




 本文介绍了爬虫技术的基础概念,包括数据存储方式、常用工具如正则表达式和XPath等,探讨了不同类型的代理IP及其优劣,并概述了爬虫开发的基本流程。此外还涉及了网页结构分析的方法以及请求包request的使用。
本文介绍了爬虫技术的基础概念,包括数据存储方式、常用工具如正则表达式和XPath等,探讨了不同类型的代理IP及其优劣,并概述了爬虫开发的基本流程。此外还涉及了网页结构分析的方法以及请求包request的使用。
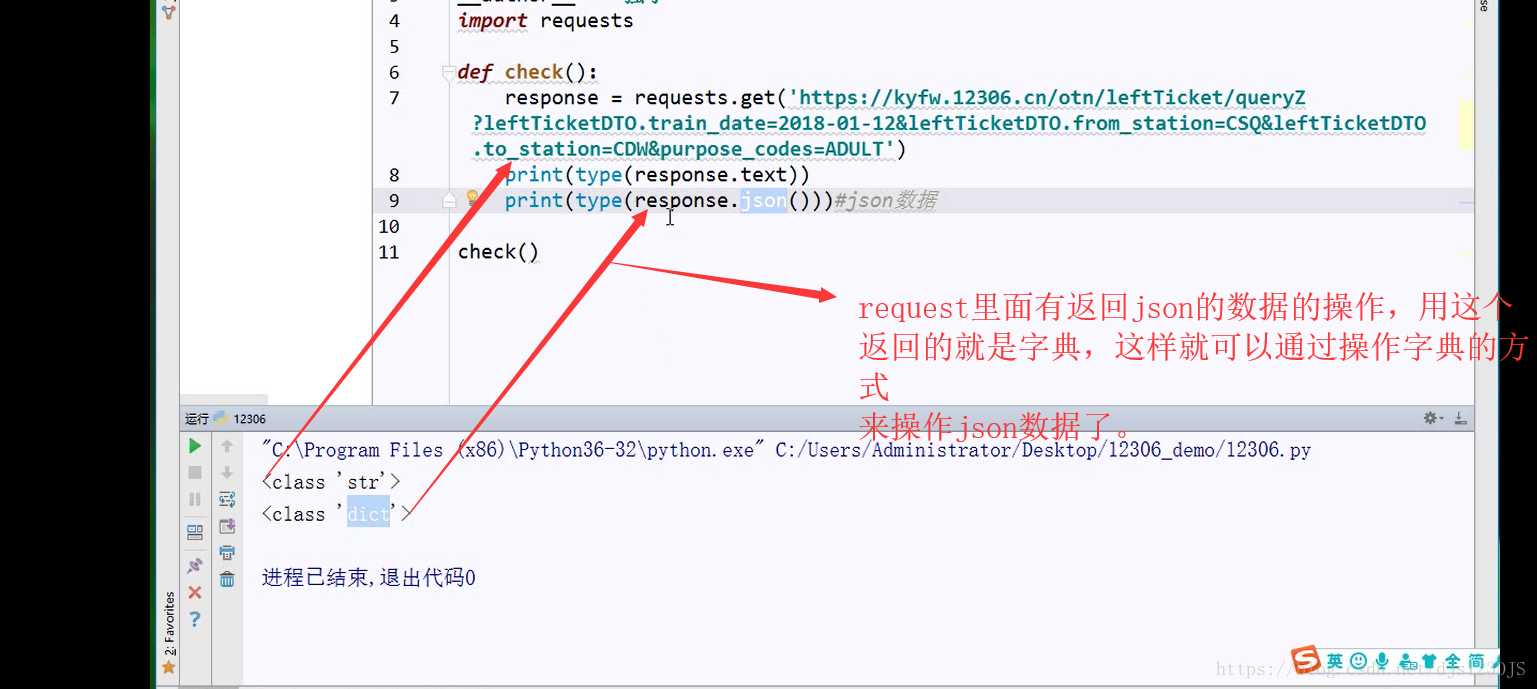
计算机上面的东西如果你不把它放在硬盘里面,它都是在内存里面,只有这两个硬件可以存储东西,所以爬虫匹配出来的结果如果没有放在硬盘里的,都是在内存 里面。解释工具(匹配)有正则,xapth,bs4,json只能转换成类似字典的数据。免费的代理ip,可用性很差,100个可能也没有一个可以用,并且过期 时间很快。所以一般不用免费的代理。