



1.1 Redis入门:
Redis 简介:
Redis 是一个基于内存的 key-value 结构数据库。
- 基于内存存储,读写性能高
- 适合存储热点数据(热点商品、资讯、新闻)
- 企业应用广泛
Redis 下载与安装:
下载:

安装:

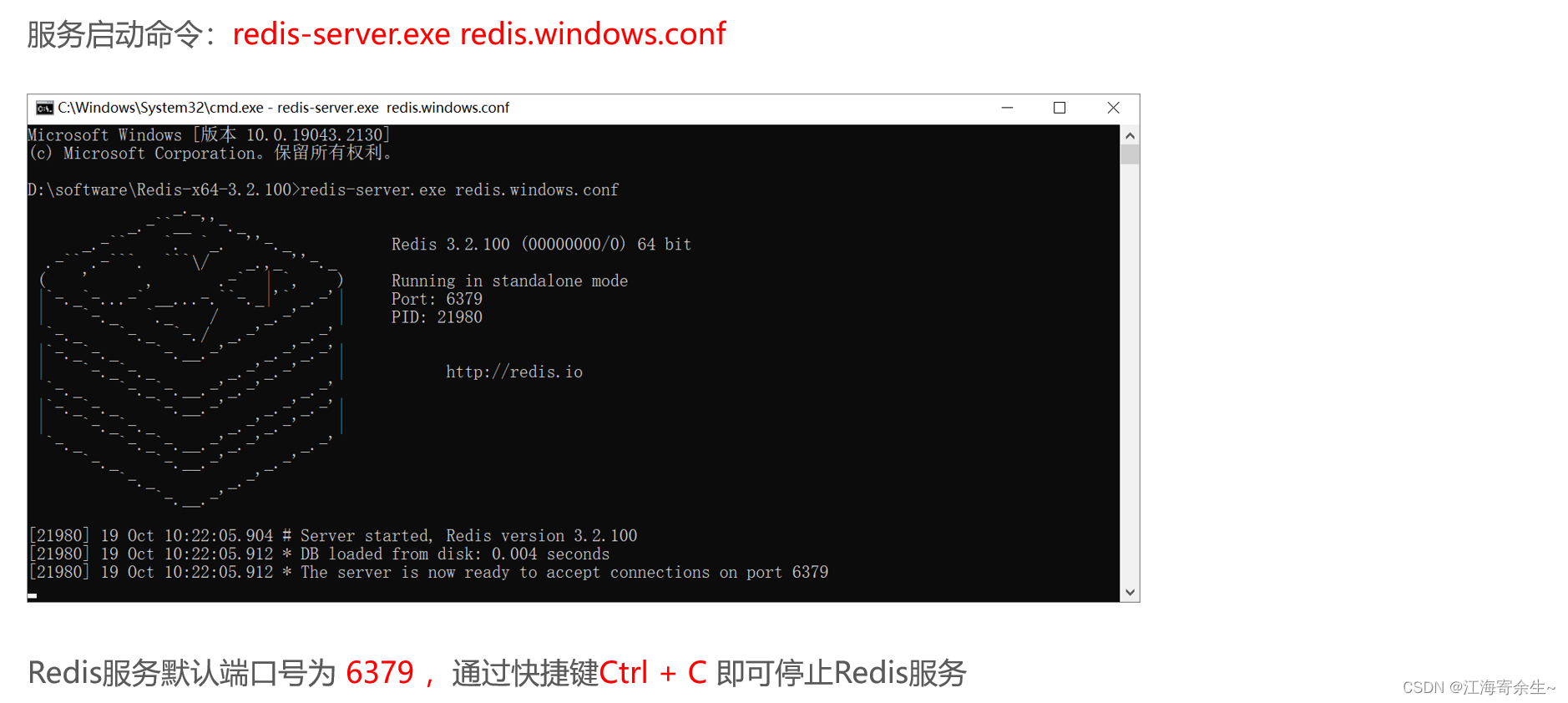
Redis 服务启动与停止:
Redis 客户端图形工具:
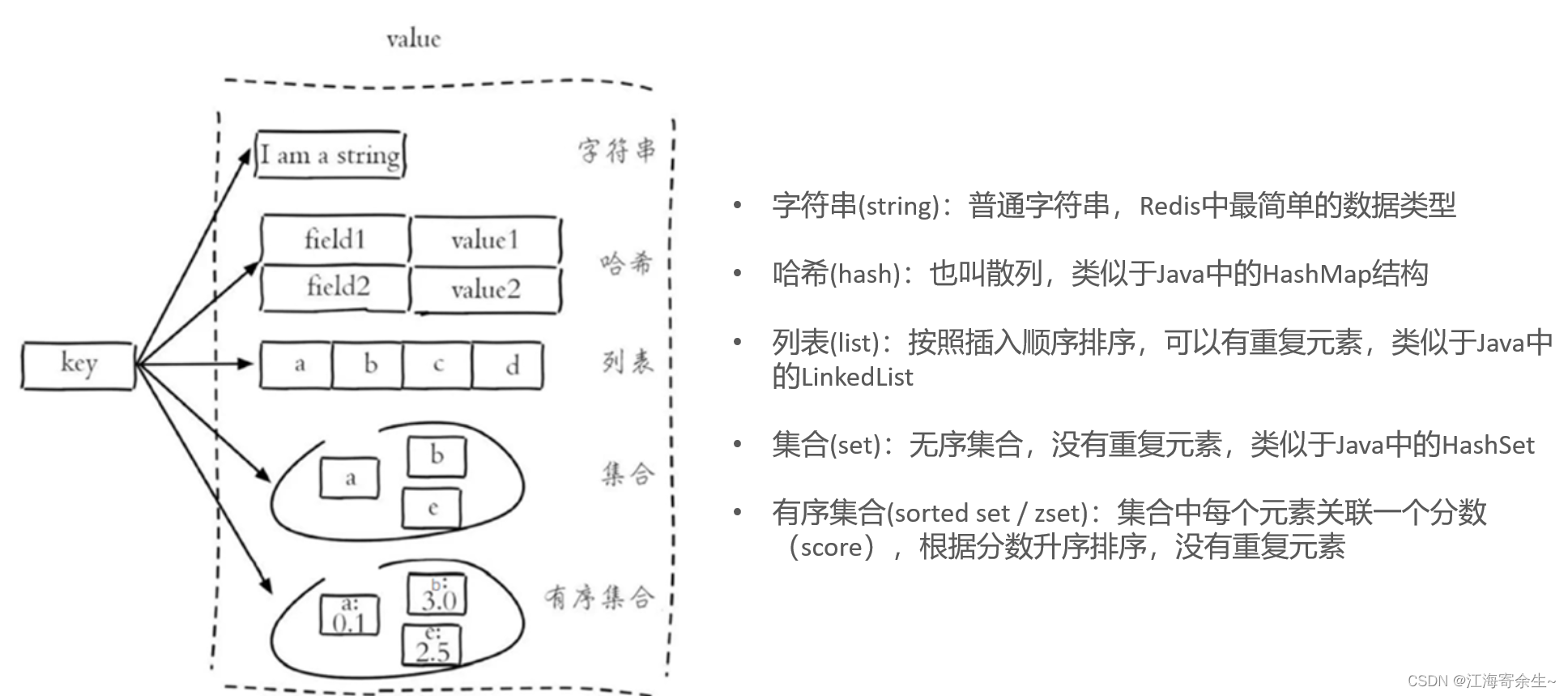
Redis 5种常见数据类型:

Redis 各种数据类型的特点:
1.2 redis 在项目中的作用?
Redis 是高性能的,基于键值对的,写入缓存的 内存存储系统。它支持多种数据结构如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令。
项目中引入 Redis 的地方是:
查询店铺营业状态 像这种店铺营业状态,本项目无非就两个状态:营业中/打样。而且它属于高频查询。只要用户浏览到这个店铺,前端就要自动发送请求到后端查询店铺状态。Redis 是基于键值对这种形式存储的,而且 Redis 也把将数据放到缓存中,而不是磁盘,有效缓解了这种高频查询给磁盘带来的压力。
缓存菜品 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。结果:系统响应慢、用户体验差。通过Redis来缓存菜品数据,减少数据库查询操作。
1.3redis的缓存原理,为什么速度快?
