 基于k位运算的磨损均衡算法
基于k位运算的磨损均衡算法




一种利用k位运算的闪存存储设备磨损均衡算法
摘要
闪存存储设备由于体积小、功耗低和高性能,被广泛应用于移动消费电子产品中。通常,闪存存储设备由NAND闪存组成。与传统的磁盘相比,NAND闪存需要额外的擦除操作,且其块具有有限的擦除次数。为了延长其耐久性,已提出了各种磨损均衡算法。然而,这些算法在管理块状态时会引发大量的读/写/擦除操作,并消耗大量内存资源,因为它们未考虑闪存转换层的特性。为解决这些问题,本文提出了一种针对基于日志的闪存转换层的新磨损均衡算法。在基于日志的闪存转换层中,由于日志块频繁更新和擦除,因此保留很少被删除的冷块作为下一个日志块,从而使所有块被均匀擦除。此外,提出的算法通过利用k位擦除表来减少内存资源的使用量,该表仅需少量k位擦除标志即可管理其块擦除状态。通过与相关磨损均衡算法进行多种实验,本文证明了提出的磨损均衡算法1的优越性。
索引术语
磨损均衡,闪存转换层,闪存存储设备,NAND闪存
一、引言
如今,闪存存储设备(如多媒体卡和固态硬盘)因其体积小、重量轻、功耗低而被广泛应用于移动消费电子产品中。此外,闪存存储设备能够快速访问存储的数据,且无延迟。通常,它由NAND闪存构成,并继承了NAND闪存的许多物理特性。
NAND闪存的一个主要特点是,与传统磁盘不同,必须执行擦除操作,因为闪存无法就地覆盖数据。读/写操作以页为单位进行,而擦除操作则以块为单位进行,每个块由固定数量的页组成。擦除操作比其他操作慢得多。此外,由于闪存块的擦除次数有限,闪存存储设备在主机和闪存之间内部采用了一种称为闪存转换层(FTL)的中间软件层,以处理上述特性[1]‐[3]。
FTL的主要功能是将主机请求中的逻辑到物理地址映射转换到物理闪存中,从而使闪存存储设备能够被识别为块设备。由于闪存在进行就地更新时无法允许此类操作,FTL会将每个来自主机的写请求重定向到一个预先擦除过的空页。为此,已提出了多种映射算法,而基于日志的FTL变体因其多种优势[4]‐[7]而在闪存存储设备中被广泛采用。
FTL的另一个重要功能是磨损均衡,它通过均衡所有块的擦除次数来延长闪存的寿命[8]。闪存中的擦除操作发生在执行垃圾回收以回收空闲块的过程中。当闪存中没有足够的空间存储数据时,FTL会启动垃圾回收,将牺牲块中的有效数据复制到一个空块中,然后擦除该牺牲块。
对特定块进行频繁的擦除操作会降低闪存的整体寿命。然而,大多数垃圾回收算法更注重性能而非闪存的耐久性,因为它们需要大量的读/写操作。
如今,由于近期的闪存存储设备采用MLC或TLC闪存,其价格更低但耐久性比SLC闪存差,因此延长寿命的重要性日益增加。它们的寿命分别约为SLC闪存的1/10和1/100。为了提高闪存的耐久性,已提出各种垃圾回收[9]‐[12]和磨损均衡算法[13]‐[17]。然而,这些方法仅简单考虑块擦除次数的均匀性,而未考虑FTL的特性,例如地址映射算法。
