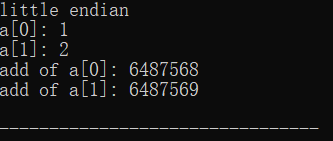
解释:
1.声明了一个共用体类型,其数据成员为short类型的value和一个sizeof(short)长度的字符数组。
2.声明了一个共用体变量test
3.初始化test的value成员为0x0102
4.使用test的字符数组判断该主机使用的字节序类型。由于共用体的所有成员占用同一块内存,通过某个成员修改内存中的值会影响其他成员的值,因此字符数组的值实际上是0x0102保存在内存中的值,至于是以哪种字节序保存的还不知道,有可能在内存中0x0102是以0000 0001 0000 0010保存的,
也可能是0000 0010 0000 0001保存的。
5.由于char是一个字节,所以每个char[i]占用一个字节,即8位。在这个例子中,union_bytes[0]要么是0x01,要么是0x02,取决于主机使用的字节序,根据union_bytes[0]和union_bytes[1]的值就可以判断主机所使用的字节序了。
6.注意union_bytes[0]和union_bytes[1]所在的内存的地址union_bytes[1]要高一些。
7.char union_bytes[sizeof(short)]暗含sizeof(short)为常量表达式。

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