- Redis 将数据存储在内存中,相比于磁盘的数据库系统,内存存储具有更快的读写速度
- Redis 使用单线程模型来处理客户端请求,避免了多线程并发导致的线程切换开销与竞争
- Redis 内置了多种优化后的数据类型 / 结构实现,性能非常高
- Redis 使用的是非阻塞 IO 多路复用,使用了单线程来轮询描述,将数据库的开、关、读、写都转成了事件,减少了线程切换时上下文的切换和竞争。
1.4 Redis 的缓存淘汰机制是怎么样的?
Redis 的缓存淘汰(Eviction)机制是指当Redis 的内存空间不足以容纳新的数据时,Redis 将根据预先设置的策略,自动淘汰部分现有数据,为新数据腾出空间。
这个在Redis中提供了很多种,默认是 noeviction ,不淘汰任何key,但是内存满时不允许写入新数据。
- LRU(Least Recently Used,最近最少使用)LRU 会淘汰最近最久未使用的数据。当Redis 内存空间不足时,Redis 将淘汰最近最久未使用的数据,为新数据腾出空间。
- LFU(Least Frequently Used, 最不经常使用)LFU 会淘汰使用频率最低的数据。当Redis 内存空间不足时,Redis 将淘汰使用频率最低的数据,为新数据腾出空间。
- Random(随机淘汰)随机淘汰策略会随机选择一些数据进行淘汰,没有明确的淘汰规则。当Redis 内存空间不足时,Redis 会随机选择一些数据进行淘汰,并为新数据腾出空间。
- TTL(Time To Live)当数据设置了过期时间,在数据过期后,Redis 会自动将该数据从缓存中淘汰。
- Maxmemory Policy 通过配置max-memory-policy 参数来指定缓存淘汰策略,可以选择以上任意一种策略或它们的组合。
1.5 Redis的 io 多路复用是什么?
在 Redis 中,多路复用是通过select、poll、epoll这样的系统调用来实现的。
Redis 服务器通过使用这些系统调用来监听多个客户端连接,以及与其他 Redis 服务器进行通信的连接。当有连接准备好进行读写时,服务器就会立即知道并进行相应的操作。
1.6 Redis 作为缓存,MySQL 的数据如何保证与Redis 进行同步?
采用 redisson 实现的读写锁,保证了对共享资源的互斥访问。读写锁允许多个线程同时获取读锁,因此在读取共享资源时,可以实现并发读取,提高了系统的读取性能。但是当有线程获取写锁时,其他线程无法同时获取读锁,保证了操作的原子性,避免了读取到部分更新的数据。
1.7 说一下Redis 的缓存雪崩、缓存穿透、缓存击穿问题
- 缓存雪崩 在搞并发下,大量的缓存key 在同一时间失效,导致大量的请求落到数据库上,如活动系统里面同时进行着非常多的活动,但是在某个时间点所有的活动缓存全部过期。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 如果缓存数据是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
- 设置热点数据永不过期。
- 缓存穿透 访问一个不存在的key (查询 userId = -10),缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id <= 0的直接拦截;
- 从缓存取不到的数据,在数据库中没有取到,这时可以将key-value 对写成key-null ,缓存有效
- 缓存击穿 一个存在的key,在缓存过期的那一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。
解决方案:
- 设置热点数据永不过期
- 加互斥锁,业界比较常用的做法。简单来说,就是在缓存失效的时候(判断拿出来的值是否为空),不是立即去加载数据库,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis 的SETNX)去set一个metex key,当操作返回成功时,再进行加载数据库的操作并回设缓存;否则,就重试整个get 缓存的方法。
1.8 如何解决Redis 的缓存穿透问题
- 缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。这种情况大概率是遭到了攻击。
- 使用布隆过滤器来解决缓存穿透:主要是用于检索一个元素是否在一个集合中。我们当时使用的是redisson 实现的布隆过滤器。它的底层主要是先去初始化一个比较大数组,里面存放的二进制 0 或 1。在一开始都是 0, 当一个 key 来了之后经过3次 hash 计算,模于数组长度找到数据的下标然后把数组1中原来的 0 改为 1,这样的话,三个数组的位置就能标明一个key 的存在。查找的过程也是一样的。当然是有缺点的,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,5% 以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