本文提出了一种用于基于日志的闪存转换层的新型磨损均衡算法。在基于日志的FTL中,所有块被分为两类:存储首次插入数据的数据块和临时存储对应数据更新数据的日志块。
块。当日志块中没有空页时,将调用垃圾回收来回收日志块。根据基于日志的FTL的特性,显然日志块被频繁地删除。受此启发,提出的算法基本上为下一个空闲日志块分配擦除次数最少的块,从而实现所有块的均匀擦除以达到磨损均衡。此外,通过利用一种新的k位擦除表(该表使用少量内存资源识别擦除最多和最少的块),尚未被擦除的冷块被迁移到空的热块中。由于提出的磨损均衡算法是针对基于日志的FTL设计的,因此与相关工作相比,它可以更快地执行,并且所需的闪存操作更少。
本文的其余部分组织如下。第2节回顾了背景与相关工作。第3节详细描述了提出的磨损均衡算法。实验结果在第4节中展示。最后,本文在第5节进行总结。
II. 背景与相关工作
A. 闪存转换层
闪存存储设备由用于存储用户数据的NAND闪存和用于管理闪存的控制器组成,如图1所示。当主机发出读/写请求时,编程在只读存储器中的FTL通过存储在静态随机存取存储器中的映射表将来自主机的逻辑地址转换为闪存上的物理地址。闪存存储设备的性能在很大程度上受其映射算法的影响。根据管理单元的不同,映射算法主要分为三类:页级映射、块级映射和混合映射[3]。
页级映射将主机的每个逻辑扇区映射到闪存上的一个空物理页,以避免就地更新。页级映射能够快速执行所有写请求,而无需进行擦除操作。然而,随着存储容量的增加,映射信息的大小显著增加,因为每个逻辑扇区都需要其独立的物理地址信息。
存储容量的增加而增大,因为每个逻辑扇区都需要其自身的物理地址信息。相比之下,块级映射仅将来自主机的逻辑块映射到闪存上的物理块。因此,映射表的大小非常小,因为所有逻辑扇区都可以通过仅有的块地址进行访问。尽管它使用的内存资源较少,但在覆盖数据时的写请求会引发许多缓慢的闪存擦除操作。因此,结合这两种映射技术的混合映射算法主要部署在实际存储系统中。
一种基于日志的FTL [4], ,属于混合映射算法的一种,因其较小的映射信息开销和高性能而被广泛应用于闪存存储系统。因此,许多基于日志的FTL变体已被实现用于闪存 [5]‐[7]。基于日志的FTL中的块由多个通过块级映射管理的数据块和少量通过页级映射维护的日志块组成。插入的数据首先写入数据块,而需要更新的数据则临时存储到日志块中,以避免就地覆盖数据。当日志块中没有足够空间插入数据时,将触发垃圾回收。垃圾回收是指将特定日志块及其相关数据块中的有效数据进行合并,然后擦除牺牲块。
传统的垃圾回收算法更优先考虑清理成本,而非均衡磨损的程度。因此,在调用垃圾回收时,会选择包含大量无效页的块作为牺牲块,以减少读/写操作的次数。然而,随着价格较低但耐久性较差的MLC/TLC闪存使用量不断增加,闪存耐久性的重要性也在日益提升。