安卓系统和苹果系统都是基于unix或者linux开发的,所以都可以用命令行来操作,后来unix收费了,所以有了后来的Linux。
python写系统命令就直接import os
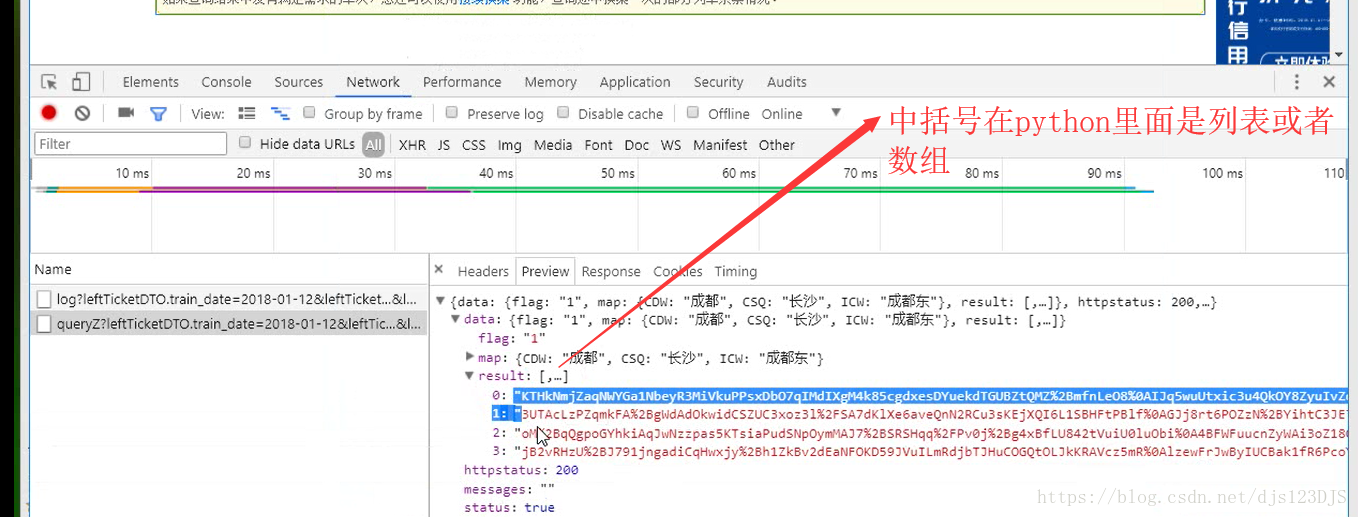
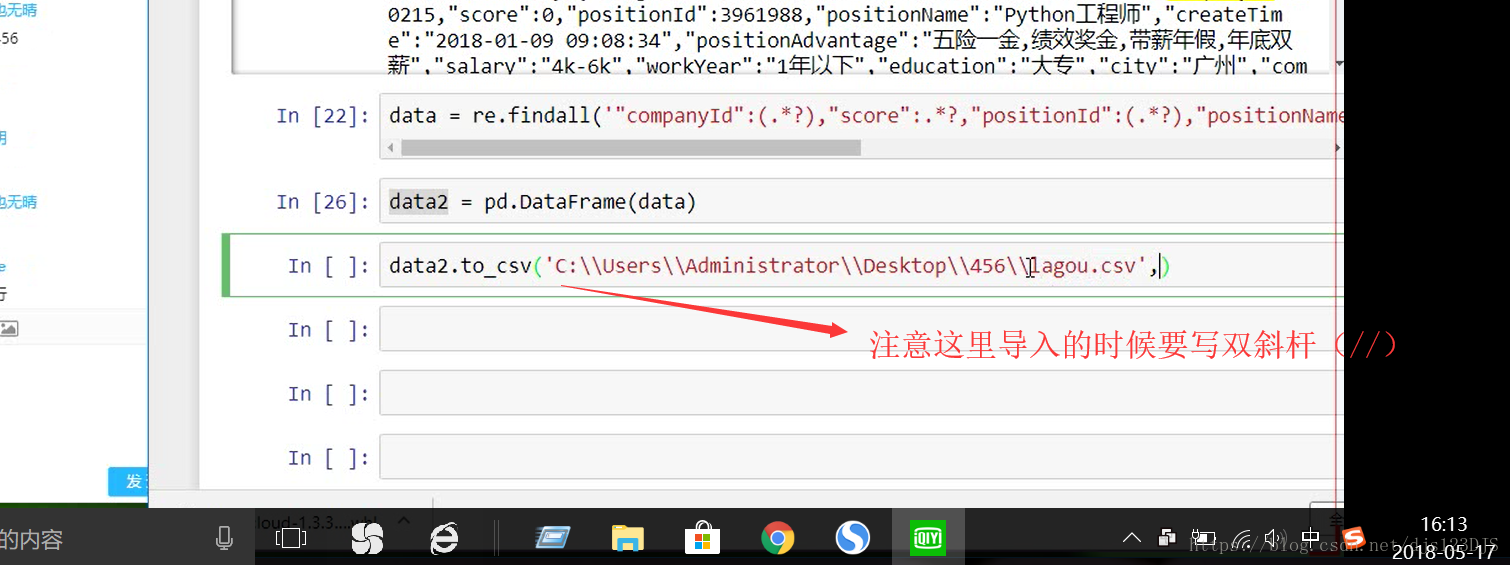
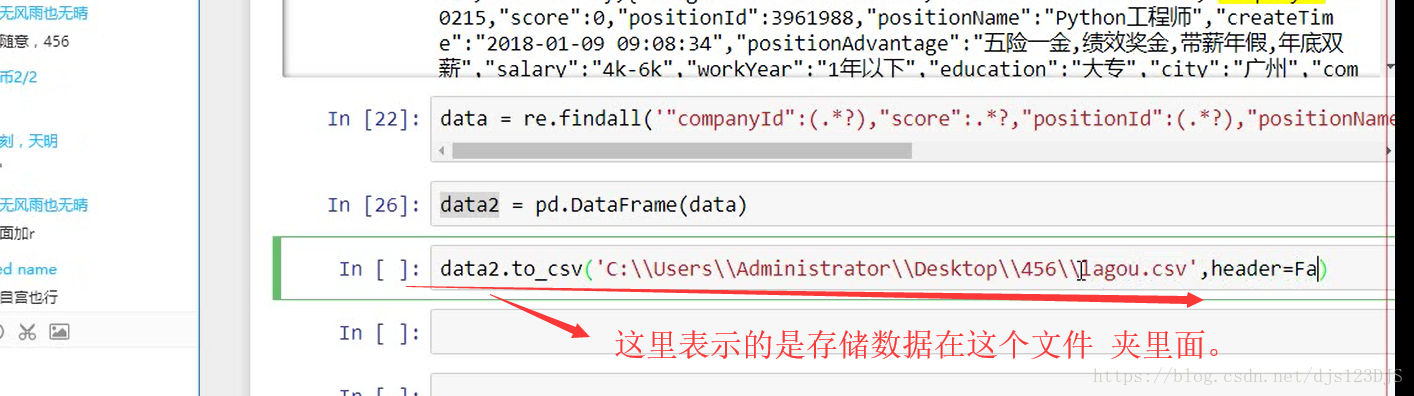
