




 本文探讨了MVC设计模式及前后端分离的概念,并详细分析了前后端分离下爬虫技术的应用方法。包括如何判断数据加载方式、解决乱码问题等。
本文探讨了MVC设计模式及前后端分离的概念,并详细分析了前后端分离下爬虫技术的应用方法。包括如何判断数据加载方式、解决乱码问题等。
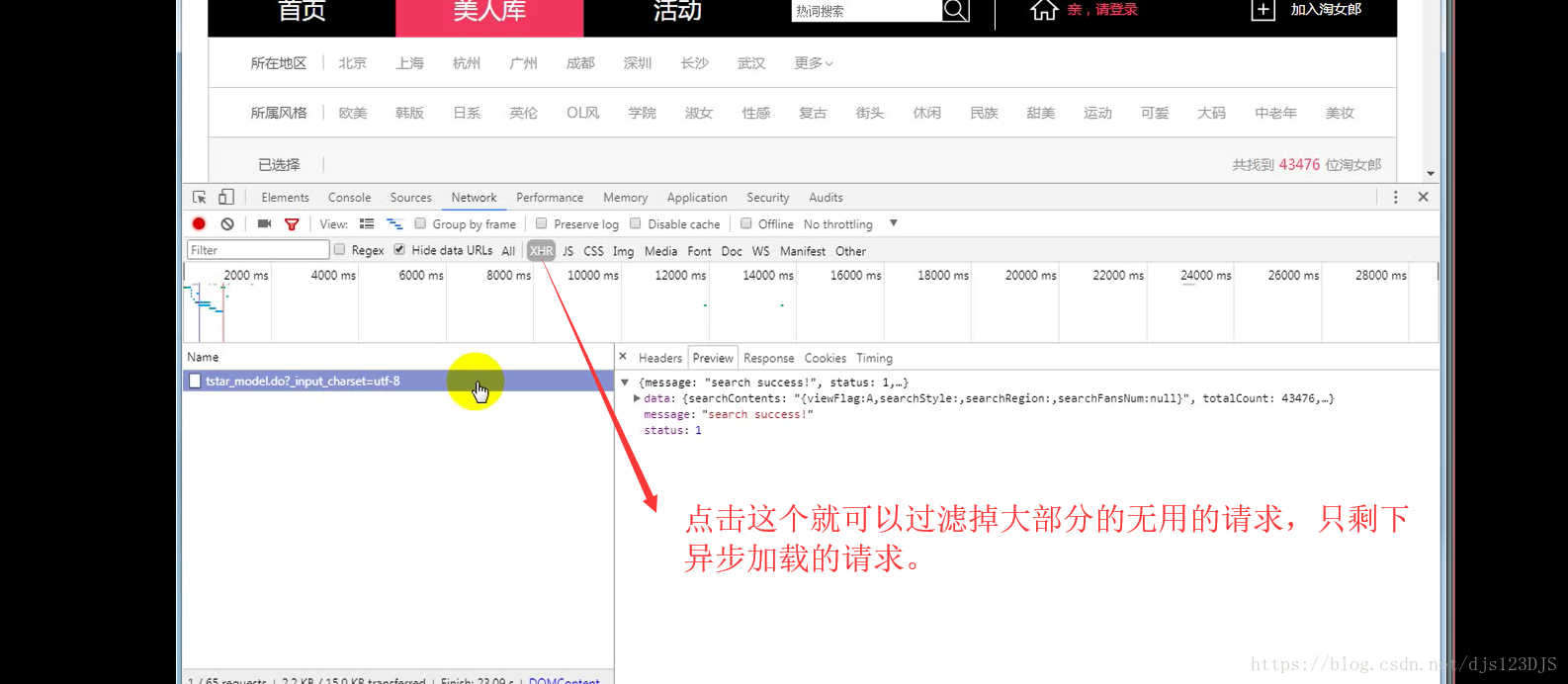
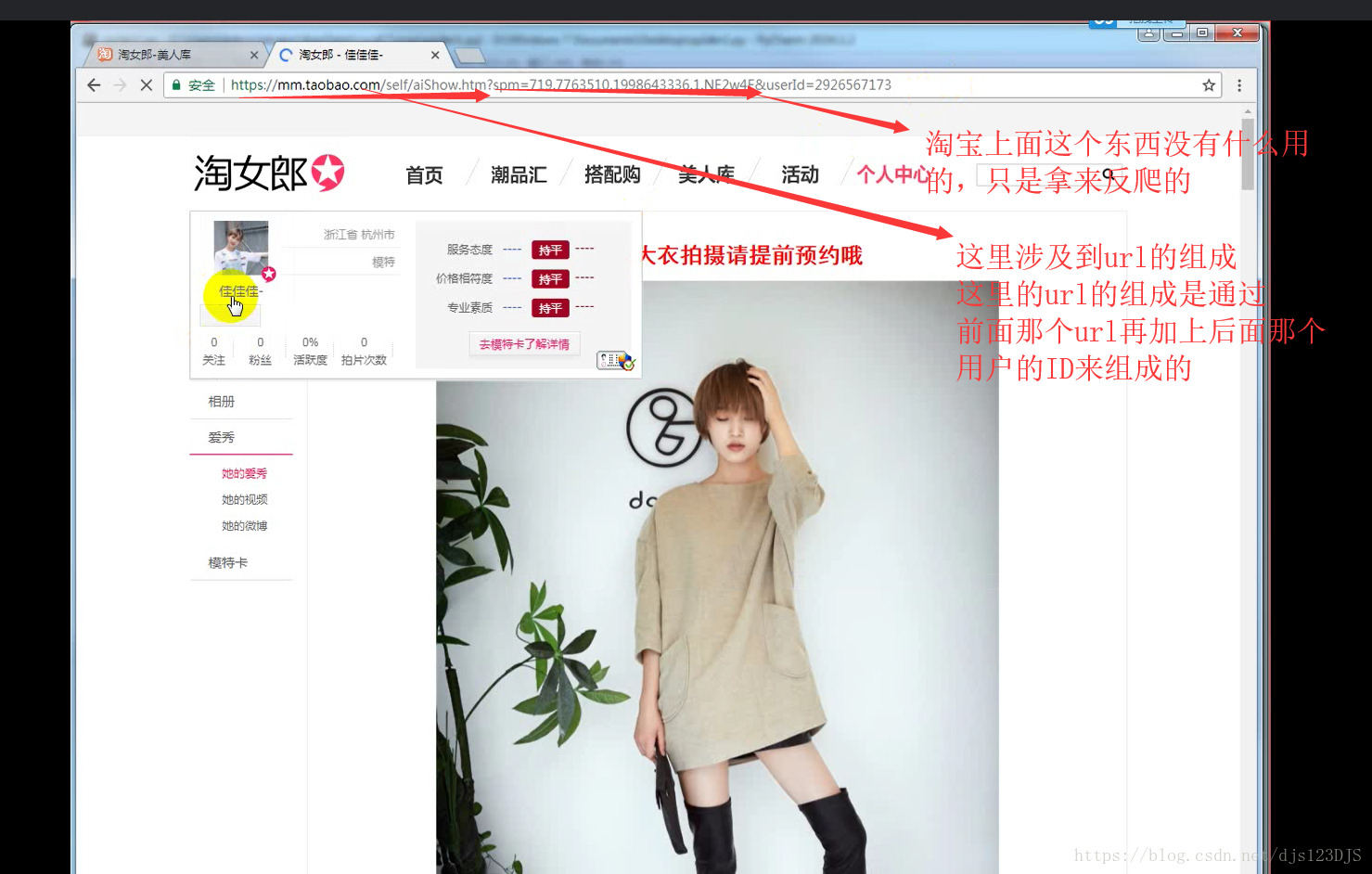
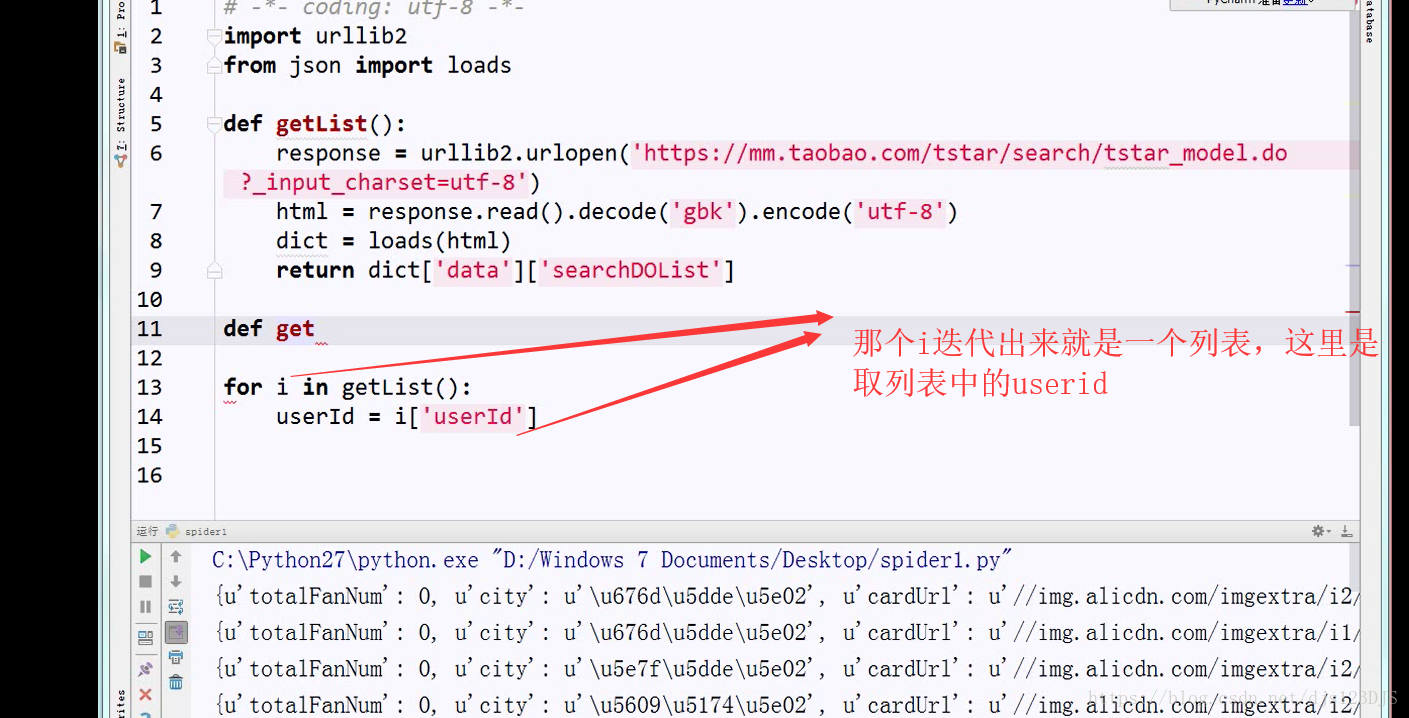
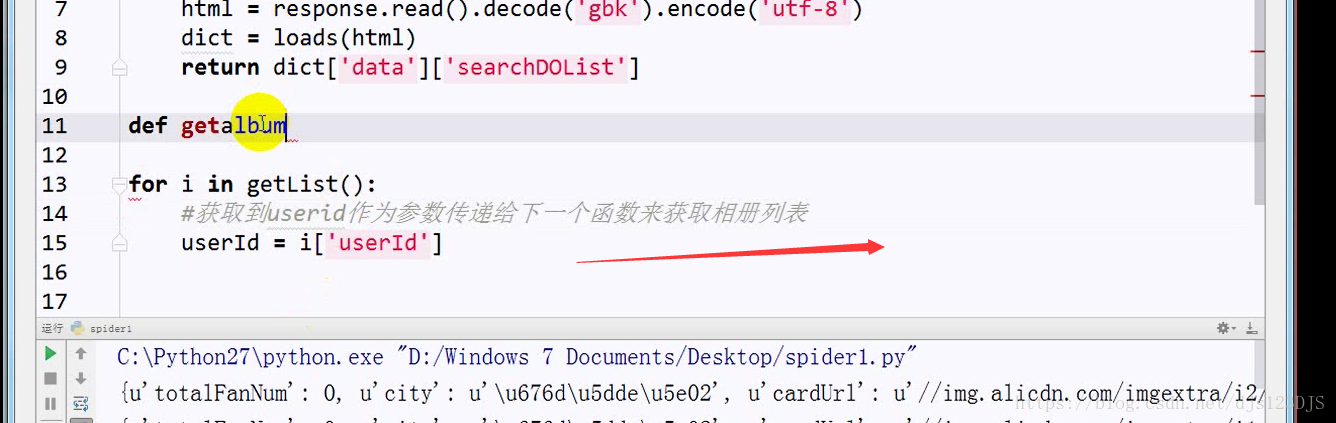
