




LLM部署特点,内存开销大,TOKEN数量不确定

移动端竟然也可以部署LLM。之前以为只能在服务端部署,移动端作为客户端发起请求来调用大模型。

LMDeploy用于模型量化
模型量化:降低内存消耗
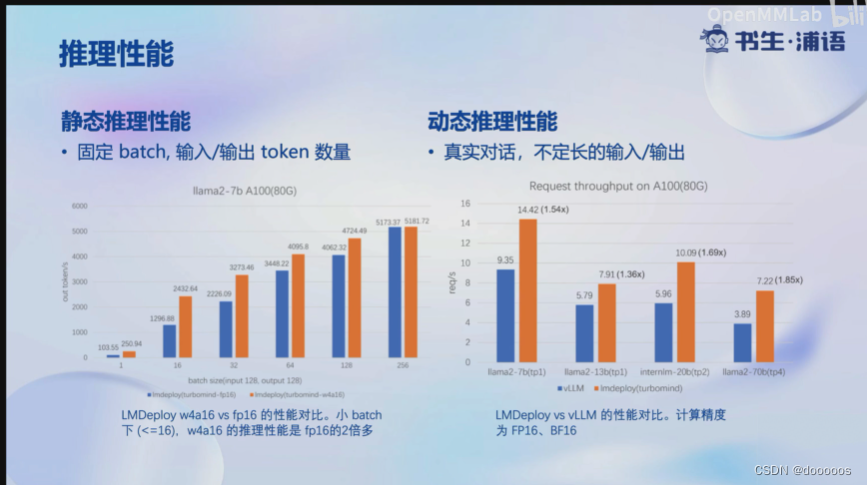
推理性能对比
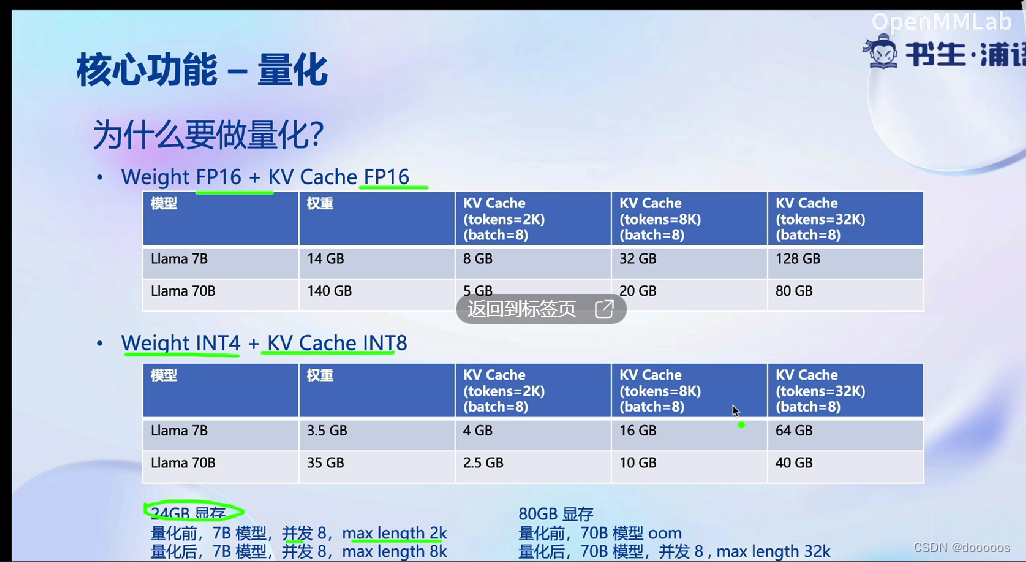
量化主要作用:降低现存开销
书生浦语大模型实战营-课程笔记(5)
最新推荐文章于 2025-12-29 11:31:51 发布
 本文探讨了LLM在移动端部署的新趋势,指出其内存开销大且TOKEN数量不确定性,同时介绍了模型量化的作用,旨在降低内存消耗并提升推理性能。
本文探讨了LLM在移动端部署的新趋势,指出其内存开销大且TOKEN数量不确定性,同时介绍了模型量化的作用,旨在降低内存消耗并提升推理性能。

















 2267
2267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









