



1.通过页表机制,操作系统为每个进程提供各自私有的地址空间和内存.页表决定了内存地址的含义,以及物理内存的哪些部分可以被访问.它们允许xv6隔离不同进程的地址空间,并将它们映射到物理内存上.页表还提供了一个间接层次,允许xv6实现一些技巧:在几个地址空间中映射同一内存(trampoline页),以及用一个未映射页来保护内核栈和用户栈.本章其余部分将解释RISCV硬件提供的页表以及xv6如何使用它们.
Paging hardware
提醒一下,RISCV指令(包括用户和内核)操作的是虚拟地址.机器的RAM,或者说物理内存,是用物理地址来做索引的.RISCV的页表硬件通过将每个虚拟地址映射到一个物理地址将这两种地址联系起来.
xv6运行在Sv39RISCV上,这意味着只会使用64位虚拟地址的低39位,高25没有被使用.在这种Sv39配置中,一个RISCV页表在逻辑上是由2^27次方(134217728)个页表项(Page Table Entry,PTE)组成的数组.每个PTE包含一个44位的物理页号(Physical Page Number,PPN)和一些标志位.分页硬件通过利用39位中的高27位所引导页表中找到一个PTE来转换一个虚拟地址,并计算出一个56位的物理地址,它的前44位来自PTE中的PPN,而它的后12位则是原来虚拟地址复制过来的.图显示了这个过程,在逻辑上可以把页表看成是一个简单的PTE数组.页表让操作系统控制虚拟地址到物理地址的转换,其粒度位4096(2^12)字节的对其块.这样的分块称为页.
在Sv39RISCV中,虚拟地址的高25位不用地址转换;将来,RISCV可能会使用这些位来定义跟多的转换层.物理地址也有增长空间;在PTE格式中,物理页号还有10位的增长空间.
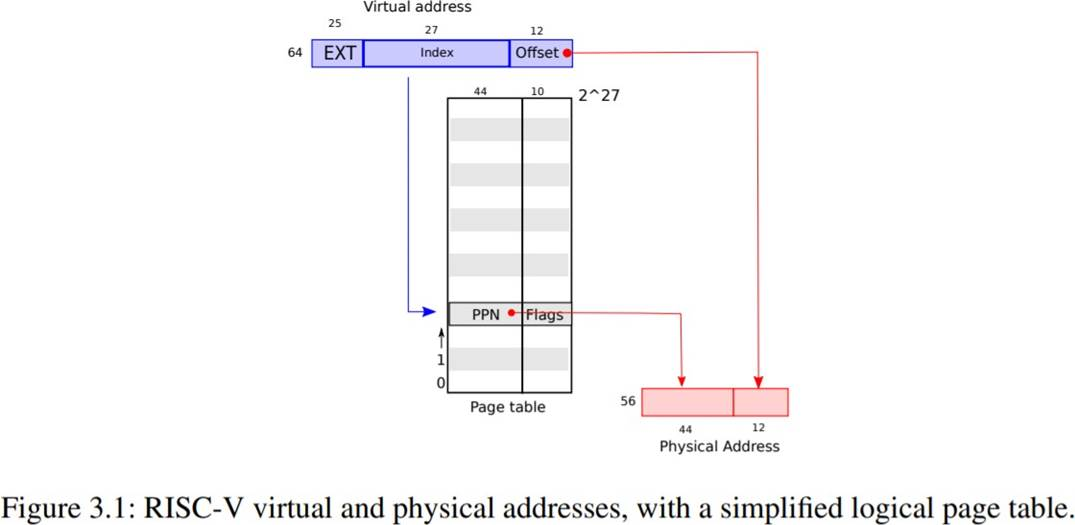
如图所示,实际上转换过程分三步进行,一个页表以三层树的形式存储在物理内存中.树的根部是一个4096字节的页表页,它包含512个PTE,这些PTE包含树的下一级页表页的物理地址.每一页都包含512个PTE,用于指向下一个页表或者物理地址.分页硬件用27位中的高9位选择根页表页中的PTE,用中间9位选择树种下一级页表页中的PTE,用低9位选择最后的PTE.