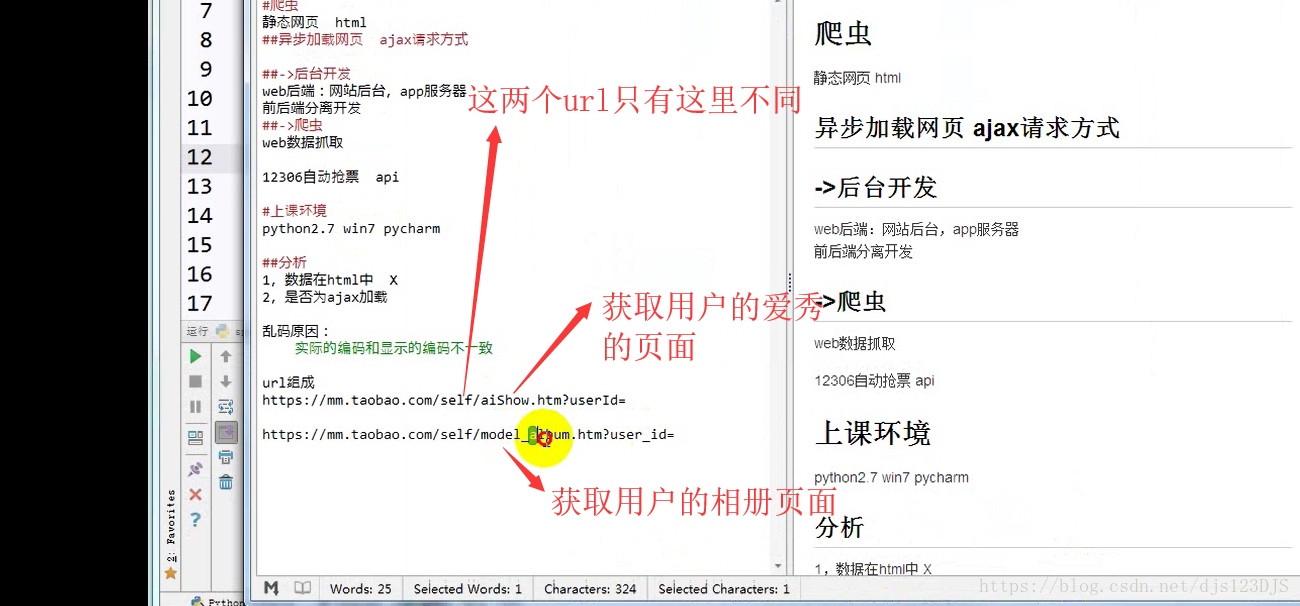
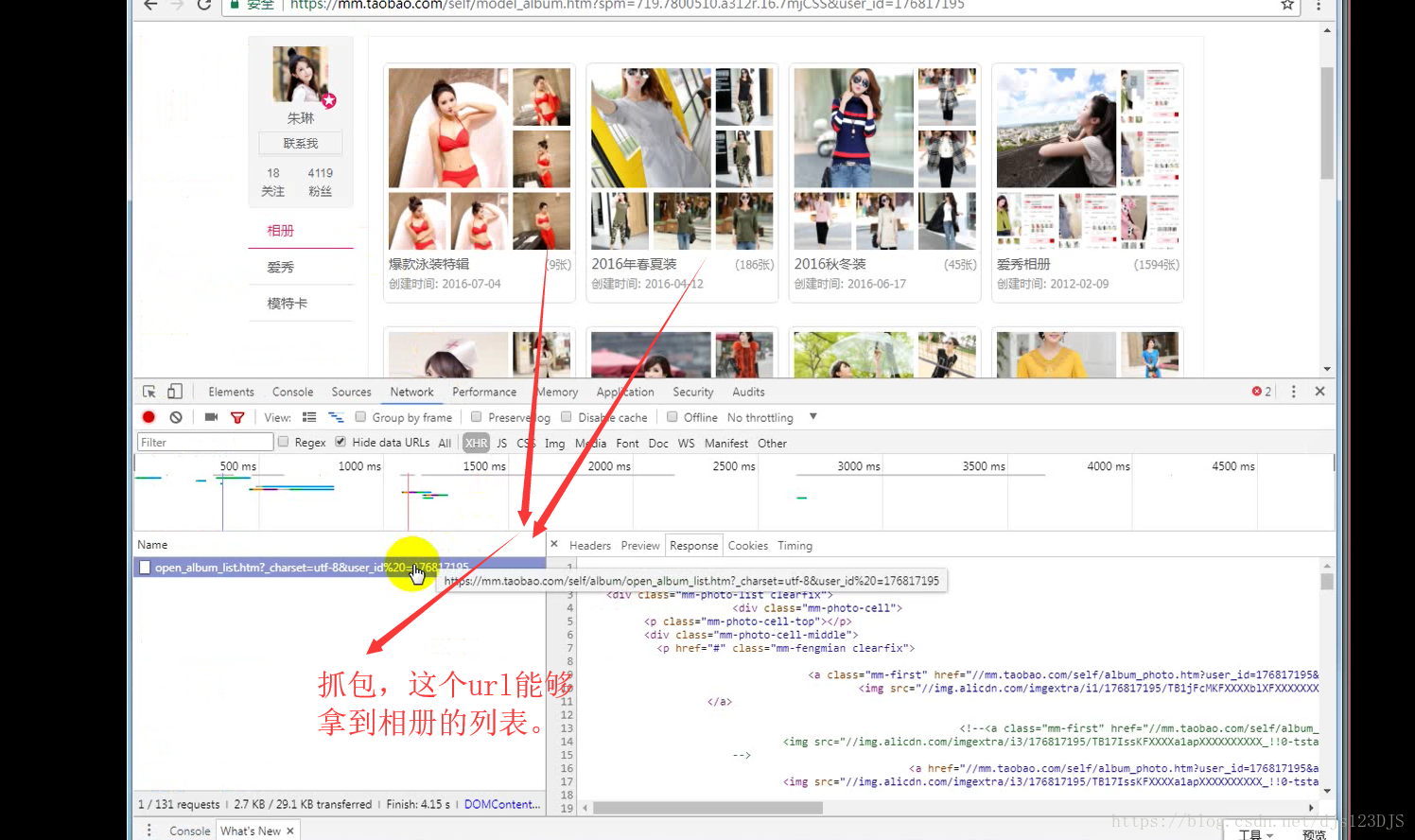
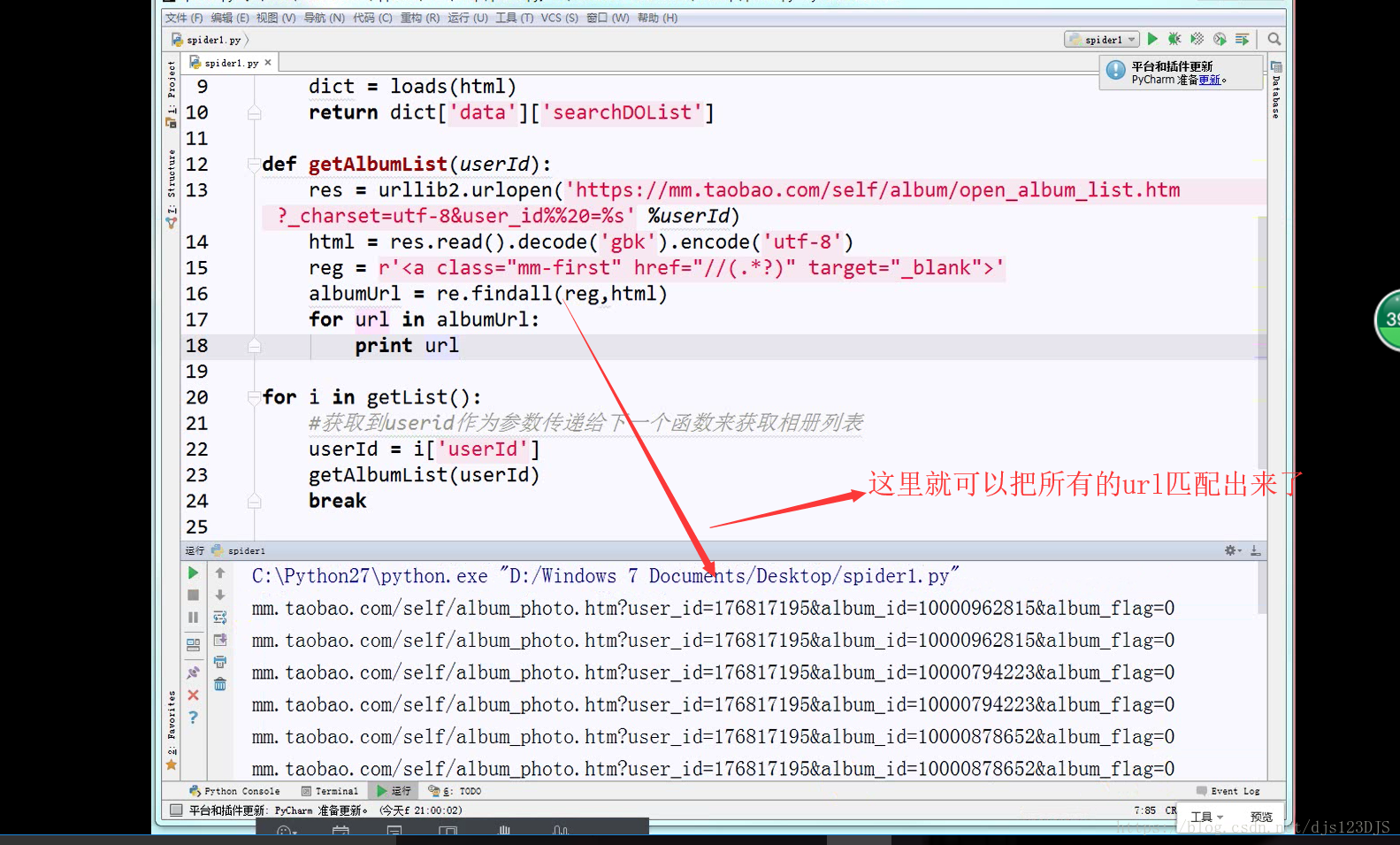
MVC设计模式可以说是前后端分离,现在的网站一般都是采用前后端分离的。