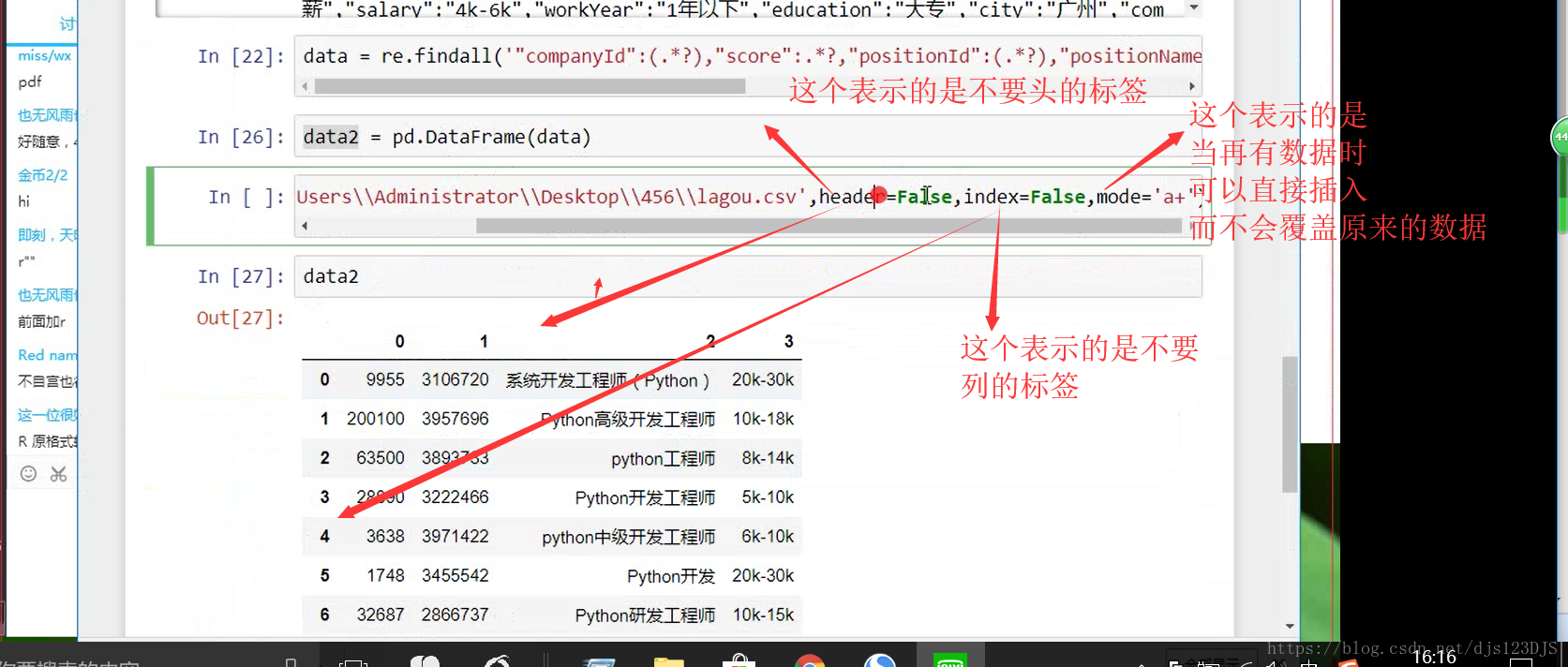
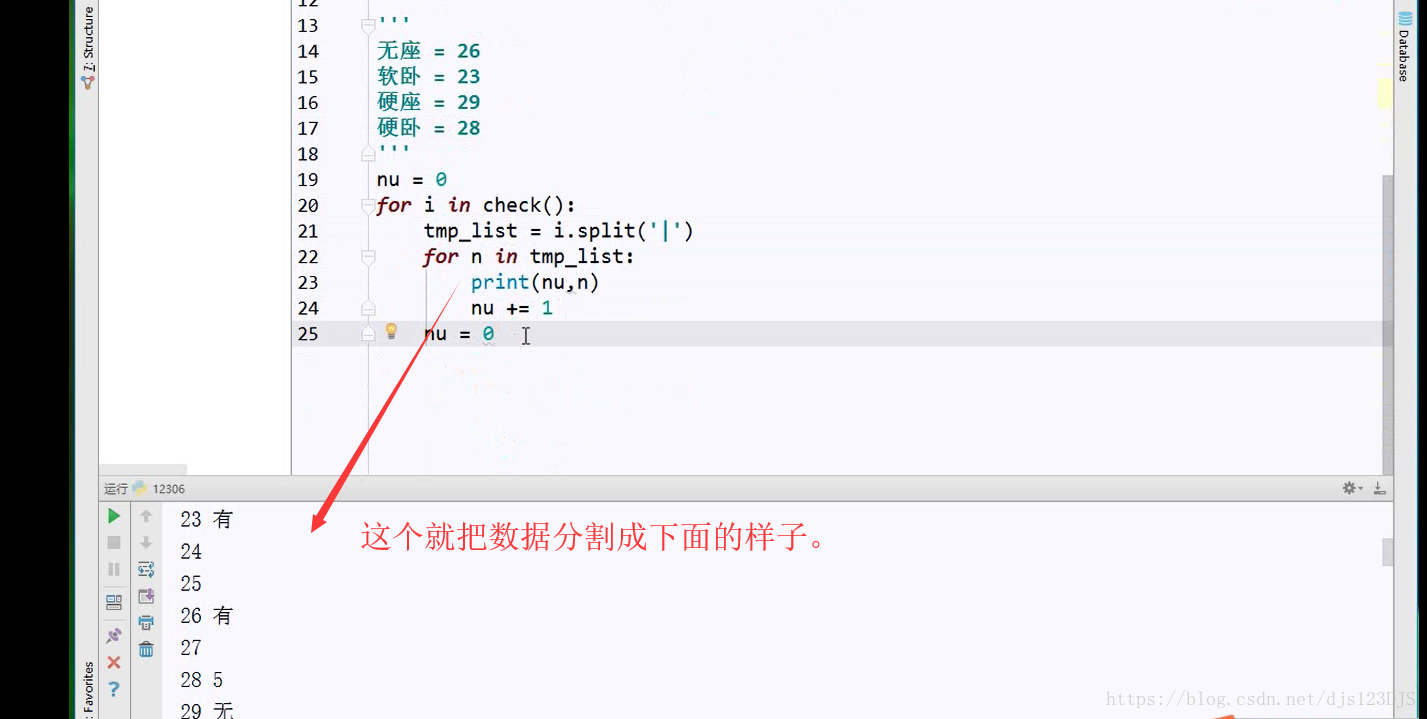
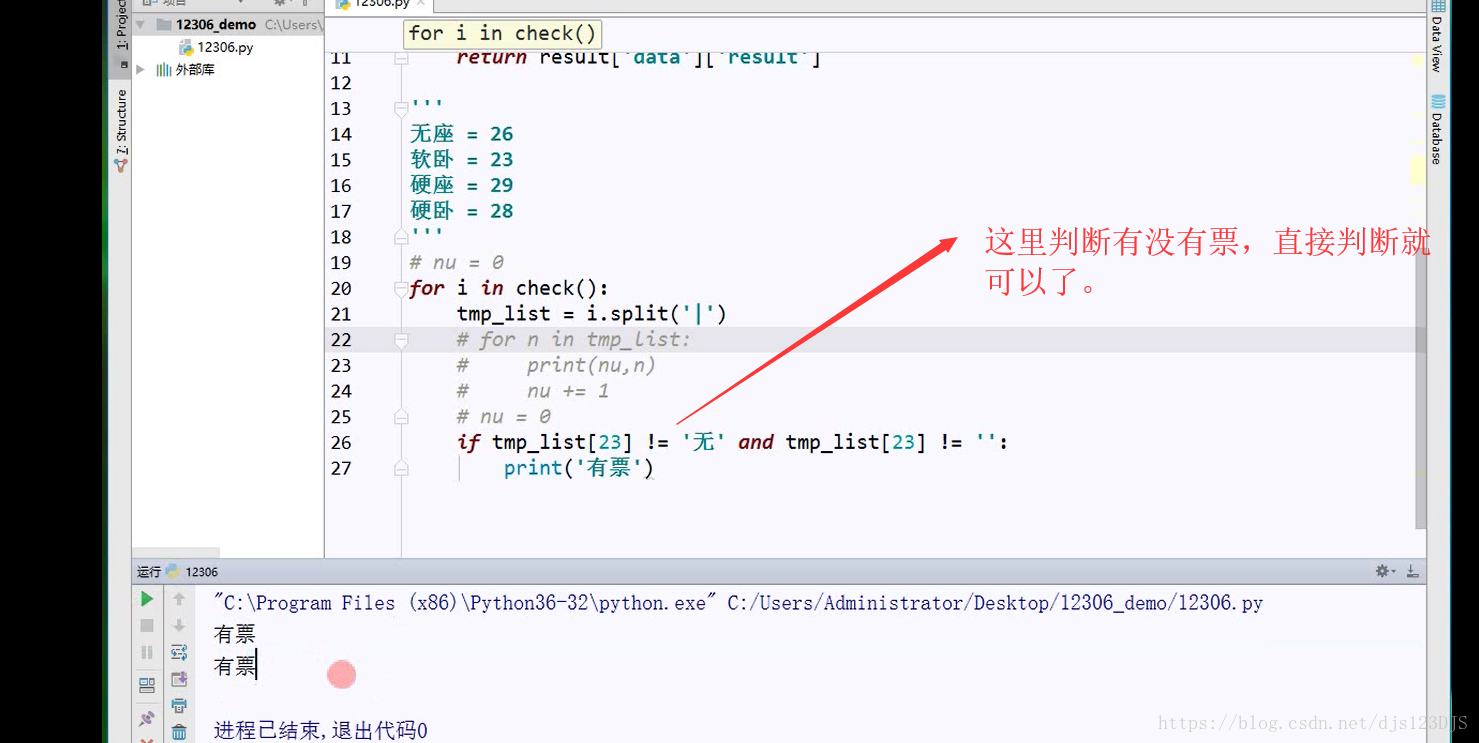
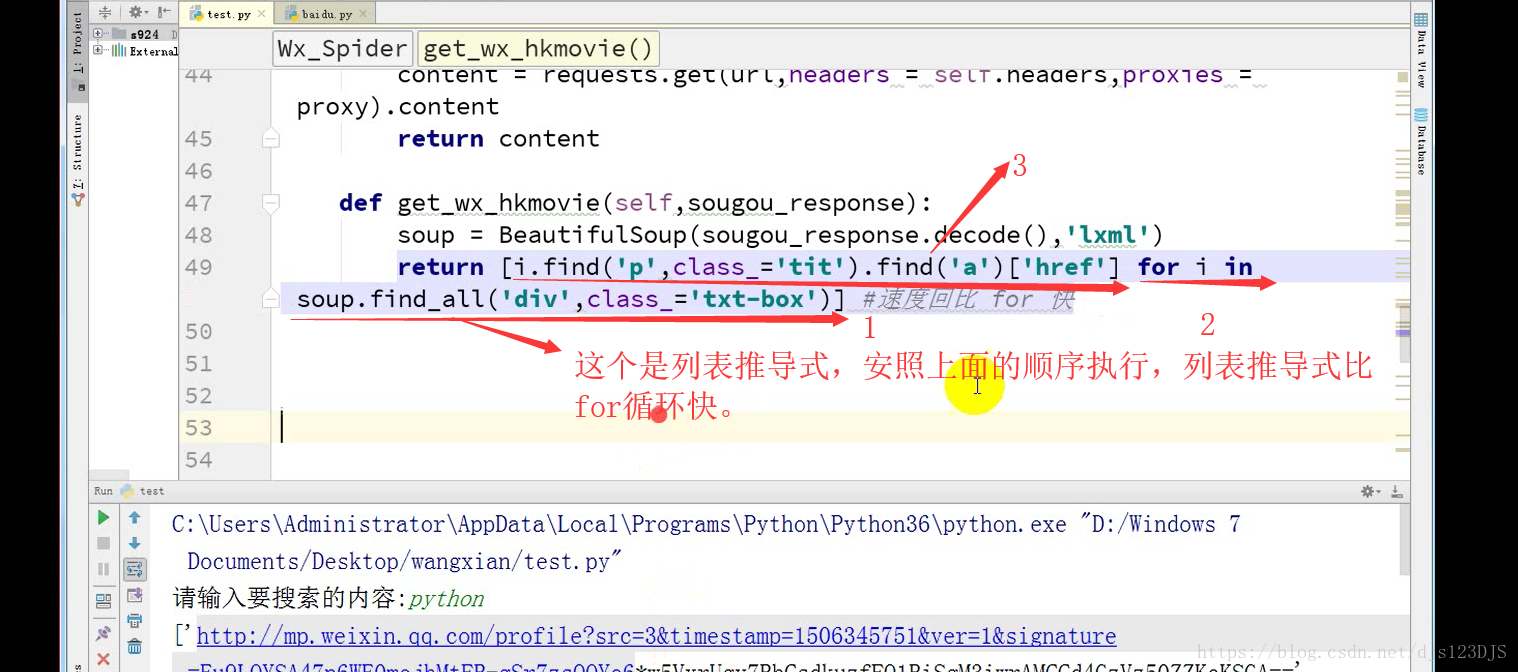
爬虫的开发流程:分析网页结构---寻找目标数据有三种方法---1.直接通过源代码返回数据,即查看网页 的源代码然后在那里搜索(这种方式有时候是不行的) 