







Antlr 常见的语言模式:
1)序列模式
ANTLR使用序列模式
rule : ID ':' alternative ('|' alternative)* ';';描述:匹配这样的结构: '规则名: ' 后面跟着至少一个备选分支,然后是若干条以 '|' 符号分隔的备选分支,最后一个';'
序列模式匹配Java结构:
stats : (stat ';')*描述:匹配零个或多个以';' 终止的语句
匹配以逗号分隔的多个表达式
exprList : expr (',' expr)* ;
2)选择模式(多个备选分支)
我们使用 | 符号作为“或者” 来表达编程语言中的选择模式,在ANTLR的规则中,它用于分隔多个可选的语法结构-称作备选分支
允许字段中出现整数或者字符串
field : INT | STRING ;3)词法符号依赖模式
vector : '[' INT+ ']'; //[1], [1 2], [1 2 3], ...描述:我们使用一个序列来指明所有配对的符号,通常这些符号会把其他元素分组或者包裹起来。
4)嵌套模式
嵌套的词组是一种自相似的语言结构,即它的子词组也遵循相同的结构。表达式是一种典型的自相似语言结构,它包含多个嵌套的、以运算符分隔的子表达式。在语法中,我们使用递归规则来表达这种这种自相似的语言结构。所以,如果一条规则定义中的伪代码引用了它自身,我们就需要一条递归规则(自引用规则)。
stat : 'while' '(' expr ')' stat //匹配WHILE语句
| '{' stat* '}'
...
;描述:一个while表达式由一个关键字while开始,后面是一个括号中的条件表达式,再后面就是一条语句。我们也可以把多个语句放入花括号中,当做一个“代码块语句”使用。其中,while 中stat是一个循环结构,它可以是一个语句或者花括号包裹的一组语句。因为stat规则在前两个备选分支中引用了自身,我们称它为直接递归(directly recursive)的。
如果我们将它的第二个备选分支抽取出来,stat规则和block规则就会互为间接递归(indirectly recursive)的。
stat: 'while' '(' expr ')' stat //匹配WHILE语句
| block //匹配一个语句组成的代码块
... //其他种类的语句
;
block: '{' stat* '}' ; //匹配花括号中若干条语句组成的代码块常见的计算机语言模式
| 模式名 | 描述 |
| 序列模式 | 它是一个有限长度或着任意长度的序列,序列中元素可以是词法符号或者子规则。序列模式的例子包括变量申明(类型后面紧跟着标识符)和整数序列,下面是范例实现: x y ... z //x 后面跟着 y, ..., z '[' INT ']' //Matlab 的整数向量 |
| 带终止符的序列模式 | 它是一个任意长的、可能为空的序列,该序列由一个词法符号分隔开通常是分号或者换行符,其中的元素可以是词法符号或者子规则。这样的例子包括类C语言的语句集合和一些用换行符来分隔的数据格式。下面是范例实现: (statement ';')* //Java 的语句集合 (row '\n')* //多行数据 |
| 带分隔符的序列模式 | 它是一个任意长的、可能为空的序列,该序列由一个词法符号分隔开,通常是分号或者换行符,其中的元素可以是词法符号或者子规则。这样的例子包括函数定义中的参数表、函数调用时传递的参数表、某些语句之间有分隔符却无终止符的编程语言,以及目录名。下面是范例实现: expr (' , ' expr)* //函数调用时传递的参数 ( expr (' , ' expr)*)? //函数调用时传递的参数是可选的 '/'?name ('/' name) * //简化的目录名 stat ('.' stat)* //若干个SmallTalk 语句 |
| 选择模式 | 它是一组备选分支的集合。这样的例子包括不同种类的类型、语句、表达式或者 XML标签。下面是范例实现: type : 'int' | 'float'; stat : ifstat | whilestat | 'return' expr ';' ; expr : '(' expr ')' | INT | ID; tag : '<' Name attibute* '>' | '<' '/' Name '>' ; |