前后端分离的话用爬虫就要通过抓包来爬取数据了。做爬虫的第一步是分析。
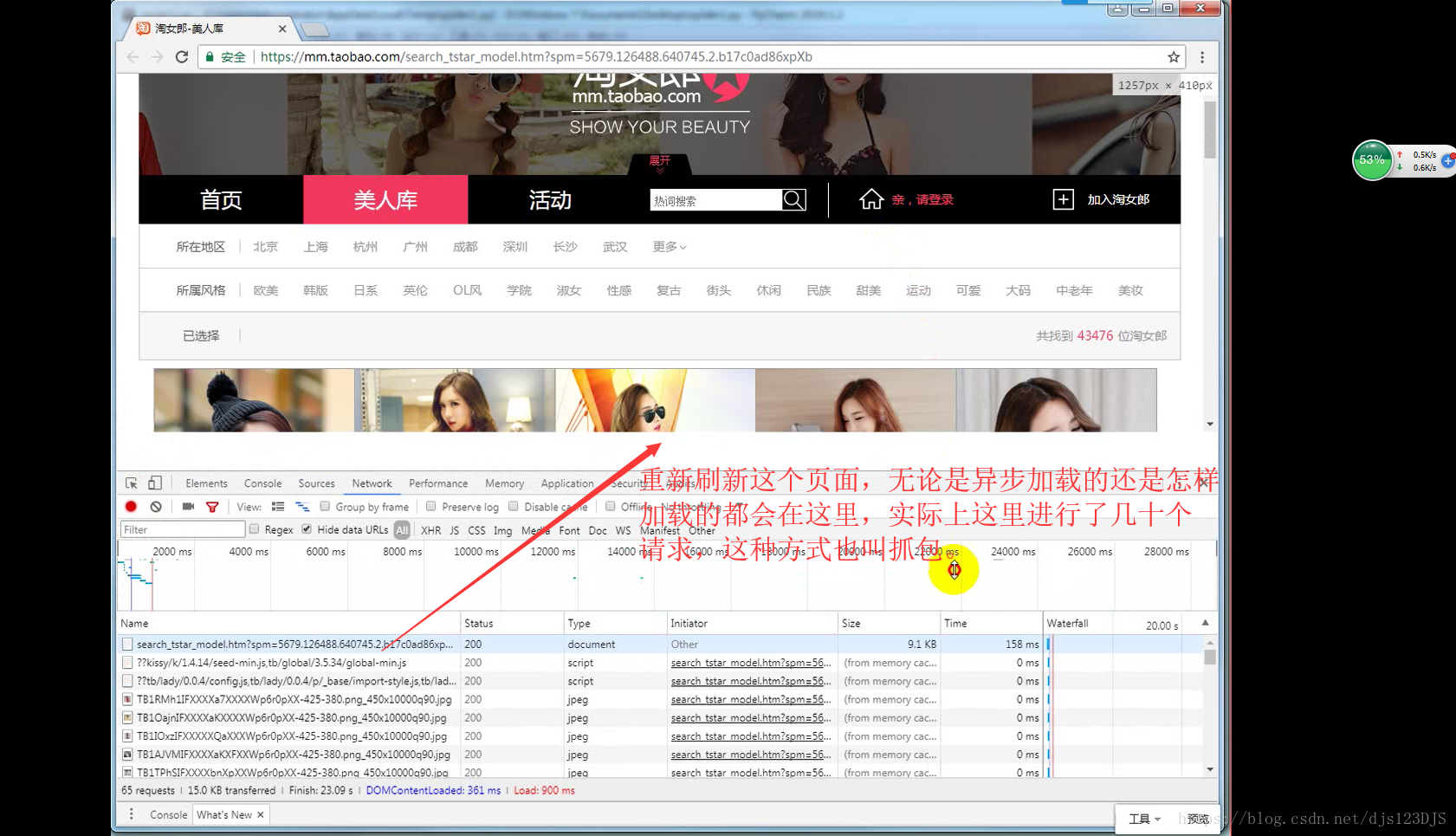
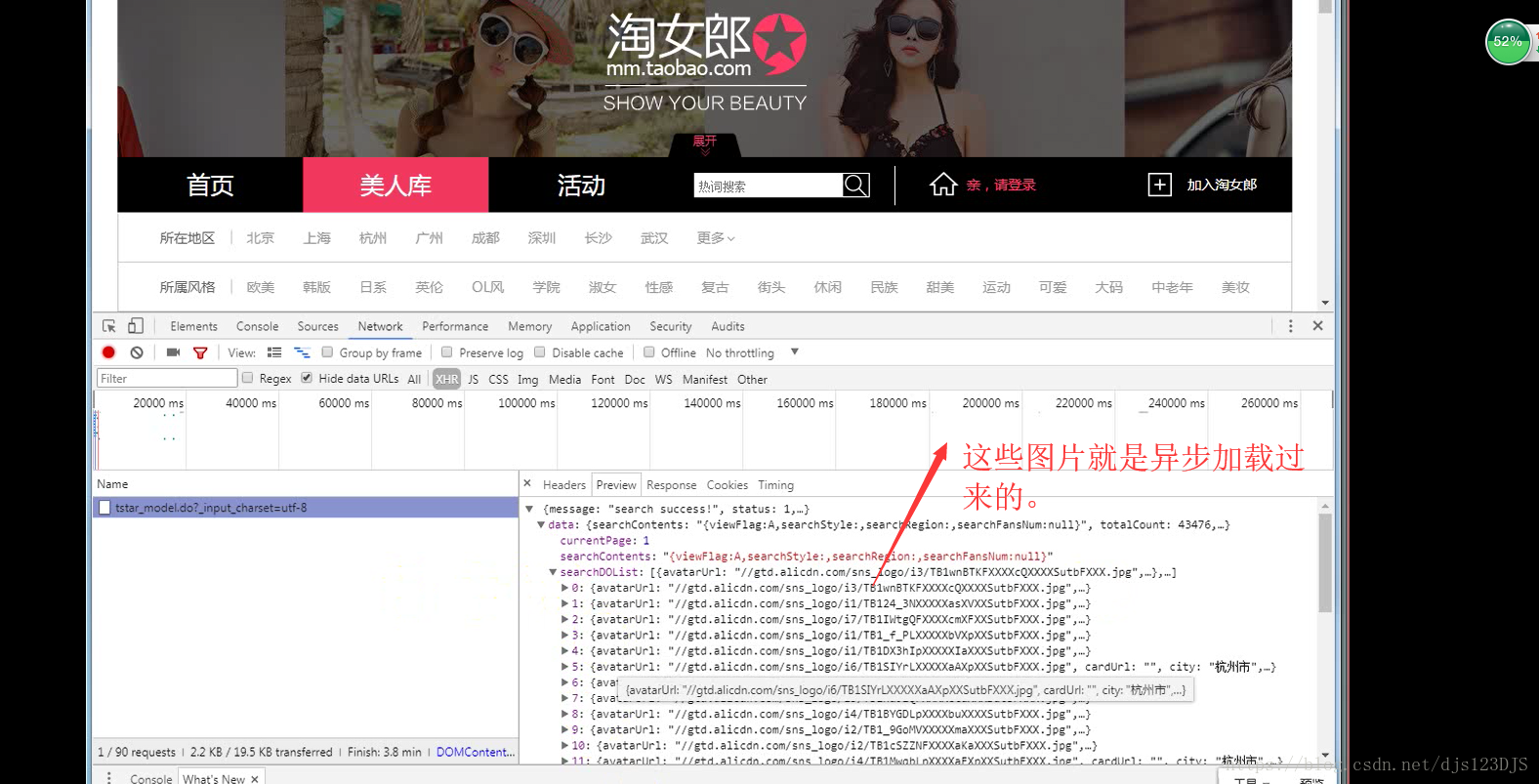
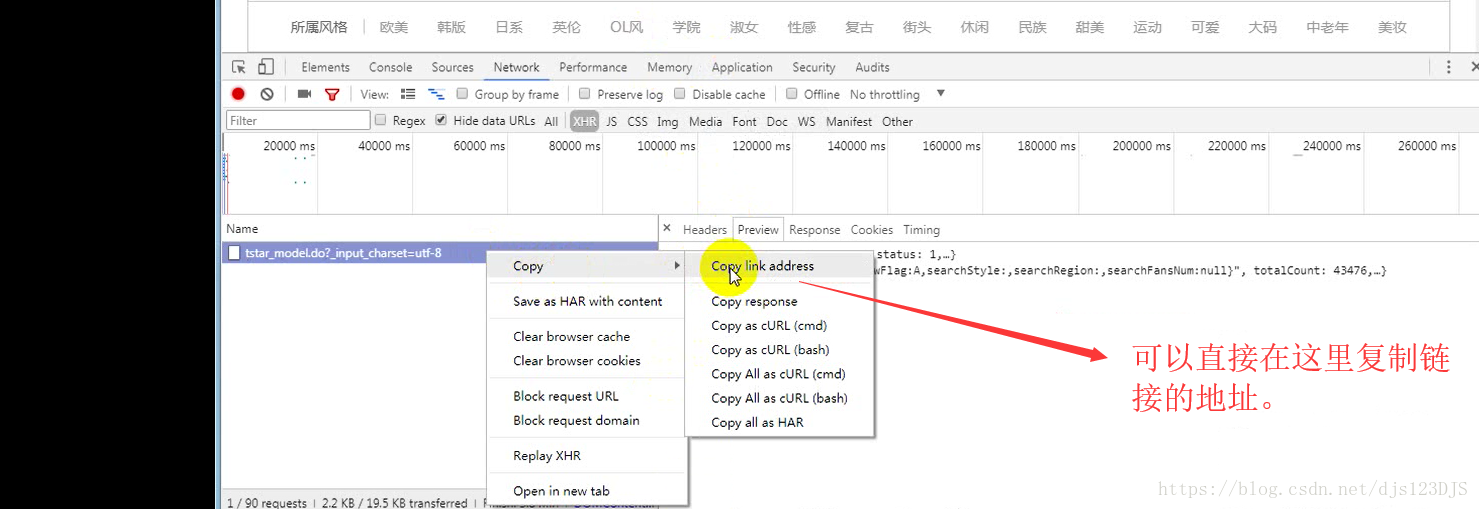