2.ajax异步请求动态渲染(加载,显示的内容并没有在那个网页里面,而是在后台或者别的地方) 3.数据混淆(即js加密)
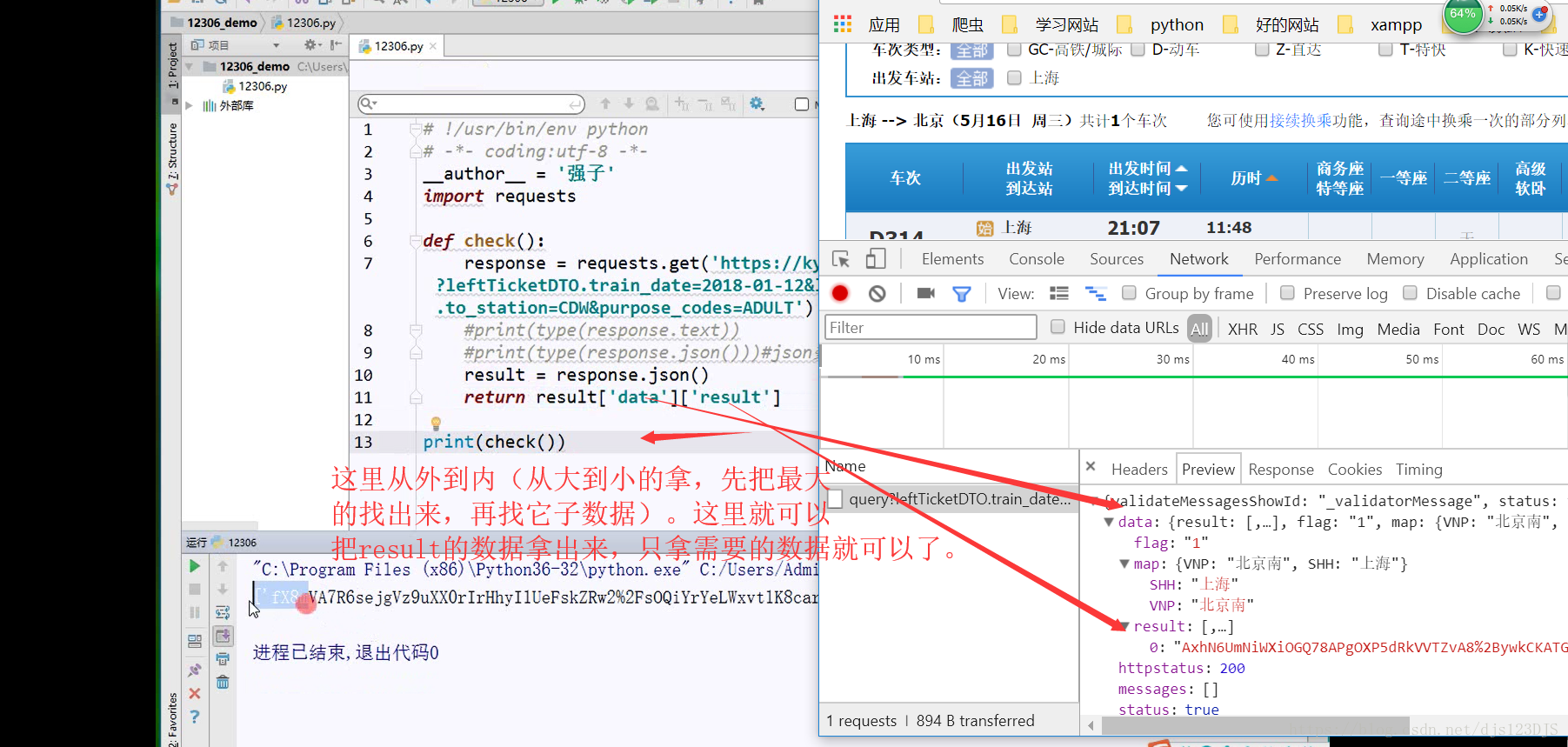
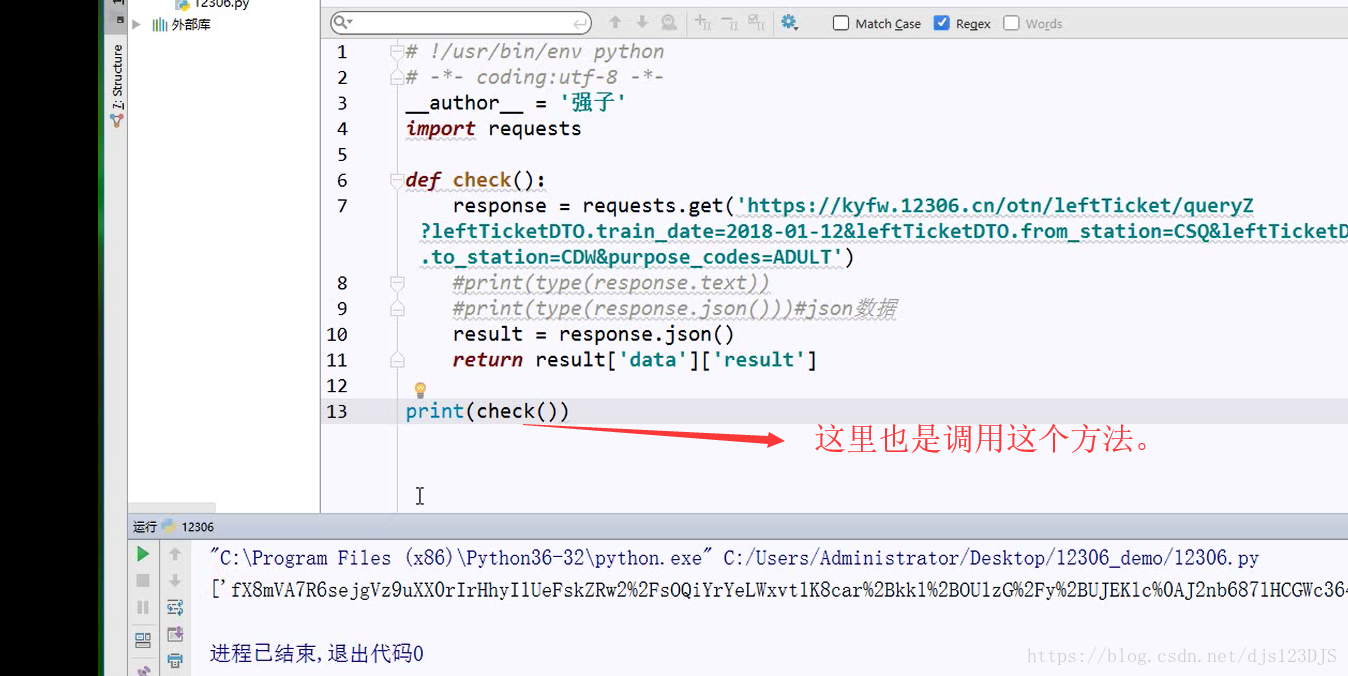
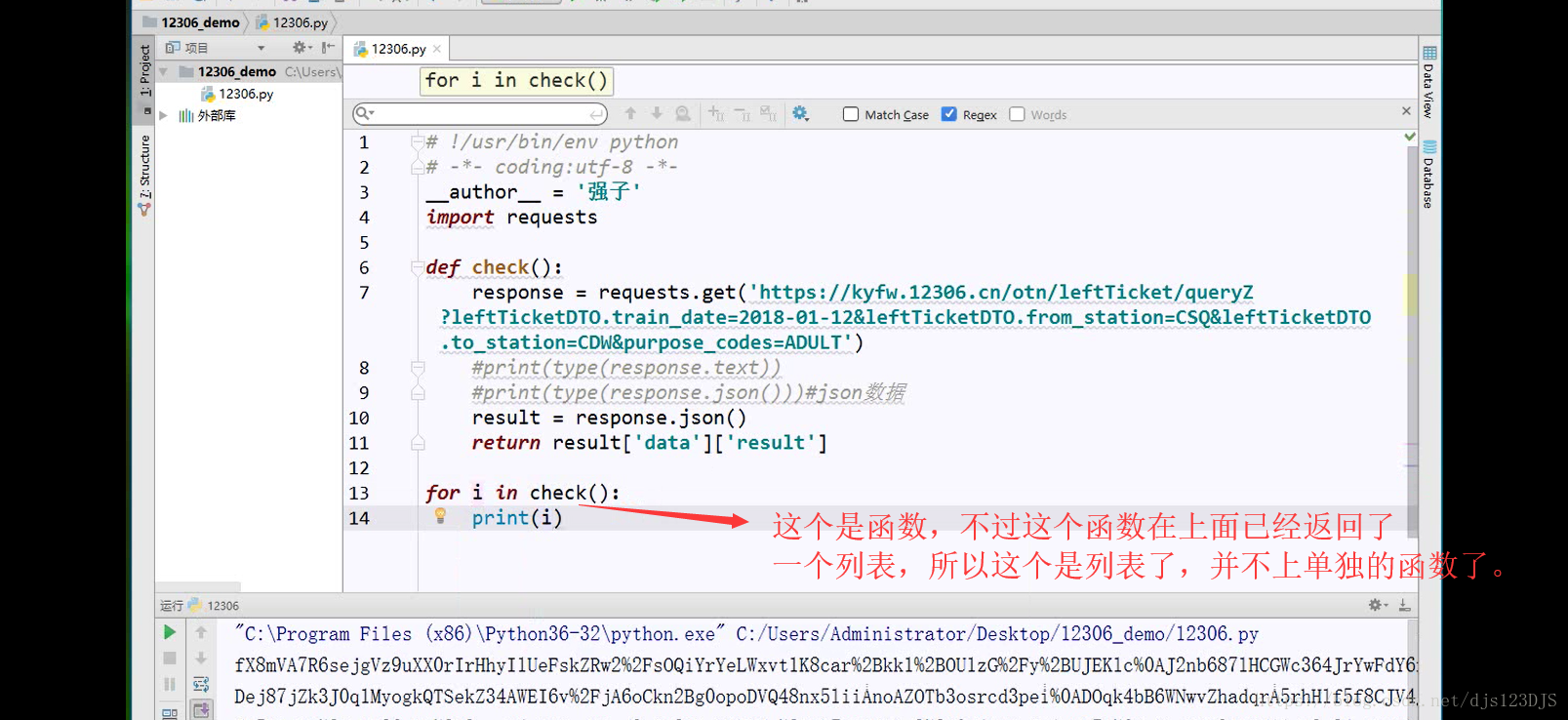
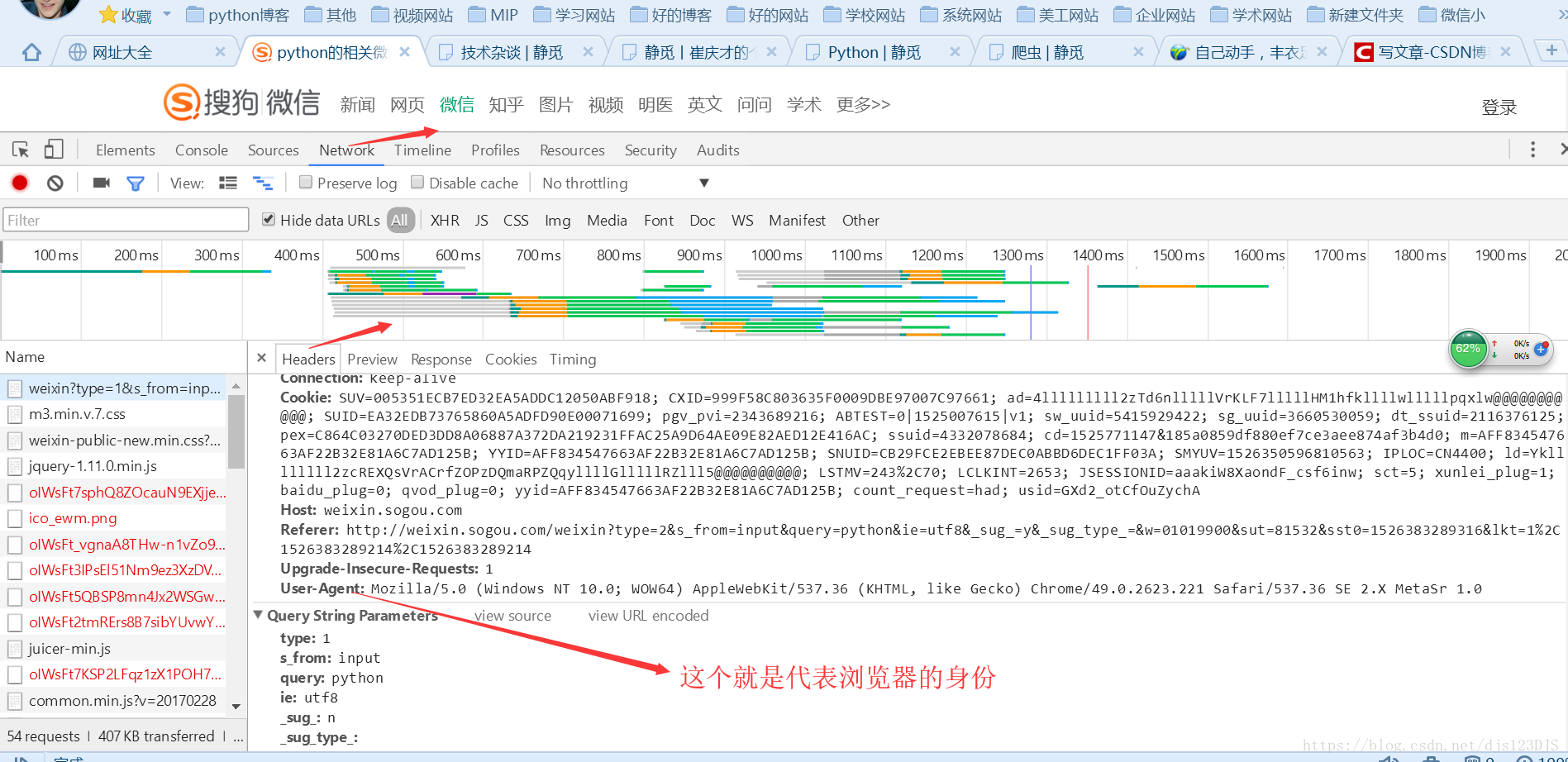