B. 磨损均衡算法
为了提高闪存的耐久性,已提出了多种垃圾回收算法。
成本效益策略(CB)[9]根据公式 age · (1‐u) / 2u 选择最有价值的块,其中u 表示有效页的比例,age 表示自最近一次修改以来的时间。也就是说,CB在执行垃圾回收时选择最旧的(即最近最少修改的块)且包含大量无效页的牺牲块。最少优先垃圾回收策略(LFGC)[10]将所有脏块按擦除操作次数的顺序链接成一个列表,然后选择擦除次数最少且具有最多无效页的块作为牺牲块。交换感知垃圾回收(NSAGC)[11]将被修改的有效页标记为潜在无效页,因为这些被修改的有效页可能在不久的将来被无效化。它还考虑了磨损均衡程度。因此,NSAGC在执行垃圾回收时选择具有大量潜在无效页和最多无效页且很少被擦除的块作为牺牲块。文件感知垃圾回收(FaGC)[12]同样考虑了磨损均衡
均衡。当最大擦除次数与最小擦除次数之间的差异超过预设阈值时,将选择擦除次数最少的块作为牺牲块进行垃圾回收。
由于这些垃圾回收策略基本上是为执行页级操作的闪存文件系统而开发的,因此需要大量内存资源来维护页和块状态(例如,无效页数量和擦除次数)。此外,它们不会选择尚未经擦除且没有任何无效页的块作为牺牲块,因为在执行垃圾回收时,该块需要大量的读/写操作来复制有效数据。然而,这种被称为冷块的块会导致擦除次数差异增大。换句话说,由于除冷块以外的块会迅速磨损,因此必须在闪存存储设备中应用磨损均衡。
在更细致地考虑冷块的基础上,已开发出磨损均衡算法以实现对所有块的均匀擦除。磨损均衡主要有两种方法:冷块迁移[13]‐[15] ,以及擦除次数最多的块与擦除次数最少的块之间的块交换[16]‐[17]。本文介绍了两种基本的磨损均衡算法,分别为作为冷块迁移算法的静态磨损均衡和作为块交换算法的双池磨损均衡。
为了使擦除次数更加均匀,静态磨损均衡(SW)[13]
在块的总擦除次数与已擦除块的数量之比超过预设阈值时,将冷块中的数据迁移到已擦除块中,从而平衡所有块的擦除次数。为了以较少的内存资源检测冷块,SW采用如图2所示的块擦除表(BET)。SW通过BET中的1位擦除标志来识别哪个块已被擦除。初始时,BET中的每个擦除标志均设置为0,表示该块(或附近块的组)尚未被擦除。当某个块被擦除时,其在BET中的擦除标志被设置为1,且总擦除次数增加1。
如图2所示,具有PBN 2和42的块已被擦除,其余块尚未被清除。在进行磨损均衡的冷块迁移时,随机选择一个擦除标志为0的块(例如PBN为2或42的块)作为牺牲块。
所选的冷块被迁移到已随机选定的已擦除块中,直到擦除比率降低至预设阈值以下。冷块迁移完成后,所有擦除标志均被设置为0。通过这种方式,SW保持了块耐久性的均衡。
由于块擦除表(BET)仅为识别其对应的块擦除状态分配了一个1位擦除标志,因此检测冷块的准确性不高。
为了更均匀地擦除所有块,双池磨损均衡(DP)[16]