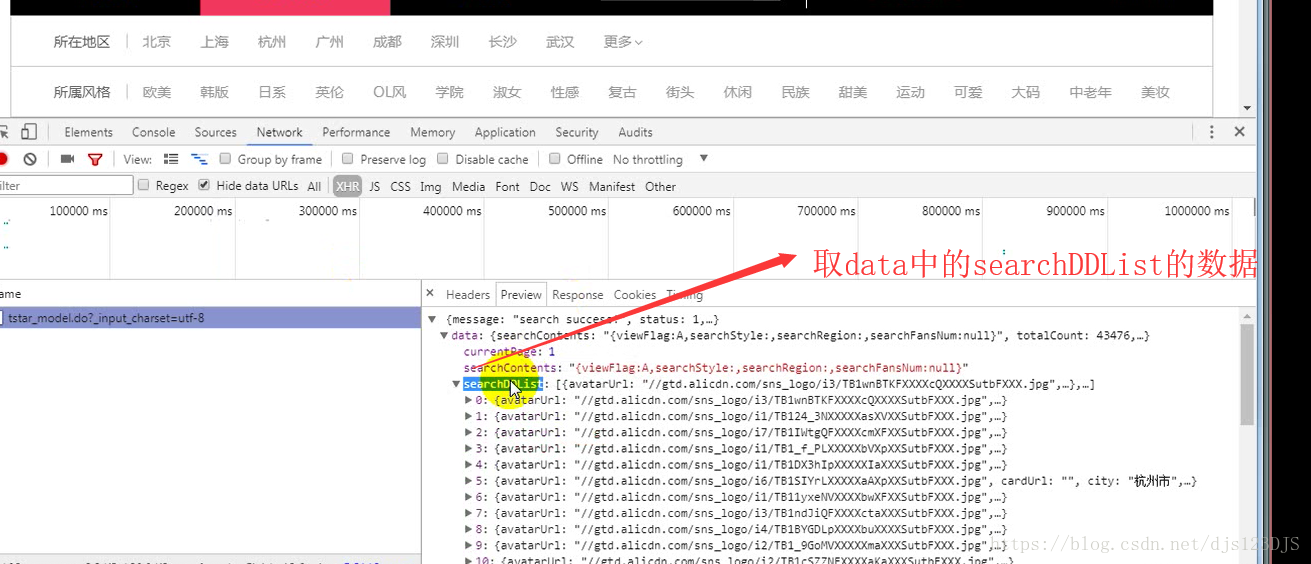
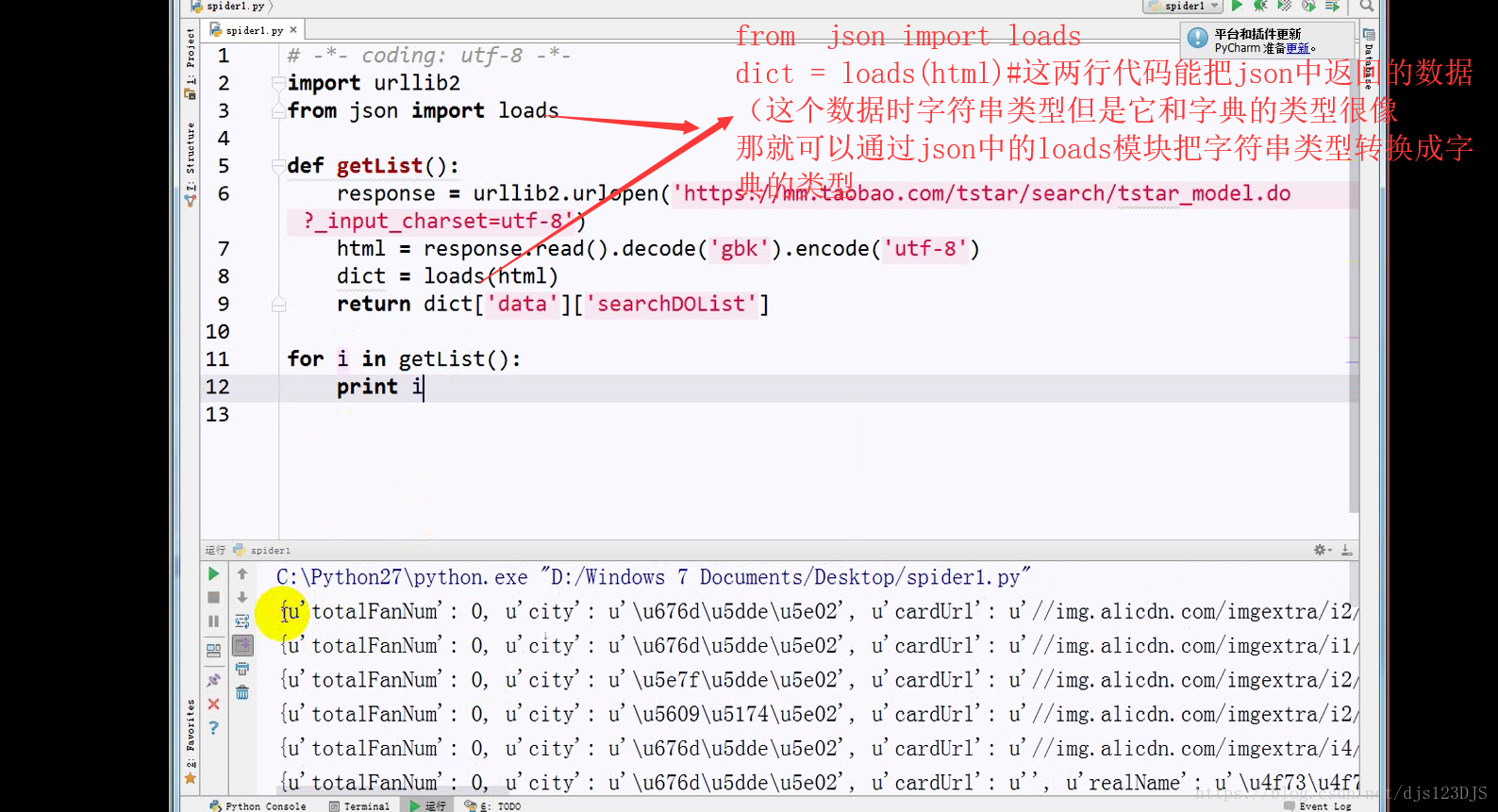
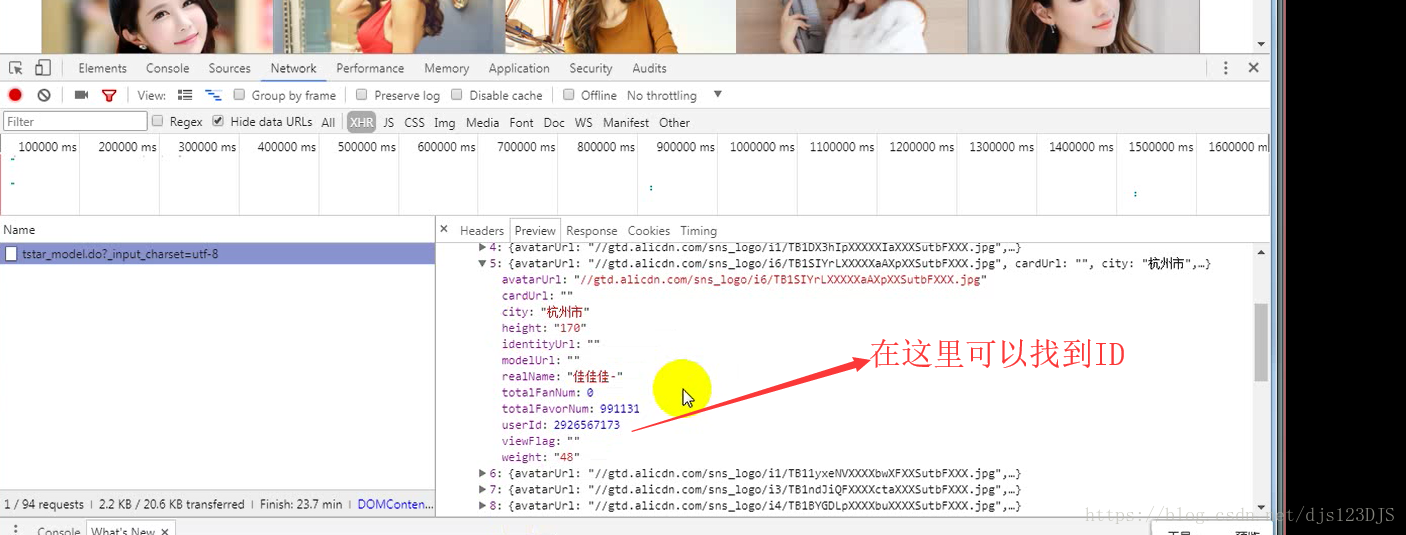