如果转换一个地址所需的三个PTE中任何一个不存在,分页硬件就引发一个缺页异常(page-fault exception).让内核来处理这个异常.这种三层结构允许页表在处理大范围的虚拟地址没有被映射的这种常见情况时,能够忽略整个页表.
每个PTE都包含标志位,用于告诉分页硬件相关的虚拟地址被允许怎样使用.PTE_V表示PTE是否存在:如果没有设置,对该页的引用会引起异常(即不允许).PTE_R控制是否允许指令读取该页.PTE_W控制是否允许指令向该页写入.PTE_X控制CPU是否可以将页面的内容解释为指令并执行.PTE_U控制是否允许用户态下的指令访问页面;如果不设置PTE_U,对应PTE只能在内核态下使用.图显示了这一切的工作原理.标志位和与分页硬件相关的数据结构定义在(kernel/riscv.h)中.
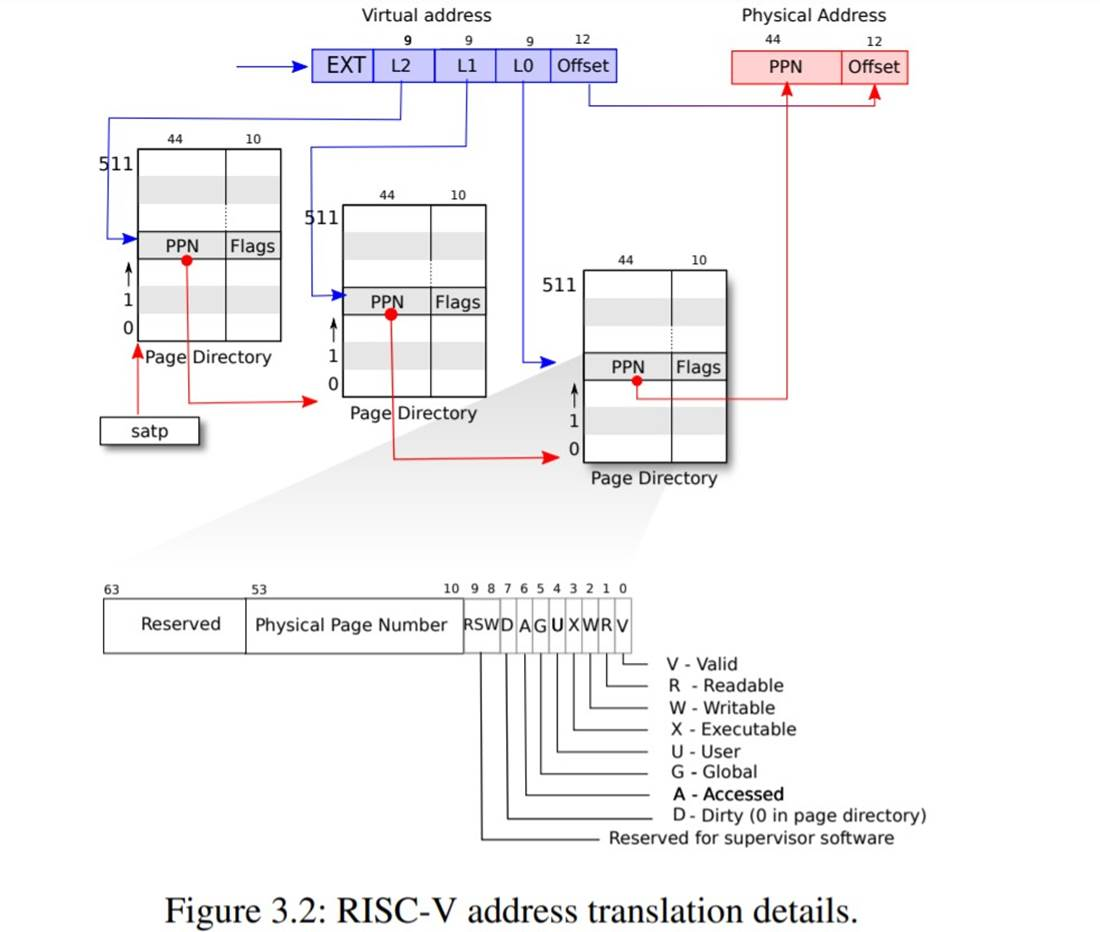
要告诉硬件使用一个页表,内核必须将对应根页表页的物理地址写入satp寄存器中.每个CPU都有自己的satp寄存器.一个CPU将使用自己的satp所指向的页表来翻译后续指令产生的所有地址.每个CPU都有自己的satp,这样不同的CPU可以运行不同的进程,每个进程都有自己的页表所描述的私有地址空间.