将所有块划分为热池和冷池,其中热池是擦除次数较多的块的队列,冷池是擦除次数较少的块的队列。当热池中的最大擦除次数与冷池中的最小擦除次数之差超过预设阈值时,热/冷池中的块将相互交换。即,热池中擦除次数最多的块与冷池中擦除次数最少的块进行交换。由于冷块已被移入热池,因此在其擦除次数增加之前无法迁回冷池。

如图3所示,双池结构中的所有块分别维护在热池和冷池中。假设预设阈值为30,由于热池的最大擦除次数为31,冷池的最小擦除次数为0,因此执行冷热块交换。在这种情况下,物理块号26的块和物理块号13的块相互交换。
尽管磨损均衡程度比软件更精确,但由于频繁调用读/写操作,块交换会降低FTL的整体性能。此外,双池结构需要比软件更多的内存资源,因为它除了维护双池外,还需维护所有块的擦除次数。
III. 提出的磨损均衡算法
提出的磨损均衡算法旨在通过考虑基于日志的FTL的特性并以较少的内存资源实现所有块的均匀擦除,从而降低操作成本。大多数磨损均衡算法仅简单依赖于擦除次数的差异,而不考虑FTL映射算法。
由于基于日志的FTL中的日志块频繁写入更新的数据,为日志块分配的空块会迅速被填满并擦除。鉴于基于日志的FTL的这一特性,提出的算法为新的日志块分配擦除次数最少的块,从而在不执行额外磨损均衡的情况下均匀擦除所有块。此外,为了减少管理所有块擦除状态的开销,新引入了一种k位擦除表(k‐BET)。与现有的磨损均衡算法相比,k‐BET以较小的内存资源更精确地分类擦除最多和最少的块。
A. 操作细节
提出的磨损均衡算法的步骤包括空闲块分配、冷热块分类和冷块迁移。为了均匀擦除所有块,该算法始终从k‐BET中找到擦除次数最少的空块作为空闲块进行分配。
k‐BET用于以较小的内存资源管理所有块的擦除状态,并识别擦除最多和最少的块。当k‐BET中出现擦除最显著的块时,将执行冷块迁移。
如图4所示,基于日志的FTL的所有块由数据块地址表和日志块地址表进行维护。插入的数据首先被写入数据块,并在块级映射中进行管理。如果插入的数据已存在于数据块中,则该数据将被临时存储到日志块中,以避免在基于日志的FTL中进行就地更新。写入日志块中的数据通过页级映射进行管理。当新分配一个日志块时,提出的算法总是从k‐BET中找到擦除次数最少的块作为该日志块。
有必要迁移充满有效页的冷块,因为仅通过分配擦除次数最少的空闲块无法使所有块被均匀擦除。如果k‐BET中的每个块状态由k位擦除标志组成,则在某个块被擦除2k次后将执行冷块迁移。当k‐BET中出现最大值(例如,擦除标志为“1111”,其中k为4)时,图4中擦除次数最少的已使用块(PBN 4)将被迁移到一个空闲块,然后该块(PBN 4)被清除并重新分配给新的日志块。否则,将在不进行冷块迁移的情况下,将k‐BET中找到的擦除次数最少的空闲块分配给日志块。
B. 基于k位擦除表(k-BET)的块分类