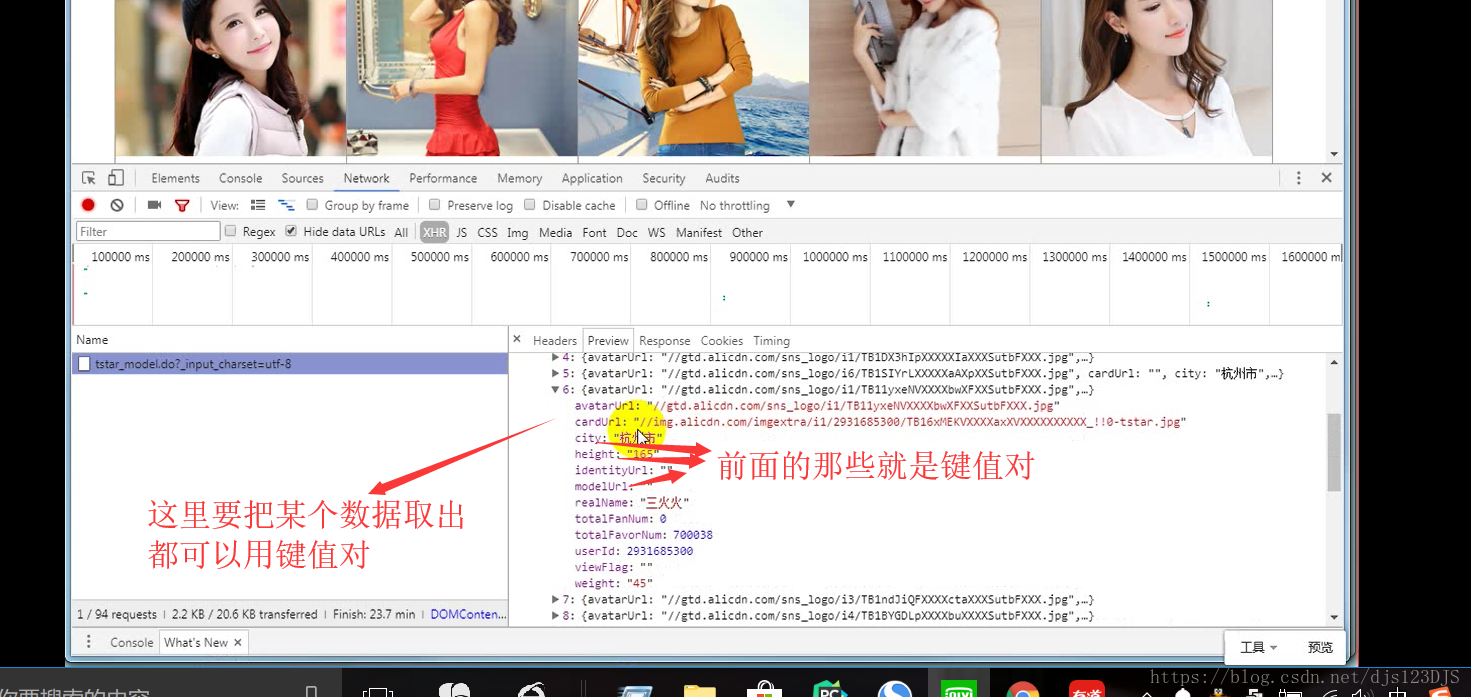
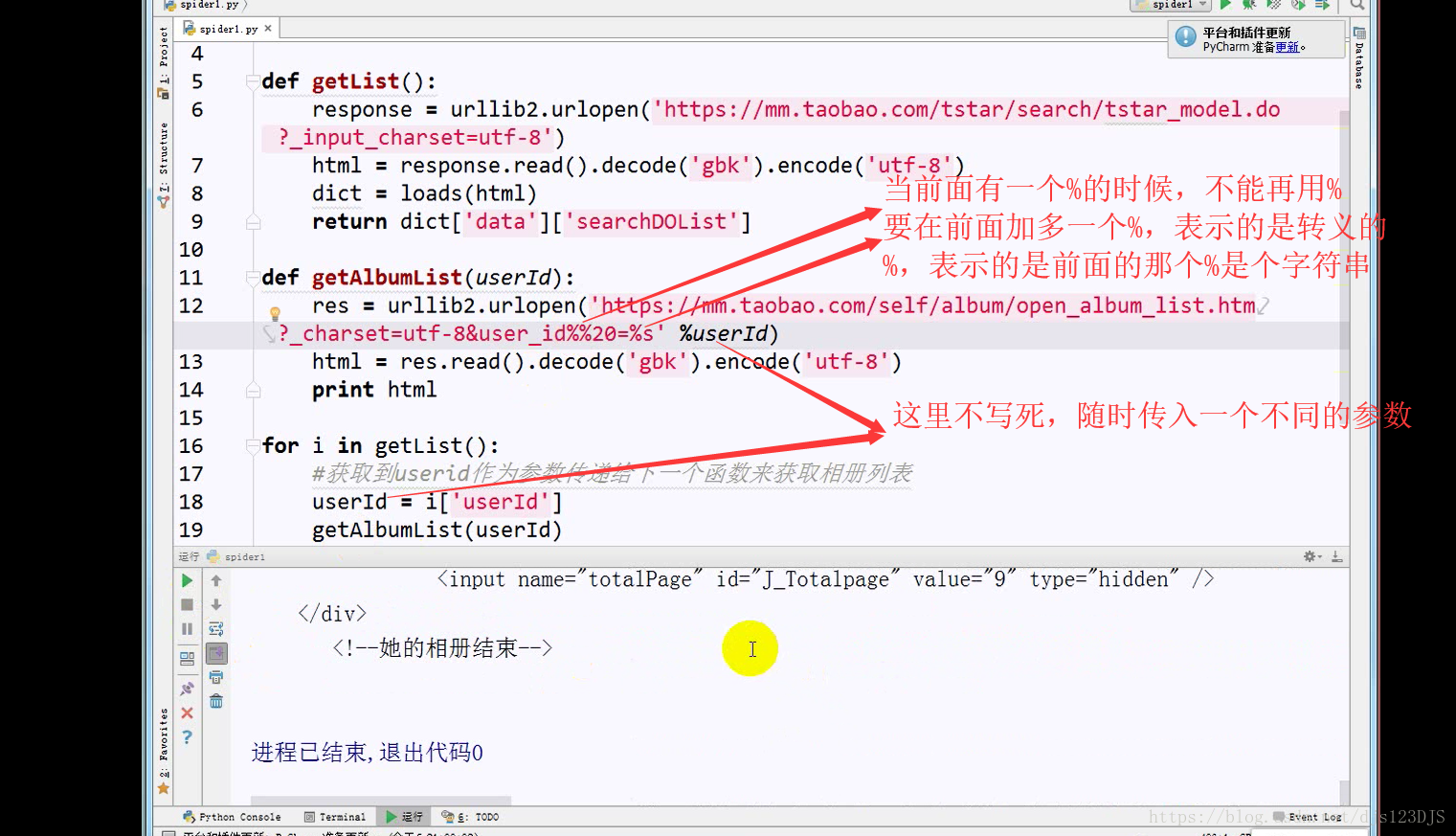
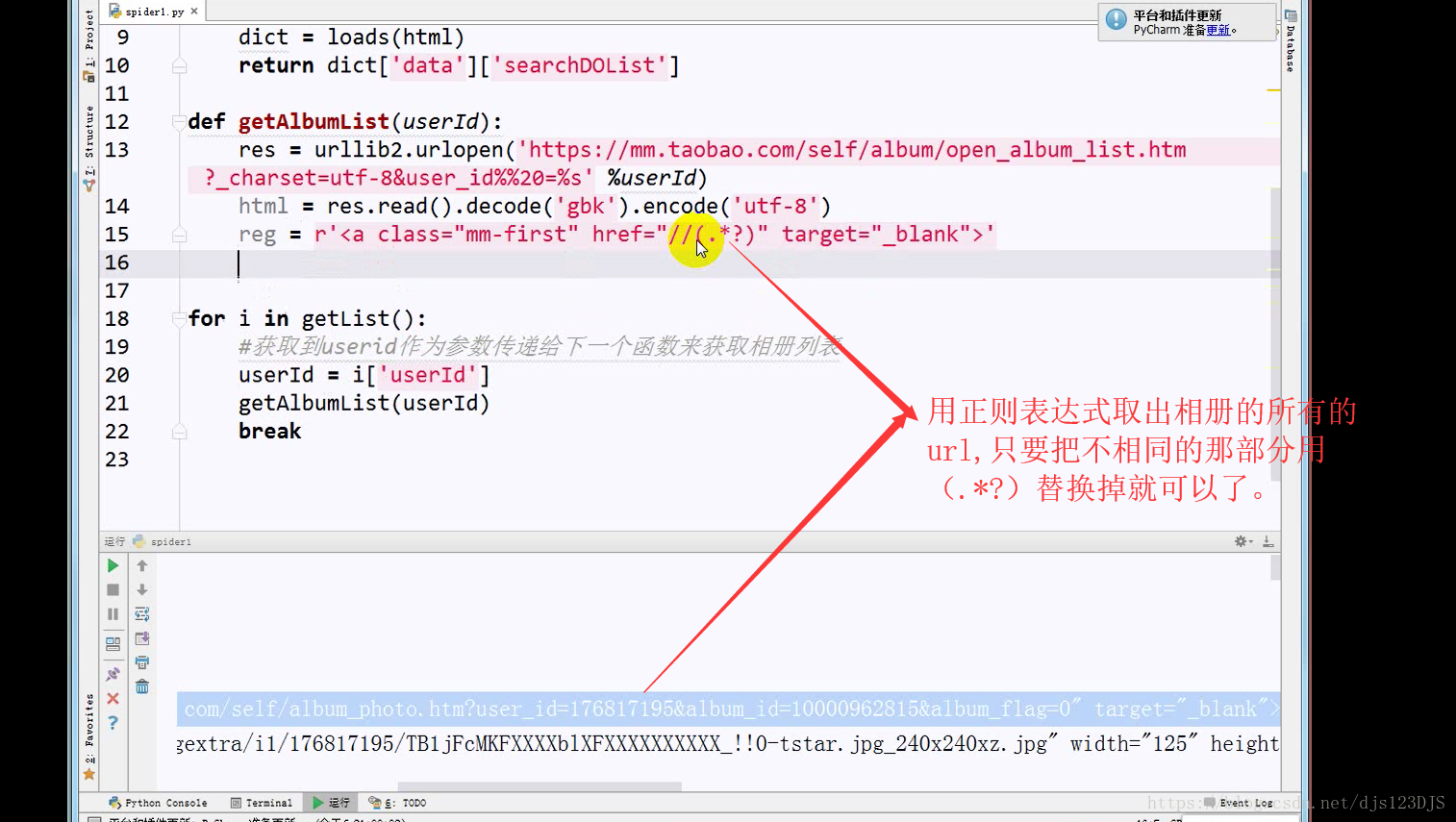
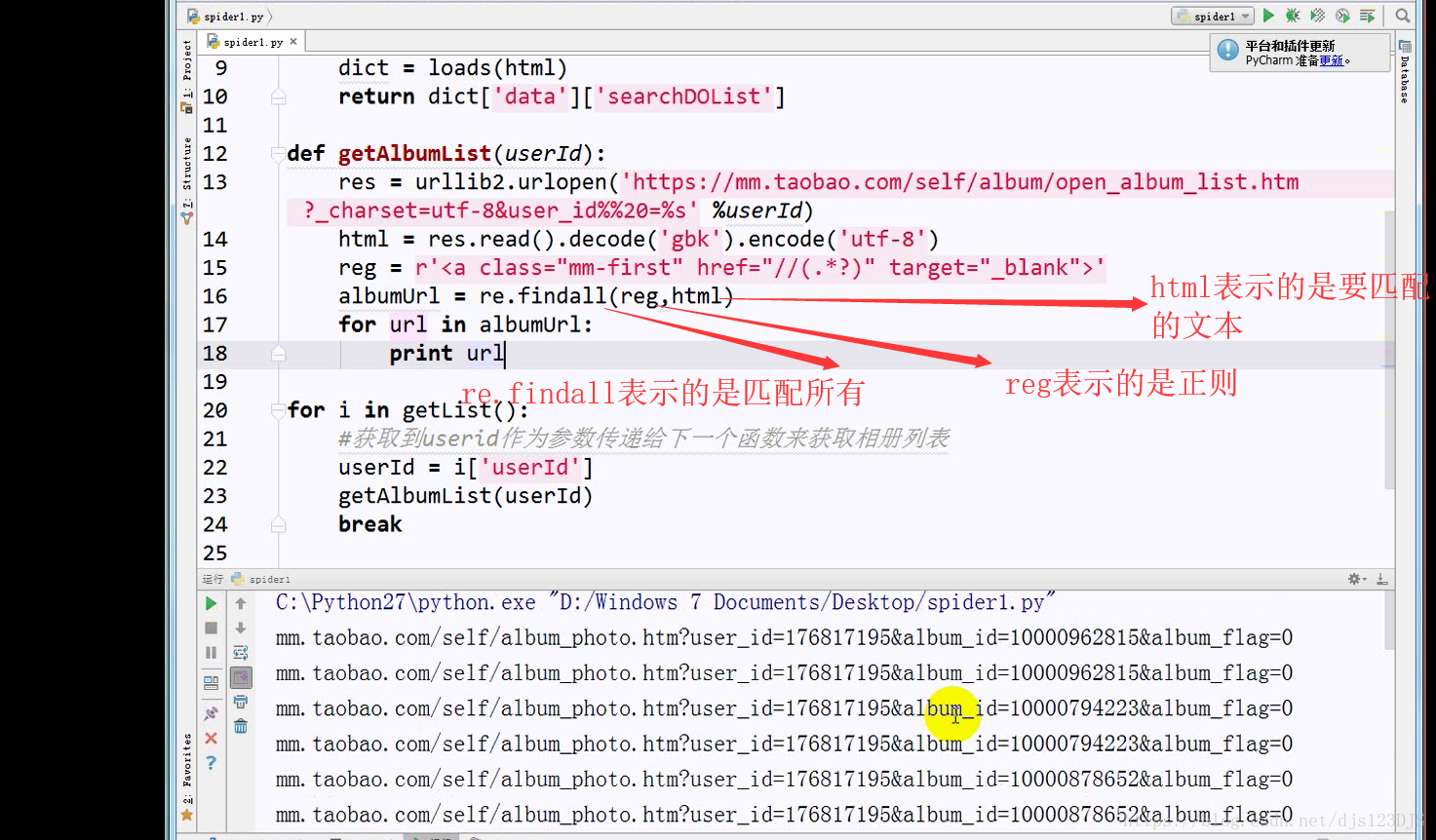