关于术语的一些说明:物理内存指的是DRAM中的存储单元.物理存储器的一个字节有一个地址,称为物理地址.当指令操作虚拟地址时,分页硬件会将其翻译为物理地址,然后发送给DRAM硬件,以读取或写入存储,不像物理内存和虚拟地址,虚拟内存不是一个物理对象,而是指内核提供的管理物理内存和虚拟地址的抽象和机制的集合.
Kernel address space
Xv6为每个进程维护一个用于描述进程的用户地址空间的页表,外加一个单独的描述内核地址空间的页表.内核配置其地址空间的布局,使其能够通过可预测的虚拟地址访问物理内存和各种硬件资源.图显示了这个设计是如何将内核虚拟地址映射到物理地址的.(kernel/memlayout.h)声名了xv6内核内存布局的常量.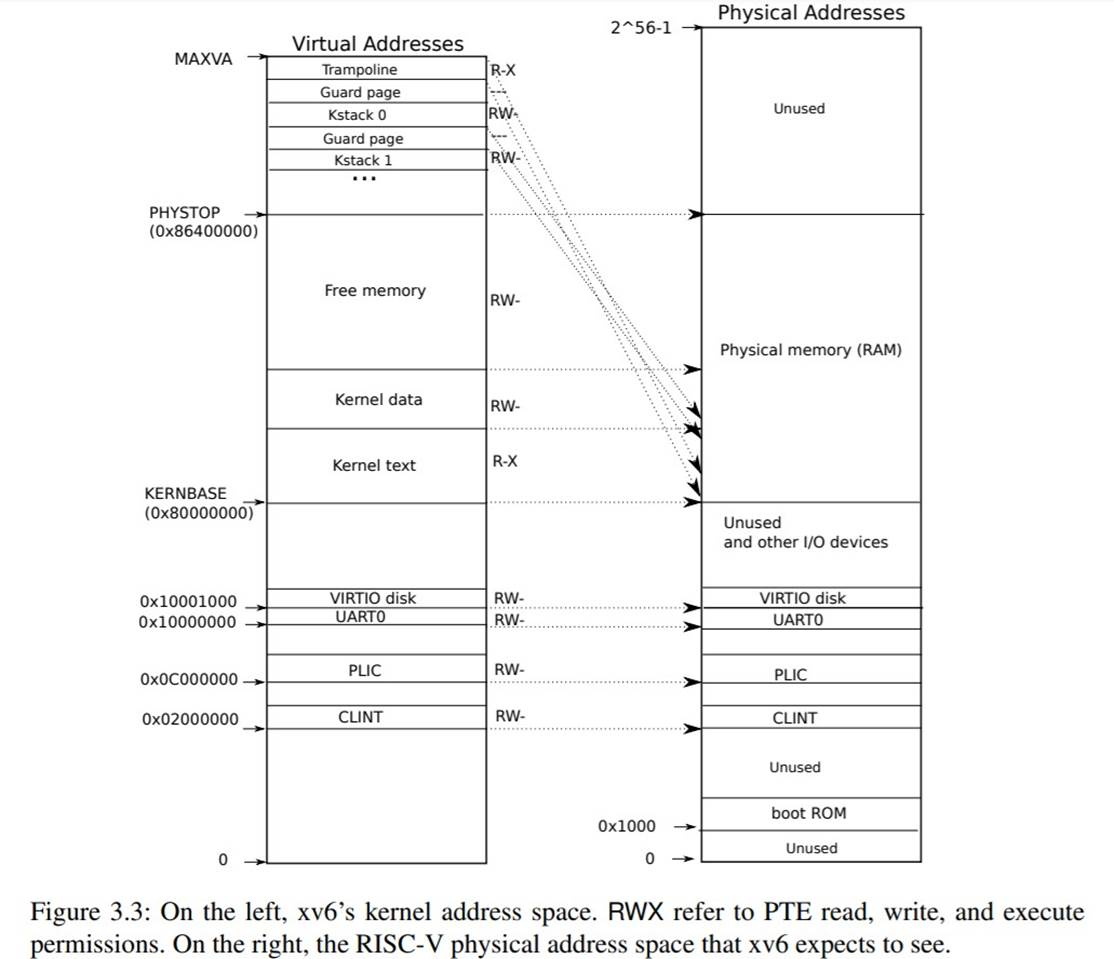
qemu模拟的计算机包含RAM(物理内存),从物理地址0x80000000开始,至少到0x86400000,xv6称之为PHYSTOP.qemu模拟还包括IO设备,如磁盘接口.qemu将设备接口作为内存映射(memory-mapped)的控制寄存器暴漏给软件,这些寄存器位于物理地址空间的0x80000000以下.内核可以通过读取/写入这些特殊的物理地址与设备进行交互;这种读取和写入与设备硬件而不是与RAM进行通信.第四章解释了xv6如何与设备交互.
内核对RAM和内存映射的设备寄存器使用"直接映射",也就是将这些资源映射到和它们物理地址相同的虚拟地址上.例如,内核本身在虚拟地址空间和物理内存中位置都是KERNBASE=0x80000000.直接映射简化了读写物理内存的内核代码.例如,当fork为子进程分配用户内存时,分配器返回该内存的物理地址;fork在将父进程的用户内存复制到子进程时,直接使用该地址作为虚拟地址.
有几个内核虚拟地址不是直接映射:
trampoline页.它被映射在虚拟地址空间的顶端;用户页表也有这个映射.第四章讨论了trampoline页的作用,但我们在这里看到了页表的一个有趣的用例;一个物理页(存放trampline代码)在内核的虚拟地址空间被映射了两次;一次是在虚拟地址空间的顶部,一次是直接映射.
内核栈页.每个进程都有自己的内核栈,内核栈被映射到高地址处,所以xv6可以在他后面留下一个未映射的守护页.守护页的PTE是无效的(不设置PTE_V位),这样如果内核栈溢出,很可能会引起异常,内核会报错.如果没有防护页,栈溢出时会覆盖其他内核内存,导致不正确的操作.报错还是比较好的.
内核通过高地址映射使用它的占空间.栈空间也可以通过直接映射的地址被内核访问.另一种的设计是只使用直接映射,并在直接映射的地址上使用stack.但是在这种安排上,提供保护页将涉及到取消映射虚拟地址,否则这些地址将指向物理内存,这将很难用.
内核将trampoline和text(可执行程序的代码段)映射为有PTE_R和PTE_X权限的页.内核从这些页读取和执行指令.内核映射的其他页会有PTE_R和PTE_W的权限,以便内核读写这些页面的内存.守护页的映射是无效的(不设置PTE_V).
Code: creating and address space
大部分用于操作地址空间和页表的xv6代码都在vm.c(kernel/vm.c:1)中.核心数据结构是pagetable_t,它实际上是一个指向RISCV根页表页的指针;pagetable_t可以是内核页表,也可以是进程的页表.核心函数是walk和mappages,前者通过虚拟地址是得到PTE,后者将虚拟地址映射到物理地址.以kvm开头的函数操作内核页表;以uvm开头的函数操作用户页表;其他函数同时用于这两种页表.copyout和copyin将数据复制到或复制出被作为系统调用参数的用户虚拟地址;它们在vm.c中,因为它们需要显式转换用户空间的地址,以便找到相应的物理内存.