现有的磨损均衡算法通过所有块的擦除次数差异来执行。随着闪存容量的增加,管理块状态的开销也随之增加。
为了减轻该开销,所提出的磨损均衡算法采用较小的k位擦除标志来进行冷热块分类。当一个块被擦除时,其在k‐BET中的擦除标志加1。热块是擦除次数最多的块,其所
有标志均被置为1。也就是说,当某个块被擦除2 k 次时,该块在k‐BET中被识别为热块。此时,进行冷块迁移
执行此操作。相反,冷块是所有标志位均为0的擦除次数最少的块,即自k‐BET初始化以来尚未被擦除的块。如果不存在任何冷块,则k‐BET中的所有标志位将右移,直到出现冷块为止。随着值k的增加,冷块迁移的首次执行时间被推迟,检测冷块的准确性提高,但需要更多的内存资源。
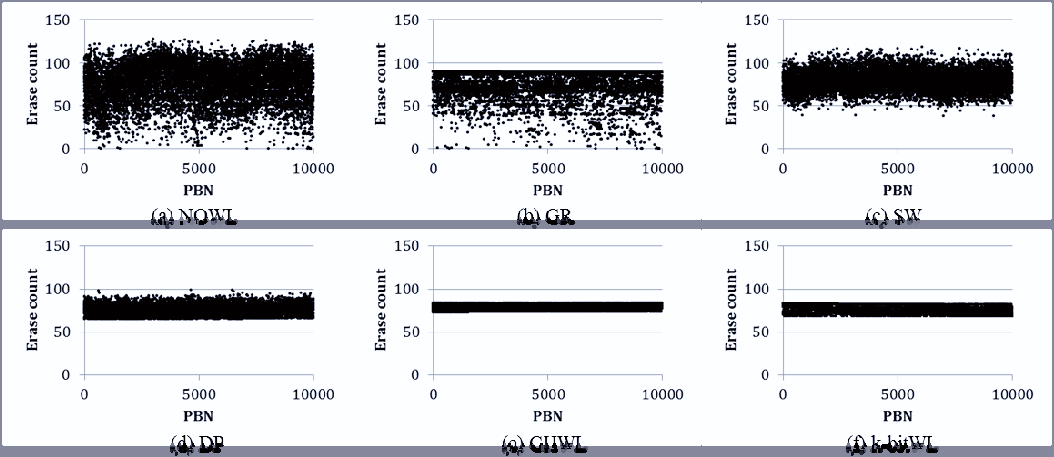
图5展示了k‐BET中的块状态。如果物理块号1的擦除标志被设置为“1110”,并且该块被擦除,则其擦除标志将增加至“1111”。此时,由于物理块号1的块变为热块,因此执行冷块迁移。为了检测冷块,提出的磨损均衡算法按顺序遍历k‐BET中的所有擦除标志。物理块号42的块中的有效数据被迁移到擦除次数最多的空闲块中,并且由于其擦除标志为“0000”,该块被删除。通过这种方式,尚未被擦除的冷块被迁移到擦除次数最多的空闲块中,而已擦除的冷块则保留作为下一个日志块使用,从而实现所有块的擦除次数均衡。迁移完成后,物理块号42的块的擦除标志将增加。如果该块是最后一个冷块,则所有块的擦除标志都将减少,直到至少出现一个冷块为止。由于物理块号41的块的擦除标志为“0001”,因此在图5的情况下,仅对所有擦除标志进行一次递减操作。否则,将继续迁移其他冷块,直到所有冷块都被消耗完毕。
C. 基于日志的FTL的详细实现
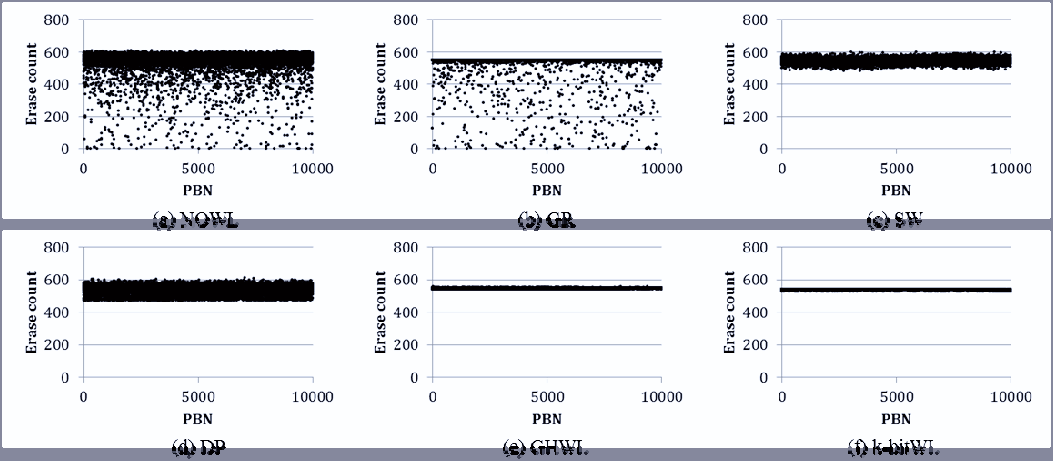
图6展示了写操作的伪代码。主机发出带有逻辑扇区号LSN的写请求。在第1行中,通过LSN计算得到逻辑块号LBN和页偏移量p。在第2‐7行中,如果块映射表中为LSN分配了物理块号PBN,则执行写操作。第5‐7行表明,如果偏移量为p的页为空,则将数据写入PBN的偏移量p处;否则,数据将被写入日志块中。当日志块中没有空页时,将触发垃圾回收以进行块回收。第9‐11行列出了没有与LSN相关的PBN的情况:从k‐BET中找到擦除次数最少的空闲块,并将其分配为数据块,同时在块映射表中更新该分配块的地址信息PBN以对应LSN,随后将数据存储到PBN的偏移量p处。
为了执行所提出的磨损均衡,需要进行擦除操作,如图7所示。基本上,当进行垃圾回收以实现块回收时,块将被删除。在第1‐2行,当具有PBN的块被擦除时,k‐BET中该PBN的擦除标志增加。在第3‐6行,如果热块的擦除标志全部为‘1’,则执行冷块迁移。在k‐BET中找到冷块,然后将其有效页复制到擦除次数最多的块中,即刚刚擦除的热块。在有效数据迁移后,冷块被删除。在第7行,已擦除的冷块被分配为下一个日志块。最后,在第8‐10行,如果k‐BET中没有冷块,则k‐BET中的所有擦除标志都将递减,直到冷块出现。
