




大家好啊,我是董董灿。
本文以图解的方式来讲解什么是词向量以及其特征如何理解。
按惯例,先看一个例子。
例子:你是什么样的人?
本例来源于 Jay Alammar 的博客,我在原文基础上进行了精简和提炼。
不知道你是否做过性格测试。
在很多类似的测试中,都会有许多道题来让你回答,然后从多个维度、多个方面衡量你的潜力或特质,然后给出分值,最后综合来评判你是一个什么样的人。
假设一个叫Jay 的人做完性格测试,在“你是属于内向还是外向?”这项测试中得到了38分。这里满分为100,分数越高,说明人越外向,分数越低,说明人越内向。

为了抹平多项测试间的分值差异,这里将所有得分的数据归一化到 [-1,1] 之间。归一化后内外向得分为 -0.4 分,负值说明内向,正值说明外向。

此时很明显,说明Jay这个人偏内向。但也仅此而已,我们从 -0.4 这个分数看不出 Jay 有其他什么品质,仅仅知道他偏内向而已。
这个时候,如果再增加一个测试项目的得分,假设 Jay 在另一个测试项目中得分为 0.8 分。
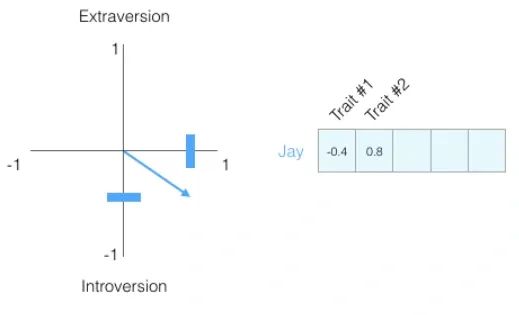
此时,根据这两个测试项目的数据,我们知道 Jay 这个人在第一个性格(Trait #1:内外向)中得分为 -0.4,他偏内向。
在第二个性格中得分0.8。
虽然这里没指明第二个性格具体代表的是什么(比如你可以理解为“是否任劳任怨加班?”,0.8 分说明他是一个加班狂),但至少我们对 Jay 的认识又增加了一些。
假设,现在Jay在上班途中被车撞了,公司需要一个人来顶替他的工作内容,有两个候选人(Person #1 和 person #2),他们在这两项测试中的得分如下:
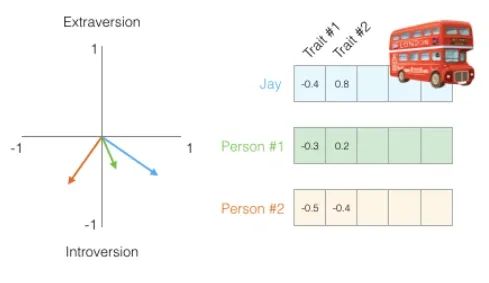
根据这两个候选人的得分,你更倾向于让谁来代替Jay呢?
你可能会说,看样子 person#1 和 Jay 在两项上的得分更相近,两人具有更类似的特质,可以让 person#1来代替 Jay。
是的,在数学模型上,衡量两个人的性格数据(这里实际上是向量)是否相似,可以使用余弦相似度的方法,这个在上一节介绍过了。
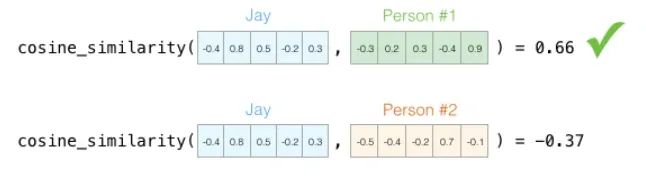
通过计算,可以的得到余弦相似度数值为:

很明显,person #1 获选,因为他和Jay的余弦相似度更高。
上述每一项(Trait #1, Trait #2)的得分都代表了这个人在某一项测试中的特质或潜力,或者说是这个人在某性格维度上的特征值。
但是 2 个特征还不足以完全代表一个人,因此我们可以将特征数量继续增加:

继续计算余弦相似度:
通过计算,仍然得到 person #1 与 Jay 更相似的结论。
至此,Person #1 获选,说明Person #1 和Jay更相似,更容易获得这份工作。
如果把上述例子中的得分组成的向量看做是词嵌入向量,那么其中的数值,便是代表一个单词在各个维度特征的得分值。
比如在我的《Transformer最后一公里》专栏中会提到,猫(cat)可以是以下特征的集合:
cat = [会跑(1)、会爬树(0.9)、会叫(1.0)、粘人(0.6)、会抓老鼠(0.6),会游泳(-0.9),会喷火(-1.0)...]
只要给够足够多的维度得分,一个向量便可以更加精确的表示猫(cat)这个单词。
这便是词向量的作用,作为单词各维度语义的集合而存在。
欢迎订阅Transformer专栏,里面会有更多算法的使用动机和通俗的讲解,还会有代码实战哦。
 https://blog.youkuaiyun.com/dongtuoc/article/details/138633936?spm=1001.2014.3001.5501
https://blog.youkuaiyun.com/dongtuoc/article/details/138633936?spm=1001.2014.3001.5501


















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