在机器启动时,在启动序列的靠前部分,main调用kvminit(kernel/vm.c:22)来创建内核页表.这个调用发生在xv6在RISCV启用分页之前,所以地址直接指向物理内存.kvminit首先分配一组物理内存来存放根页表页.然后调用kvmmap将内核所需要的硬件资源映射到物理地址.这些资源包括内核的指令和数据,KERNBASE到PHYSTOP的物理内存,以及实际上是设备的内存范围.
kvmmap(kernel/vm.c:118)调用mappages(kernel.vm.c:149),它将指定范围的虚拟地址映射到一段物理地址.它将范围内地址分割成页(忽略页数),每次映射一页的起始地址.杜宇每个要映射的虚拟地址(页的起始地址),mapages调用walk找到该地址的最后一级PTE的地址.然后,它配置PTE,使其保持相关的物理页号,所需的权限(PTE_W,PTE_X,PTE_R),以及来标记PTE为有效(kernel/vm.c:161).
walk(kernel/vm.c:72)模仿RISCV分页硬件查找虚拟地址的PTE.walk每次降低9位来查找三级页表.它使用每一级的9位虚拟地址来查找下一级页表或最后一集(kernel/vm.c:78)的PTE.如果PTE无效,那么所需的物理页还没有被分配;如果alloc参数被设置,walk会分配一个新的页表页,并把它的物理地址放到PTE中.它返回树中最底层PTE的地址(kernel/vm.c:88).
main调用kvminithart(kervel/vm.c:53)来映射内核页表.它将根页表的物理地址写入寄存器satp中.在这之后,CPU将使用内核页表翻译地址.由于内核使用唯一映射,所以指令的虚拟地址将映射到正确的物理内存地址.
procinit(kernel/proc.c:26),它由main调用,为每个进程分配一个内核栈.它将每个栈映射在KSTACK生成的虚拟地址上,这就为栈守护页留下了空间.kvmmap将对应的PTE加入到内核页表中,然后调用kvminithart将内核页表重新加载到satp中,这样硬件就知道新的PTE了.
每个RISCV CPU都会在Translation Look-aside Buffer(TLB)中缓存页表项,当xv6改变页表时,必须告诉CPU使相应的缓存TLB项无效.如果它不这样做,那么在以后的某个时刻,TLB可能会使用一个旧的缓存映射,指向一个物理页,而这个物理页在此期间已经分配给了另一个进程,这样的话,一个进程可能会在其他进程的内存上乱写乱画.RISCV有一掉指令sfence.vma,可以刷新当前CPU的TLB.xv6在kvminithart中,重新加载satp寄存器后,执行sfence.vma,也就会在内核空间返回用户空间前,切换到用户页表的trampoline代码中执行sfence.mva(kernel/tarmpoline.S:79)
Physical memory allocation
内核必须在运行时为页表,用户内存,内核堆栈和管道缓冲区分配和释放物理内存.xv6使用内核地址结束到PHYSTOP之间的物理内存来进行运行时分配,它每次分配和释放整个4096字节的页面.它通过保存空闲链表页,来记录哪些页是空闲的.分配包括从链表中删除一页;释放包括将释放的页面添加到空闲链表页中.