IV. 实验结果
A. 实验设置
为了评估所提出算法的性能,已在基于NAND闪存的参考板上实现了多种磨损均衡算法。该参考板的控制器运行频率为87.5兆赫,并配备了64兆字节SDRAM和两个32GB MLC NAND闪存模块。每个闪存模块的块由32个页组成,块大小为128千字节。
在此参考板上,FAST [5] 实现为基于日志的FTL,包含多种磨损均衡算法,其中包括提出的算法(k位WL)。这些算法包括无磨损均衡(NOWL)、贪婪算法(GR)、SW、双池结构(DP)和基于组的混合磨损均衡(GHWL)[14]。GR在块回收期间始终分配擦除次数最少的空闲块。GHWL执行随机冷块迁移和热/冷块交换。通常情况下,磨损均衡的阈值设置为10。换句话说,当最大擦除次数与最小擦除次数之差达到10时,便执行磨损均衡。提出的k位WL的块具有4位擦除标志。为了测量磨损均衡程度,嵌入式板上的块数量限制为10000。
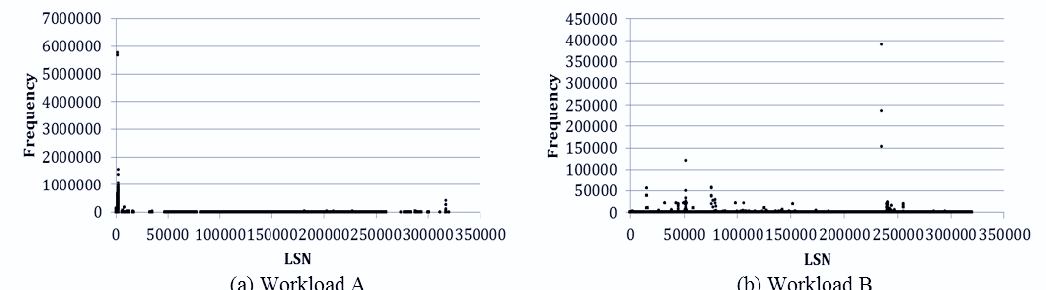
为了估算真实值,实验中使用了从文件系统中提取的四个实际跟踪。图8和表1分别显示了主机发出的写请求频率以及各工作负载的属性。
表 I 工作负载的属性
| 跟踪 | 已分配页数 | 已分配页面(LSN) | 写请求的比率频繁地重写页 |
|---|---|---|---|
| 工作负载A | 214,621 | 242,923,370 | 19% |
| 工作负载B | 157,308 | 11,402,701 | 9% |
| 工作负载C | 105,118 | 28,594,808 | 40% |
| 工作负载D | 194,837 | 7,821,539 | 14% |
如表1所示,工作负载A的主机在执行了242,923,370次写请求后分配了214,621个页(LSN)。工作负载B、C和D的主机分别在执行了11,402,701、28,594,808、7,821,539次写操作后,分配了157,308、105,118、194,837个页。在工作负载A中,大约19%的页被频繁重写,超过平均写入次数。换句话说,在该跟踪中,包含约81%已分配页面的块很少被擦除。在工作负载B、C和D中,分别约有9%、40%和14%的写请求被重复执行。如图8所示,工作负载A的模式显示在某些特定页面上执行了密集的写操作。工作负载B和D的模式似乎相似,且它们的重复写请求分布的页数比工作负载A更多。与工作负载A、B和C不同的是,在工作负载C中,许多已分配页面被重写。
B. 磨损均衡程度
图9、10、11 和 图12 显示了写请求完成时的擦除次数分布。X轴和Y轴分别表示物理块号(PBN)和擦除次数(EC)。