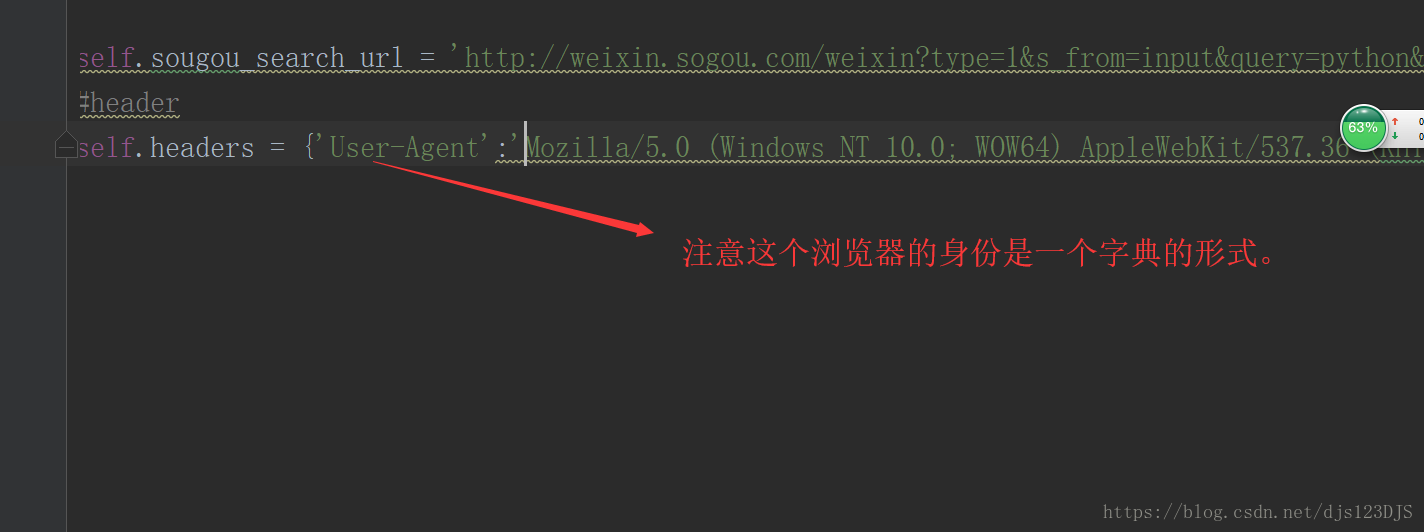
request是爬虫的请求包,通过这个包几乎可以解决所有请求的功能。
正则表达式有时候可能会失效,失效的原因有很多,不过大多数是因为网页的结构发生了变化。
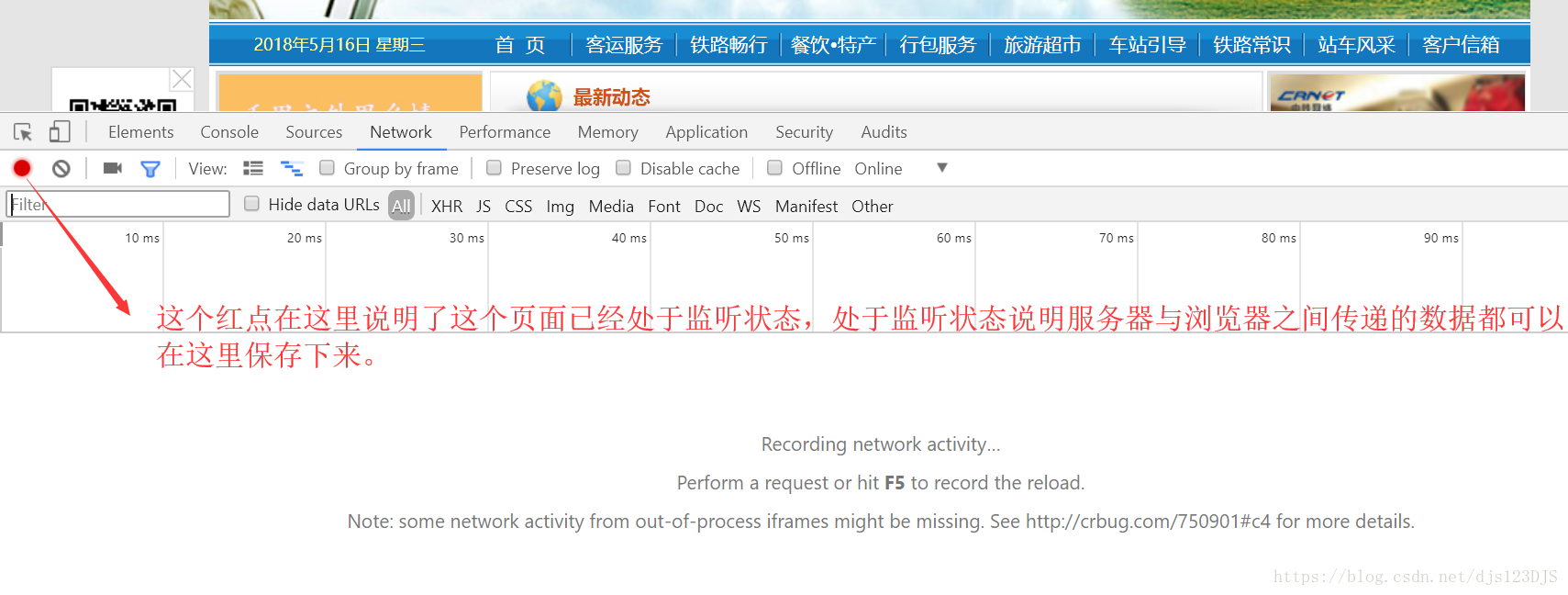
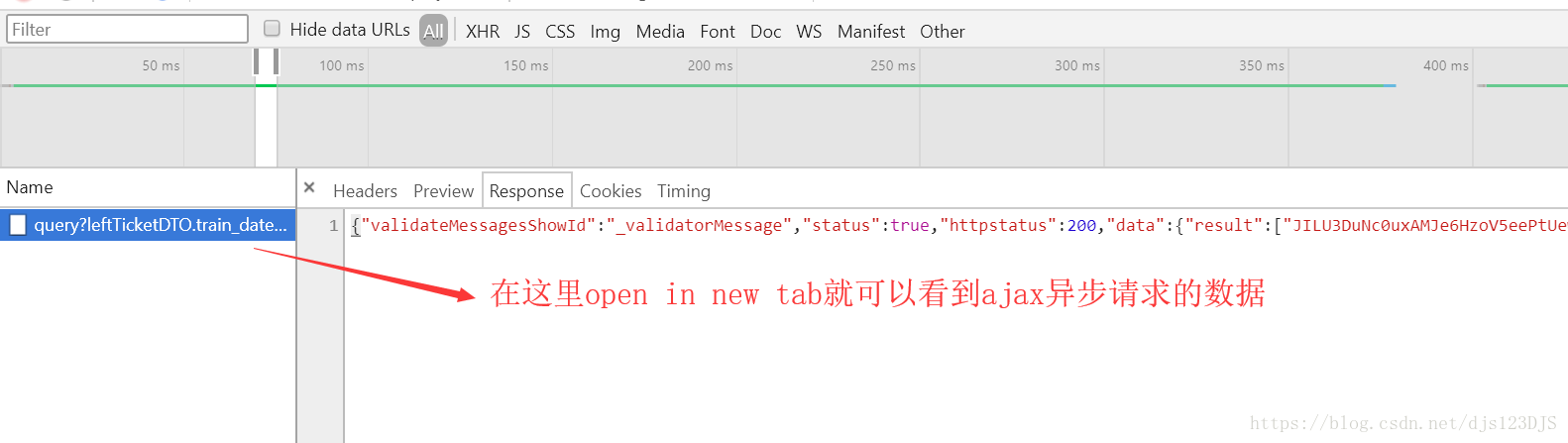