Code: Physical memory allocator
分配器在kalloc.c(kernel/kalloc.c:1)中.分配器的数据结构是一个可供分配的物理内存页的空闲链表,每个空闲页的链表元素是一个结构体struct run(kernel/kalloc.c:17).分配器是从哪里获得内存来存放这个结构体呢?他把每个空闲页的run结构体存储在空闲页自身里面,因为哪里没有其他东西存储.空闲列表由一个自旋锁保护(kernel/kalloc.c:21-24).链表被锁包裹在一个结构体中,明确锁保护的是结构体中的字段.现在,请忽略锁以及acquire和release的调用;第六章将详细研究锁.
main调用kinit来初始化分配器(kernel/kalloc.c:27).kinit初始化空闲页链表,以保存内核地址结束到PHYSTOP之间的每一页.xv6应该通过解析硬件提供的配置信息来确定有多少物理内粗可用.但是它并没有这么做,而是假设机器有128M字节对齐的物理地址(4096的倍数),因此freerange使用PGOUNDUP来确保它只添加对齐的物理地址到空闲链表中.分配器开始时没有内存;这些对kfree的调用给了他一些内存管理.
分配器有时把地址当作整数来处理,以便对其进行运算(如freerange遍历所有页),有时把地址作为指针来读写内存(如操作存储在每页中的run结构体);这种对地址的双重使用是分配器代码中充满C类型转换的主要原因.另一个原因是,释放和分配本质上改变了内存的类型.
kfree(kernel/kalloc.c:47)将被释放的内存中的每个字节设置为1.这将使得释放内存后使用内存的代码(使用悬空引用)将会读取垃圾而不是旧的有效内容;希望浙江导致这类代码更快地崩溃.然后kfree将页面预存入释放列表:它将pa(物理地址)转换为指向结构体run的指针,在r->next中记录空闲链表之前的节点,并将释放列表设为r.kalloc移除并返回空闲链表中的第一个元素.
Process address space
每个进程都有一个单独的页表,当xv6在进程间切换时,也会改变页表.如图,一个进程的用户内存从虚拟地址0开始,可以增长到MAXVA(kernel/riscv.h:348),原则上允许一个进程寻址256GB的内存.
当一个进程要求xv6提供更多的用户内存时,xv6首先使用kalloc来分配物理页,然后将指向新物理页的PTE添加到进程的页表中.Xv6设置这些PTE的PTE_W,PTE_X,PTE_R.PTE_U和PTE_V标志.大多数进程不使用整个用户地址空间;xv6将不适用的PTE的PTE_V位保持为清楚状态.
我们在这里看到了几个有趣的例子,是关于使用页表的.首先,不同的进程页表将用户地址转化为物理内存的不同页,这样每个进程都有私有的用户内存.第二,每个进程都认为自己的内存具有从0开始的连续的虚拟地址,而进程的物理内存可以是不连续的.第三,内核会映射带有trampoline的代码的页到用户地址空间顶端,因此,有一物理内存页在所有地址空间中都会出.
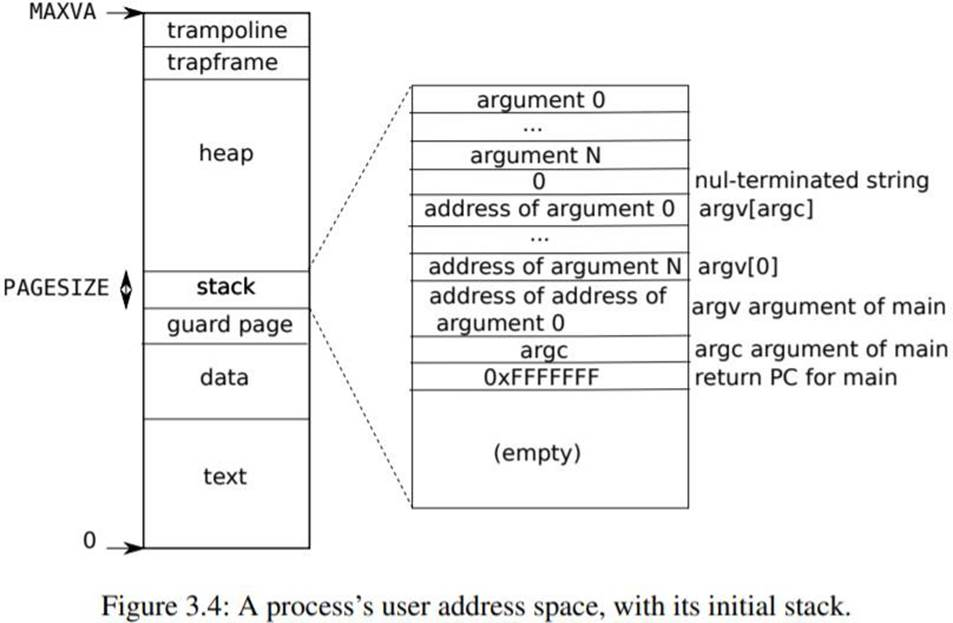
图更详细的显示了xv6中执行进程的用户内存布局.栈只有一页,途中现实的是由exec创建的初始内容.位于栈顶部的字符串中包含了命令行中输入的参数和指向他们的指针数组.在下方是允许程序在main启动的指,就像函数main(argc,argv)是刚刚被调用一样.