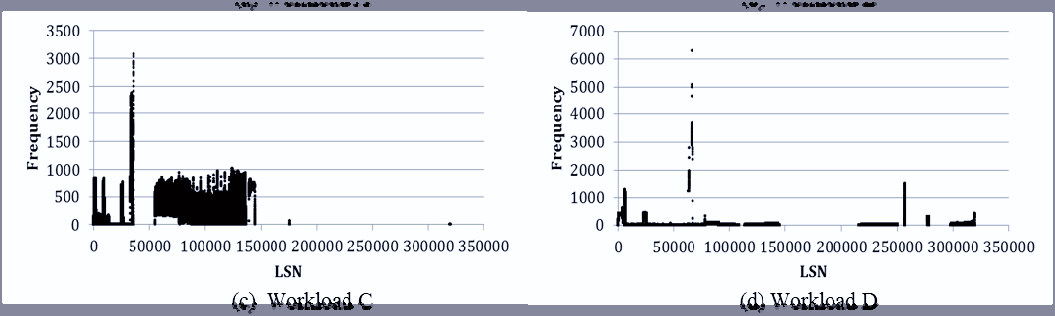
图9显示了在插入和重写大量数据时擦除次数(EC)的分布情况。NOWL和GR的平均擦除次数均为1999.83,且GR的偏差小于NOWL。尽管GR中擦除次数的分布有所降低,但很少更新的块仍然保持为冷块,因为GR只是简单地将擦除次数最少的块分配作空闲块。SW、DP、GHWL和k位WL的平均擦除次数分别为2063.86、2009.98、2108.75和2033.97。四种磨损均衡算法均实现了对所有块的均匀擦除,消除了冷块现象,但SW和DP的擦除次数偏差大于GHWL和k位WL。如果降低SW和DP的阈值,擦除次数的差异会减小,但平均擦除次数也会增加。最终,GHWL和k位WL均表现出良好的擦除次数均衡性,但k位WL的平均擦除次数低于GHWL,因为k位WL在考虑基于日志的FTL特性的基础上减少了所需的擦除操作次数。

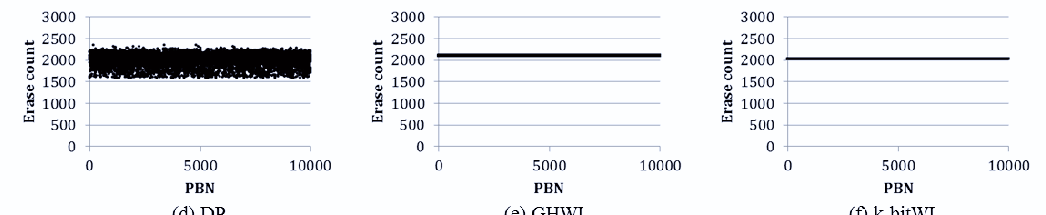
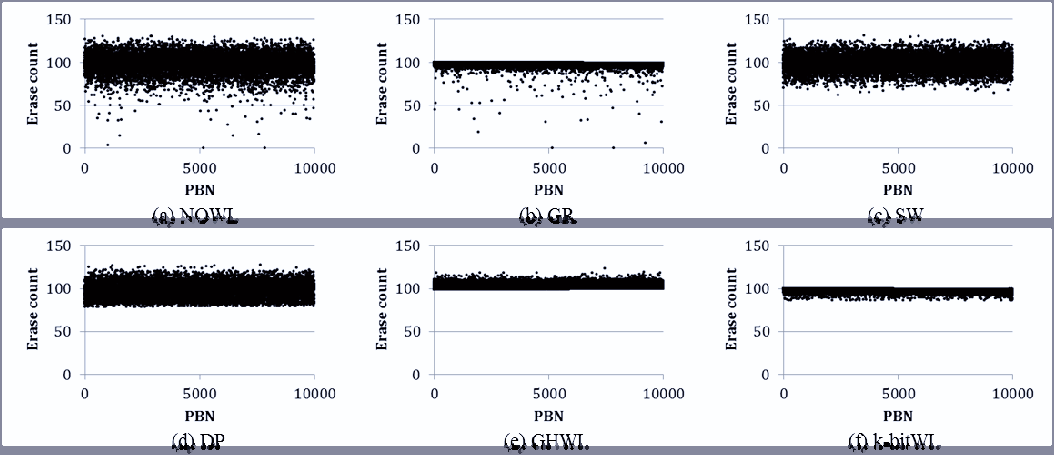
图10显示了在插入少量数据且重写数据量少于工作负载A时的擦除次数分布。从图10(a)和如图10(b)所示,当插入的数据量和重写数据率较小时,可以确定在没有磨损均衡算法的情况下,冷块很少被擦除。SW、DP、GHWL和k‐bitWL的平均擦除次数分别为781、789、778、772,⋯⋯和⋯⋯。在这种情况下,DP的平均擦除次数最少,但其偏差高于GHWL和k‐bitWL。DP的磨损均衡程度仅受预设阈值的影响。随着插入数据量的减少,SW由于随机选择牺牲块进行擦除,无法均匀擦除所有块。尽管GHWL和k‐bitWL在擦除次数上表现出良好的均衡性,但k‐bitWL比GHWL执行的擦除操作更少,因为k‐bitWL仅为下一个空闲块分配已擦除日志块。

图11显示了在多个页中重写大量数据时擦除次数(EC)的分布情况。此时,大多数磨损均衡算法会均匀擦除所有块,因为该跟踪中的冷块较少。SW、DP、GHWL和k位WL的平均擦除次数分别为544.42、538.63、547.34和539.01。与图10的结果类似,DP的平均擦除次数最少,但其偏差远高于GHWL和k位WL。GHWL和k位WL的擦除次数偏差分别为2.82和2.49。此外,k位WL的最大擦除次数小于GHWL。从本案例的实验结果来看,由于大量日志块被频繁用于冷数据,k位WL的整体性能优于其他磨损均衡算法。
如图12所示,结果似乎与图10的结果类似,因为它们具有相似的数据模式。NOWL和GR中的平均擦除次数等于97.75,而GR的偏差小于NOWL。SW和双池结构的平均擦除次数接近98.5,GHWL的平均擦除次数等于103.5,k位WL的平均擦除次数等于97.88。四种磨损均衡算法均能均匀擦除所有块,但SW和双池结构的擦除次数分布大于GHWL和k位WL。最后,GHWL和k位WL表现出良好的擦除次数均衡性,但由于GHWL需要大量擦除操作来进行冷迁移,k位WL的最大擦除次数小于GHWL。