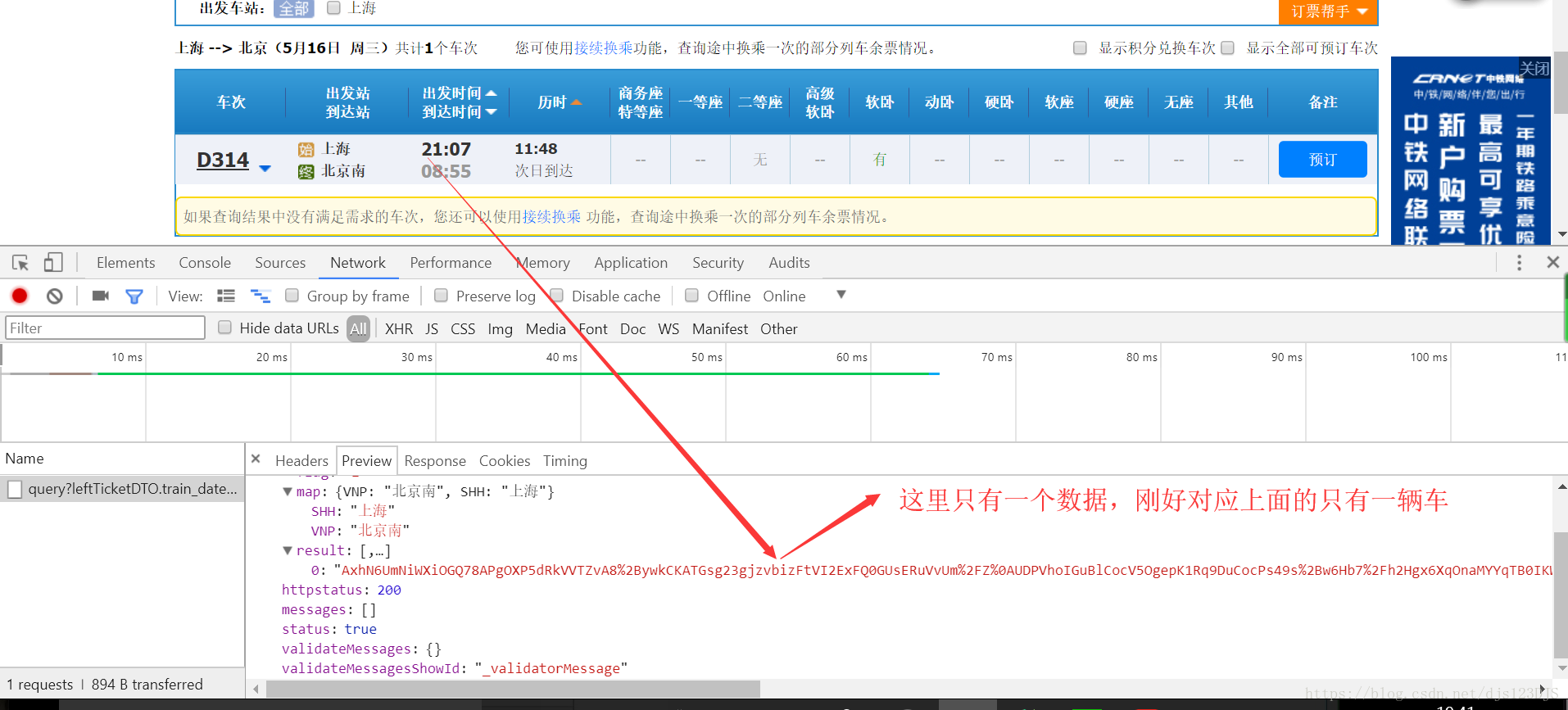
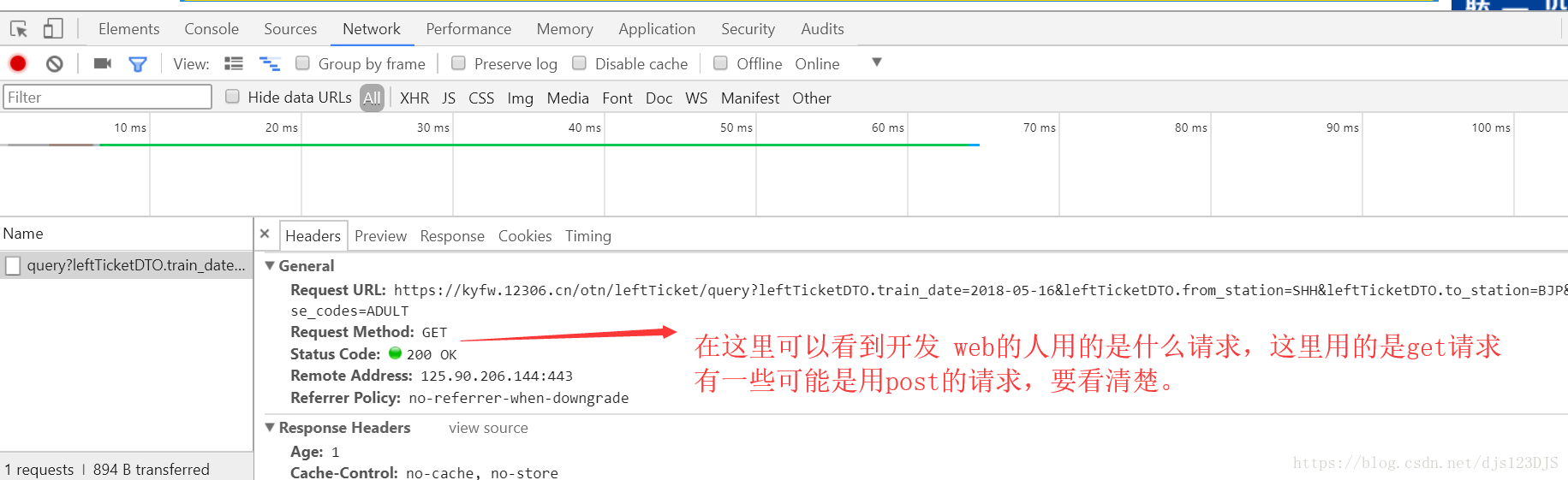
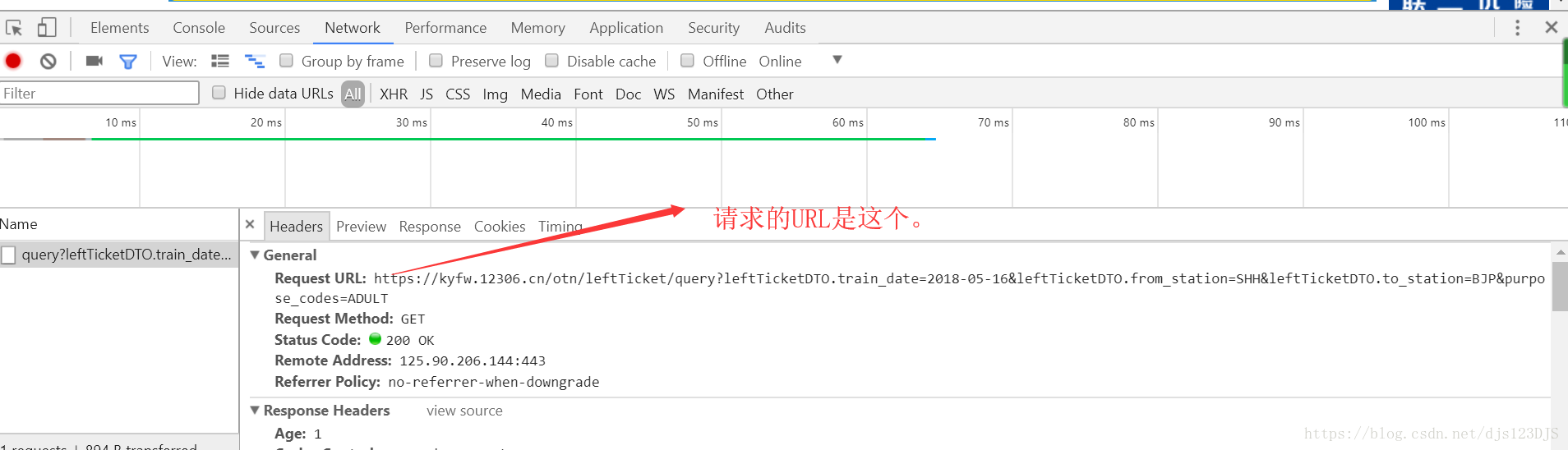
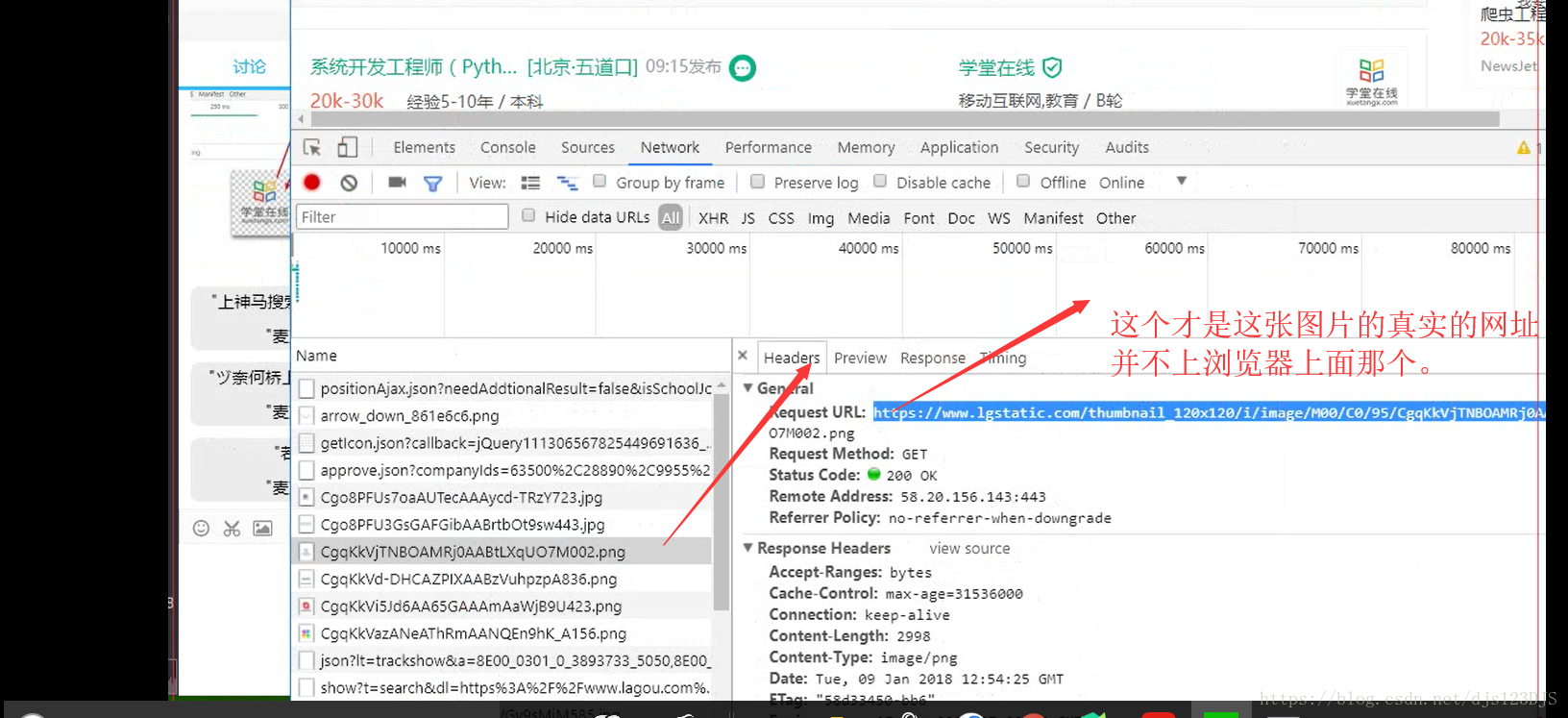
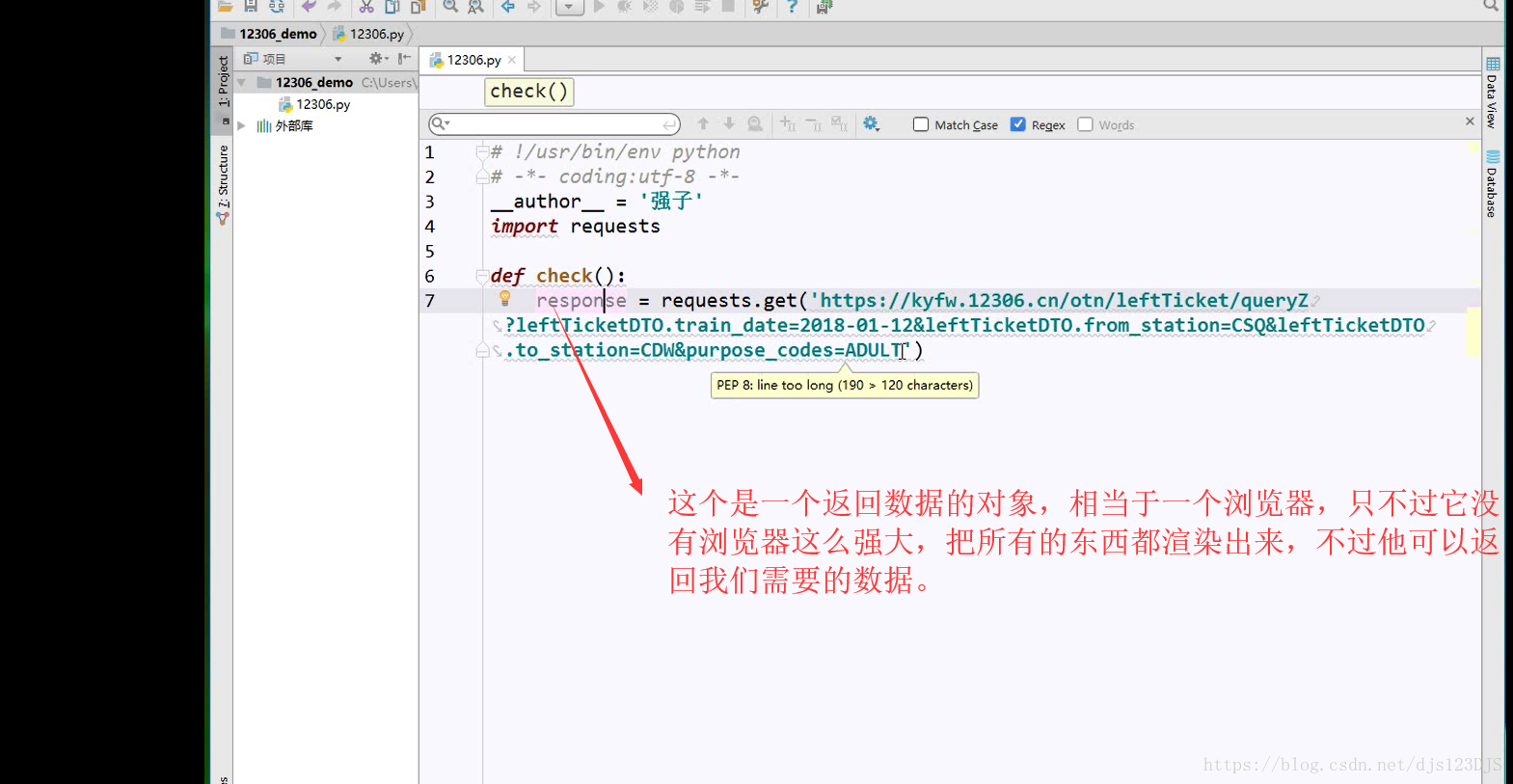