;为了检测用户栈溢出分配的栈内存,xv6会在stack的下方放一个无效的保护页.如果用户栈溢出,而进程视图使用栈下面的地址,硬件会因为该映射无效而产生一个缺页异常.一个现实世界中的操作系统可能会在用户栈溢出时自动为其分配更多的内存.
Code: sbrk
sbrk是一个进程收缩或增长内存的系统调用.该系统调用由函数growproc(kernel/proc.c:239)实现,growproc调用uvmalloc或者uvmdealloc,取决于n是正数还是负数.uvmalloc(kernel/vm.c:229)通过kalloc分配物理内存,并使用mappages将PTE添加到用户页表中.uvmdealloc调用uvmunmap(kernel/vm.c:174),它使用walk来查找并使用kfree来释放它们所引用的物理内存.
xv6使用进程的页表不仅是为了告诉硬件如何映射用户虚拟地址,也是将其作为分配给该进程的物理地址的唯一记录.这就是为什么释放用户内存(uvmunmap中)需要检查用户页表的原因.
Code: exec
exec是创建一个地址空间的用户部分的系统调用.它读取存储在文件系统山的文件来初始化第一个地址空间的用户部分.exec(kernel/exec.c:13)使用namei(kernel/exec.c:26)打开二进制文件路径,这个在第八章中有解释.然后,它读取ELF头.xv6应用程序用ELF格式来描述可执行文件,它定义在(kernel/elf.h).一个ELF二进制文件包括一个ELF头,struct elfhdr (kernel/elf.h:6).之后是一串程序段头(program section header),struct proghdr(kernel/elf.h:3)开始.如果ELF头有正确的魔法数字,exec就会认为该二进制文件是正确的类型.
exec使用proc_pagetable(kernel/exec.c:38)分配一个没有使用的页表,使用uvmalloc(kernel/exec.c:52)位每一个ELF段分配地址,使用loadseg(kernel/exec.c:10)加载每一个段到内存中.loadseg使用walkaddr找到分配内存的物理地址,再改地址写入ELF段的每一页,页的内容通过readi从文件中读取.
用exec创建的第一个用户程序/init的程序段头是这样的:
# objdump -p _init
user/_init: file format elf64-littleriscv
Program Header:
LOAD off 0x00000000000000b0 vaddr 0x0000000000000000
paddr 0x0000000000000000 align 2**3
filesz 0x0000000000000840 memsz 0x0000000000000858 flags rwx
STACK off 0x0000000000000000 vaddr 0x0000000000000000
paddr 0x0000000000000000 align 2**4
filesz 0x0000000000000000 memsz 0x0000000000000000 flags rw-程序端头的filesz可能小于memsz,说明它们之间的间隙应该用0来填充(对于C语言中的全局变量),而不是从文件中读取.对于/init来说,filesz是2112字节,memsz是2136字节,因此uvmalloc分配了足够的物理内存来容纳2136字节,但只从文件/init中读取2112字节.
exec在栈的下方放置了一个不可访问页,这样程序如果视图使用多个页面,就会出现故障.这个不可访问的页还能允许exec处理过大的参数;在这种情况下,exec用来复制参数到栈的copyout(kernel/vm.c:355)函数会注意到目标页不可访问,并返回-1.
