




one-hot编码
为什么要使用one-hot编码
https://blog.youkuaiyun.com/binlin199012/article/details/107341462/
损失函数
hθ(x)=g(θTx) h_{\theta}(x)=g\left(\theta^{T} x\right) hθ(x)=g(θTx)
J(θ)=−1m∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}\left[y^{(i)} \log \left(h_{\theta}\left(x^{(i)}\right)\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right]
J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
先关损失函数,包括负采样
https://carlos9310.github.io/2019/10/15/Approximating-the-Softmax/
上述为二分类的交叉熵损失函数,加负号是因为log得到的就算结果是负值。多分类的参考:
https://zhuanlan.zhihu.com/p/35709485
使用pytorch实现损失函数为:
https://www.cnblogs.com/peixu/p/13194801.htm
softmax函数
https://blog.youkuaiyun.com/lz_peter/article/details/84574716
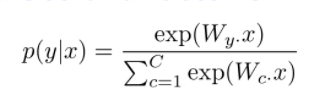
不同的激活函数
https://www.cnblogs.com/ya-qiang/p/9258714.html
如果没有激活函数,就不算神经网络,激活函数是为了增加网络的非线性。
** 选择激活函数的经验法则:** 如果输出是0,1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数。
https://blog.youkuaiyun.com/adolph_yang/article/details/78956987
BN层的作用
https://zhuanlan.zhihu.com/p/75603087(这篇知乎讲解的很仔细)

















 6994
6994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