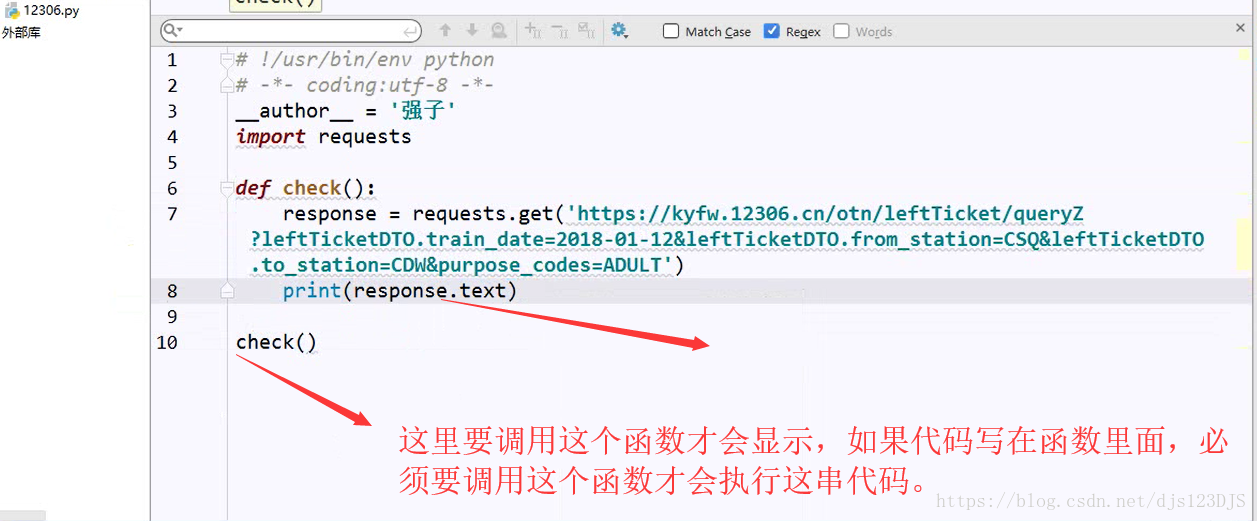
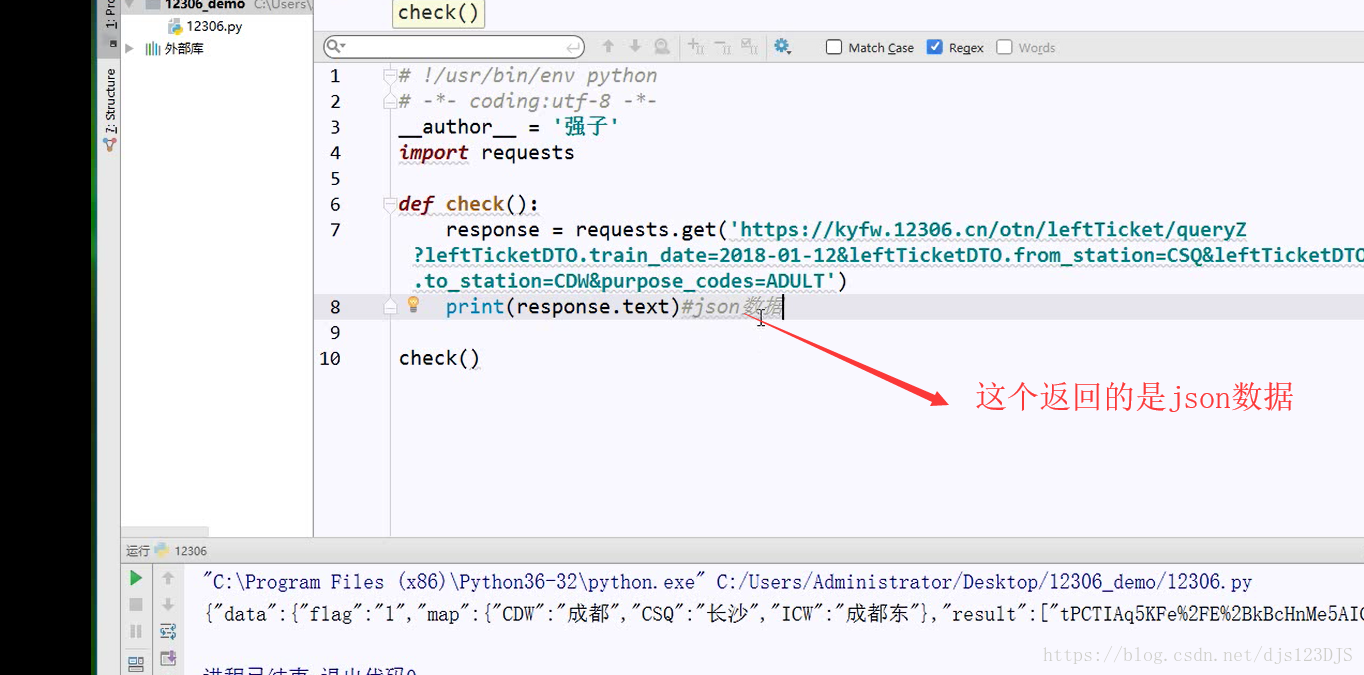
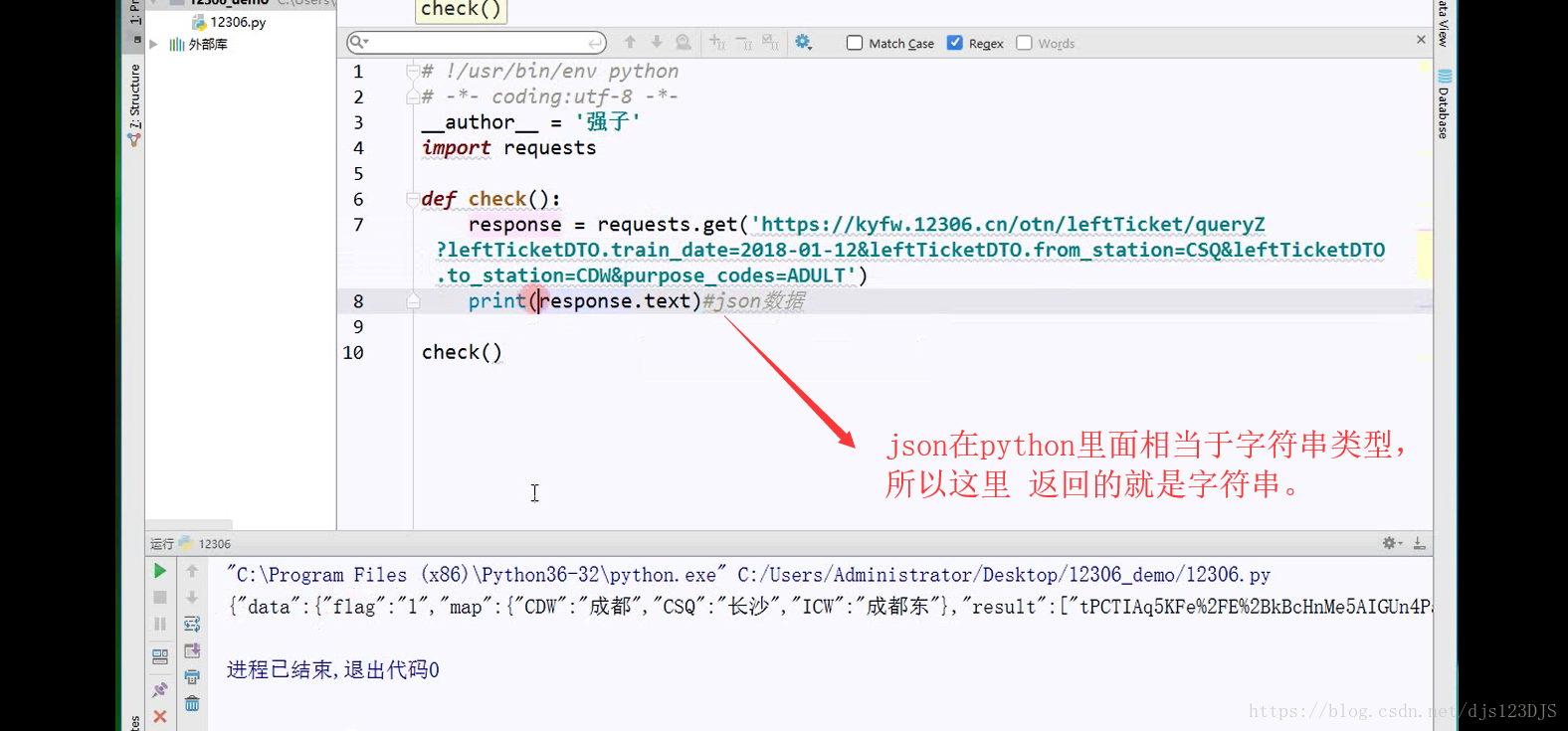
response 返回的其实URL的源代码。


















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