在准备新的内存映像的过程中,如果exec检测到一个错误,比如一个无效的程序段,他就会跳转到标签bad,释放新的映像,并返回-1,exec必须延迟释放旧映像,直到它确定exec系统调用会成功:如果旧映像消失了,系统调用就不能返回-1,exec中唯一的错误情况发生在创建映像的过程中.一旦镜像完成,exec就可以提交到新的页表(kernel/exec.c:113)并释放旧的页表(kernel/exec.c:117).
exec将ELF文件中的字节按ELF文件指定的地址加载到内存中.用户或进程可以将任何他们想要的地址放入ELF文件中.因此,exec是有风险的,因为ELF文件中的地址可能会意外地或故意的指向内核.对于一个不小心的内核来说,后果可能从崩溃到而已颠覆内核的隔离机制(即安全漏洞).xv6执行了一些检查来避免这些风险.例如if(ph.vaddr + ph.mamsz < ph.mamsz)检查总和是否溢出一个64位整数.危险的是,用户可以用指向用户选择的地址的ph.vaddr和足够大的ph.memsz来构造一个ELF二进制,使总和溢出到0x1000,这看起来像是一个有效值.在旧版本的xv6中,用户地址空间也包括内核(但在用户模式下不可读写),用户可以选择一个对应内核内存的地址,从而将ELF二进制中的数据复制到内核中.在RISCV版本的xv6中,这是不可能的,因为内核有自己独立的页表;loadseg加载数据到进程的页表中,而不是内核的页表中.
内核开发人员很容易忽略一个关键的检查,现实中的内核有很长一段缺少检查的空档期, 用户程序可以利用缺少这些检查来获得内核特权。xv6 在验证需要提供给内核的用户程序数据的时候,并没有完全验证其是否是恶意的,恶意用户程序可能利用这些数据来绕过 xv6 的隔离。
Real world
像大多数操作系统一样,xv6 使用分页硬件进行内存保护和映射。大多数操作系统对分页的使用要比 xv6 复杂得多,它将分页和缺页异常结合起来,我们将在第 4 章中讨论。
Xv6 的内核使用虚拟地址和物理地址之间的直接映射,这样会更简单,并假设在地址0x8000000 处有物理 RAM,即内核期望加载的地方。这在 QEMU 中是可行的,但是在真实的硬件上,它被证明是一个糟糕的想法;真实的硬件将 RAM 和设备放置在不可预测的物理地址上,例如在 0x8000000 处可能没有 RAM,而 xv6 期望能够在那里存储内核。更好的内核设计利用页表将任意的硬件物理内存布局变成可预测的内核虚拟地址布局。
RISC-V 支持物理地址级别的保护,但 xv6 没有使用该功能。
在有大量内存的机器上,使用 RISC-V 对超级页(4MB 的页)的支持可能是有意义的。当物理内存很小的时候,小页是有意义的,可以对磁盘进行精细地分配和分页。例如,如果一个程序只使用 8 千字节的内存,那么给它整整 4 兆字节的超级物理内存页是浪费的。更大的页在有大量内存的机器上是有意义的,可以减少页表操作的开销。
xv6 内核缺乏一个类 malloc 的分配器为小程序提供内存,这使得内核没有使用需要动态分配的复杂数据结构,从而简化了设计。
内存分配是一个常年的热门话题,基本问题是有效利用有限的内存和为未来未知的请求做准备[2]。如今人们更关心的是速度而不是空间效率。此外,一个更复杂的内核可能会分配许多不同大小的小块,而不是(在 xv6 中)只分配 4096 字节的块;一个真正的内核分配器需要处理小块分配以及大块分配。

















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