| 词法符号依赖 | 一个词法符号需要和一个或者多个后续词法符号匹配。这样的例子包括配对的圆括号、花括号、方括号和尖括号。下面是范例实现: '(' expr ')' //嵌套表达式 ID '[' expr ']' //数组索引表达式 '{' stat* '}' //花括号包裹的若干个语句 '<' ID (',' ID)* '>' //泛型声明 |
| 嵌套模式 | 它是一种自相似的语言结构。这样的例子包括表达式、java的内部类、嵌套代码块以及嵌套的Python函数定义。下面是范例实现: expr : '(' expr ')' | ID; classDef: 'class' ID '{' (classDef | method| field) '}' ; |
Antlr 处理优先级、左递归和结合性
大多数语言规范使用了一种特殊的递归方式,称为左递归(left recursion)。自顶向下的语法和语法分析器的经典形式无法处理左递归。
例如:
对于 1 + 2 * 3 这样的输入而言,上述规则能用两种方式解释它
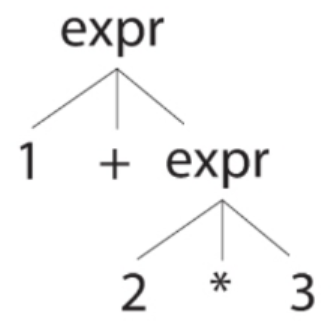
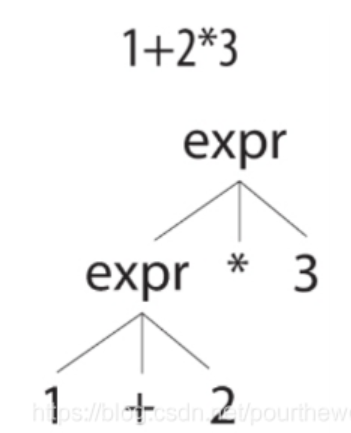
Antlr 通过优先选择位置靠前的备选分支来解决歧义问题,这隐式地允许我们指定运算符优先级。
例如:expr 规则中,乘法规则在加法规则之前,所以ANTLR在解决 1+2*3的歧义问题时会优先处理乘法。
grammar expr;
/**起始规则,语法分析的起点**/
prog: stat+;
stat: expr NEWLINE
| NEWLINE
;
expr : expr '*' expr //乘法规则在加法规则之前
| expr '+' expr
| INT
;
INT: [0-9]+;
MUL : '*';
DIV : '/';
ADD : '+';
SUB : '-';
NEWLINE: '\r'? '\n';语法树:
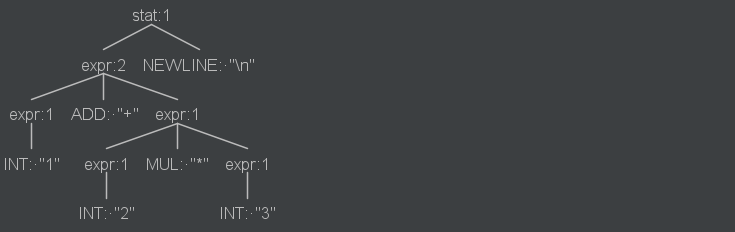
默认情况下,ANTLR按照我们通常对*和+的理解,将运算符从左向右的进行结合。尽管如此,一些运算符
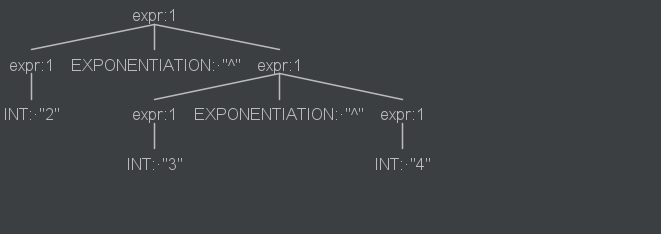
例如指数运算符是从右向左结合的,所以我们需要在这样的运算符上使用assoc选项手工指定结合性。
这样输入的2^3^4就能被正确解释为2^(3^4):
grammar indexexpr;
proc: expr+;
expr: <assoc=right> expr '^' expr //^运算符是右结合的
| INT
;
INT: [0-9]+;
EXPONENTIATION : '^';
NEWLINE: '\r'? '\n';语法树:
若要将上述三种运算符组合成为同一条规则,我们就必须把^放在最前面,因为它的优先级比*和+都要高。
grammar symbolicintegration;
proc: expr*;
expr: <assoc=right> expr '^' expr //^运算符是右结合
| expr '*' expr //匹配由'*' 运算符连接的子表达式
| expr '+' expr //匹配 '+' 运算符连接的子表达式
| INT //匹配简单的整数因子
;
INT: [0-9]+;注意:在ANTLR 4.2 之后,<assoc=right>需要被放到备选分支的最左侧,否则会受到警告。
左递归规则是这样的一种规则:在某个备选分支的最左侧以直接或间接方式调用了自身。上面的例子中的expr规则是直接左递归的,因为除INT之外的所有备选分支都以expr规则本身开头(它同时也是右递归(right recursive)的,因为它的某些备选分支在最右侧引用了expr)。
虽然ANTLR 已经能够处理直接左递归,但是它还无法处理间接左递归。


















 3490
3490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