根据图9、10、11和12的结果可知,k位WL通过考虑基于日志的FTL的特性,能够以较少的块擦除次数更均匀地擦除所有块。
C. 写入放大因子
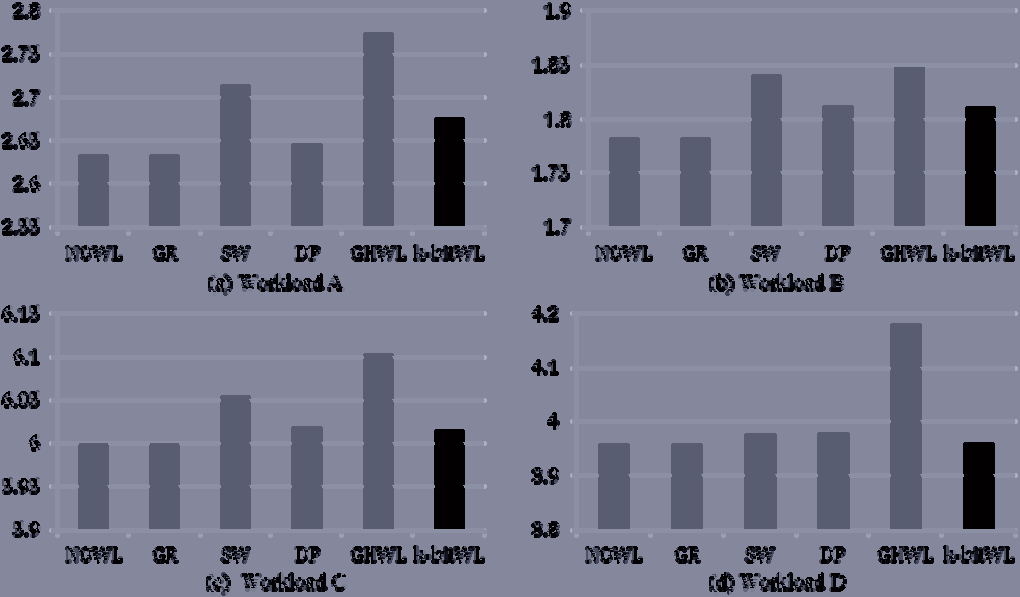
为了衡量性能以及均衡磨损,计算了写入放大因子(WAF)。由于闪存存储设备中存在先擦除后写入的限制,主机写请求的逻辑数据量与写入闪存的物理数据量之间会出现差异。该值用WAF表示,即闪存中实际写入次数与主机写请求次数的比值。
图13显示了每个主机的写请求完成后测得的写入放大因子。NOWL和GR中的所有写入放大因子均相等,且小于其他四种磨损均衡算法,因为在进行磨损均衡时未调用额外的擦除操作。在任何情况下,GHWL的写入放大因子都远高于其他算法,因为GHWL为了平衡擦除次数而擦除了大量块。除工作负载D外,SW的所有写入放大因子均高于GHWL和k位WL,因为SW由于块擦除表尺寸较小而无法精确选择冷块。除工作负载A外,k位WL的所有写入放大因子均小于双池结构,因为k位WL同时考虑了基于日志的FTL的特性以及块擦除状态。尽管k位WL在工作负载A下的写入放大因子大于双池结构,但k位WL能更均匀地擦除所有块。
从这些结果可以看出,由于k位WL考虑了基于日志的FTL中日志块频繁被擦除的特性,因此在k位WL中调用的操作更少。
D. 管理块状态的开销
为了衡量管理所有块的擦除状态的开销,表2展示了内存资源的使用量,其中i、n和k分别表示整数的大小、总块数以及k‐BET中擦除标志的大小。
表II 内存资源使用情况
| 磨损均衡算法 | 使用量 |
|---|---|
| GR | n · i 字节 |
| SW | n 位 |
| DP | n · 2i 字节 |
| GHWL | n · 2i 字节 + n 位 |
| k位WL | n · k 位 |
从所有实验结果和系统分析来看,k位WL 使用较少的内存资源即可实现对所有块的均匀擦除,并且比其他磨损均衡算法执行得更快。
五、结论
本文提出了一种用于基于日志的闪存转换层的新型磨损均衡算法。该算法通过使用较少的内存资源为日志块分配擦除次数最少的块,从而增强闪存存储设备的耐久性。特别是,该算法迁移冷块并将冷块分配给下一个日志块,以提高闪存的耐久性。通过考虑基于日志的闪存转换层的特性,与相关技术相比,提出的磨损均衡算法能够快速执行。最后,通过各种实验,提出的磨损均衡算法在磨损均衡性、性能以及内存资源使用量方面均表现出优越性。未来的工作将针对其他闪存转换层进一步改进提出的磨损均衡算法。

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