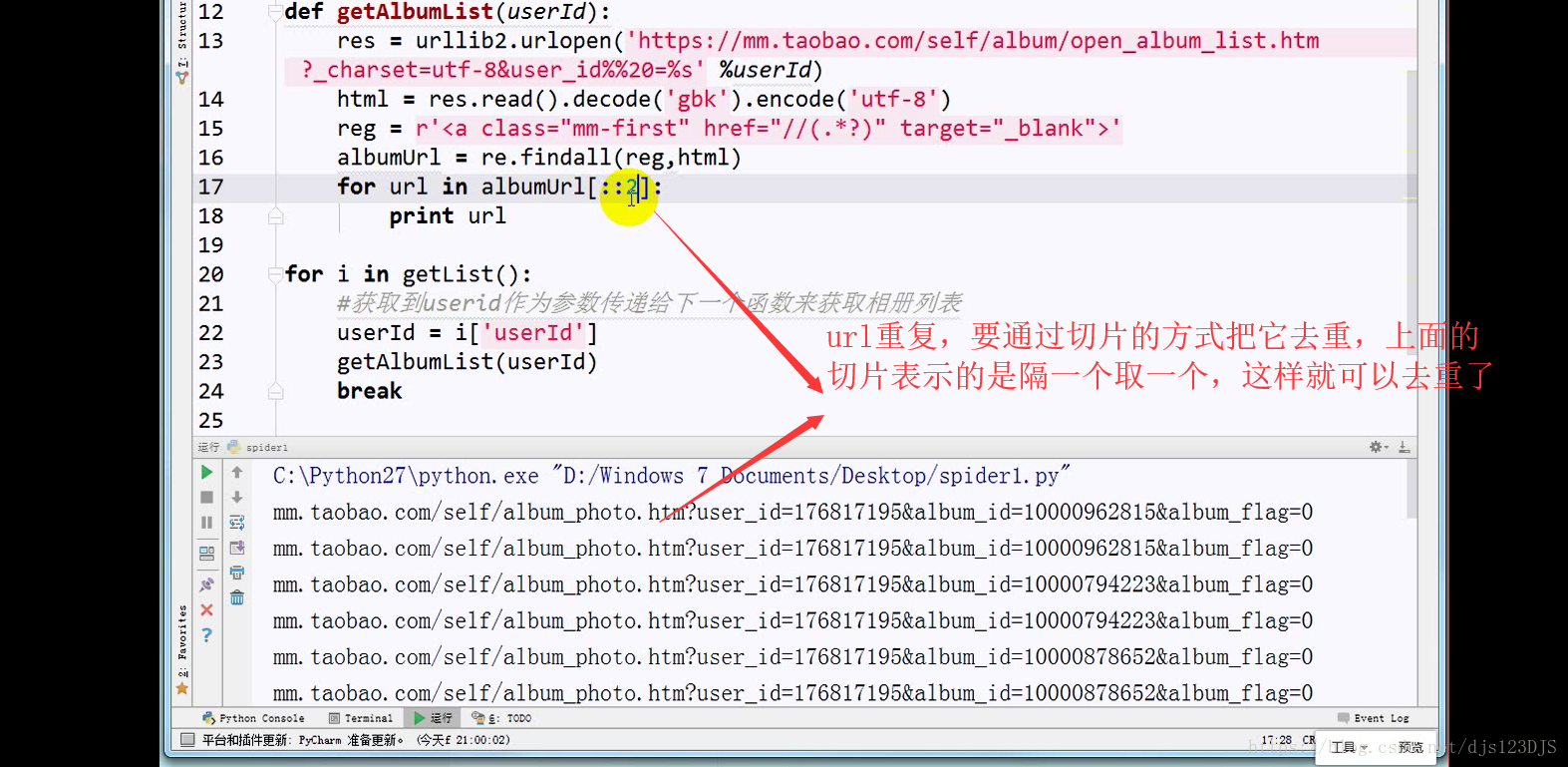
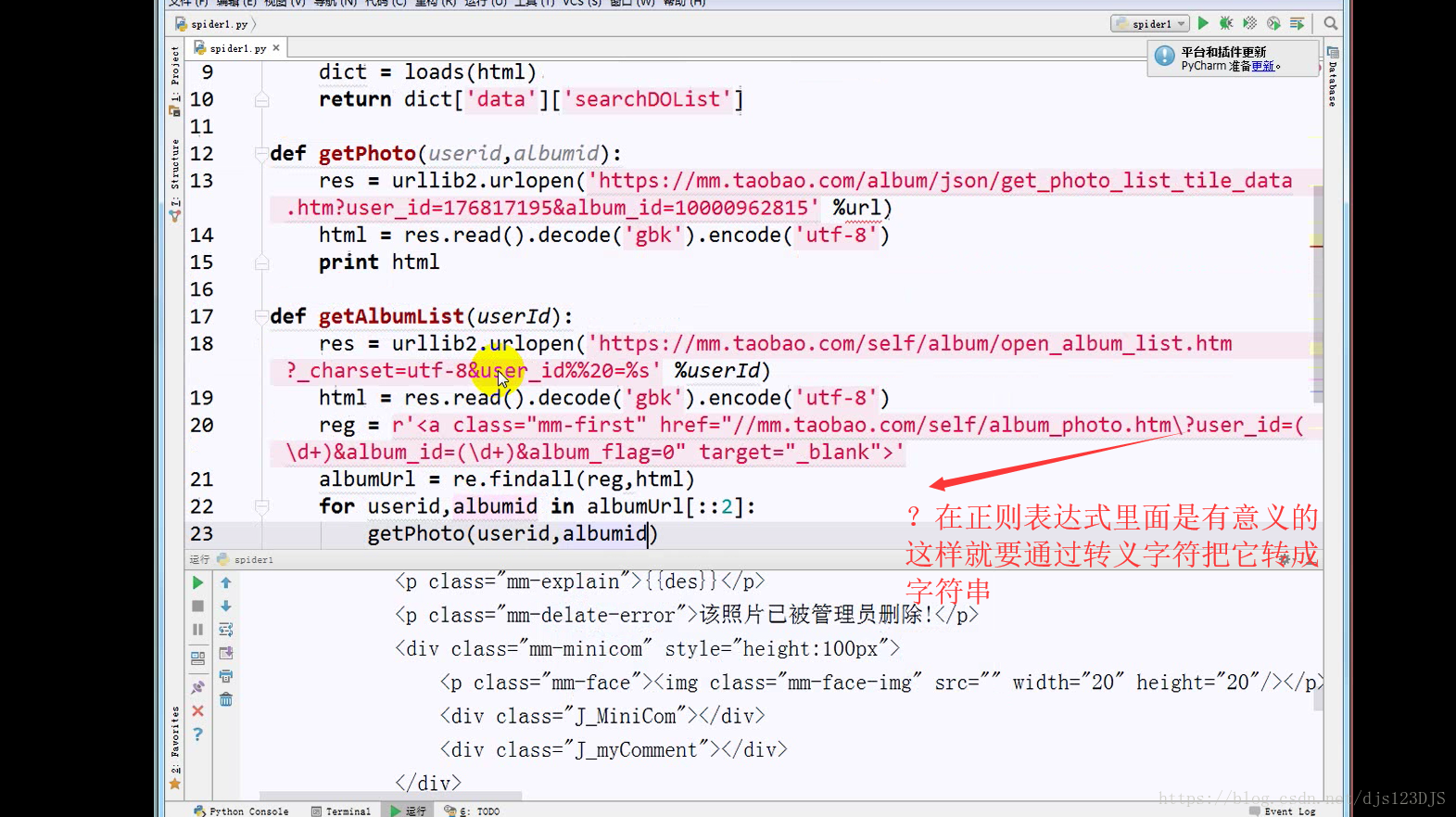
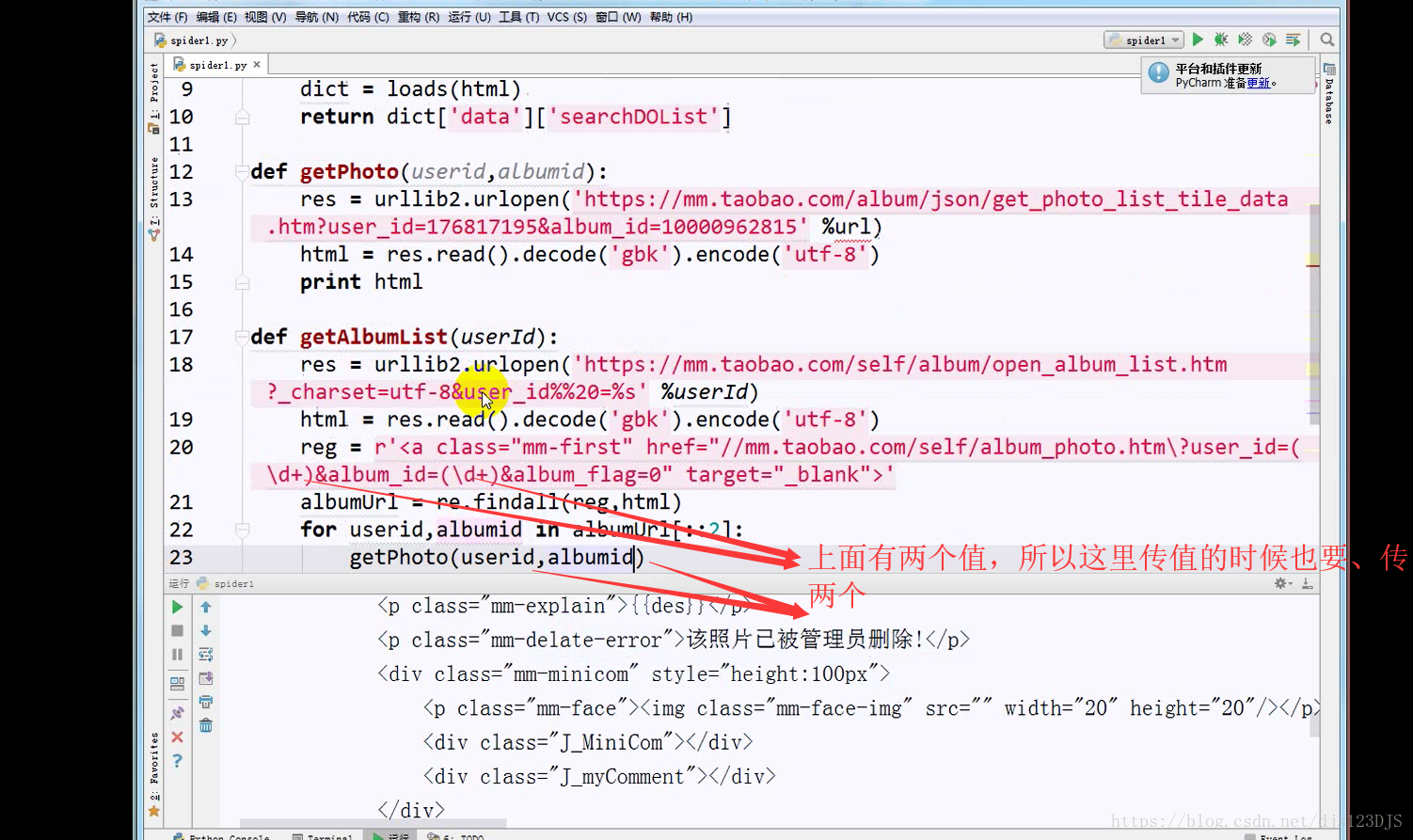
分析:1.数据是否在网页的源代码(html)里面 2.是否为ajax异步加载(用后台API开发)。ajax异步加载对于前端来说开发难度高(因为异步加载不仅要请求后端,还要JS把进行页面的渲染),对于后端来说开发难度低(异步加载后台的请求压力会更低即计算压力低)。爬虫只需要拿动态的数据就可以了,不需要拿样式那些东西。开发的话要多采用模块化开发即是多用函数和类开发。
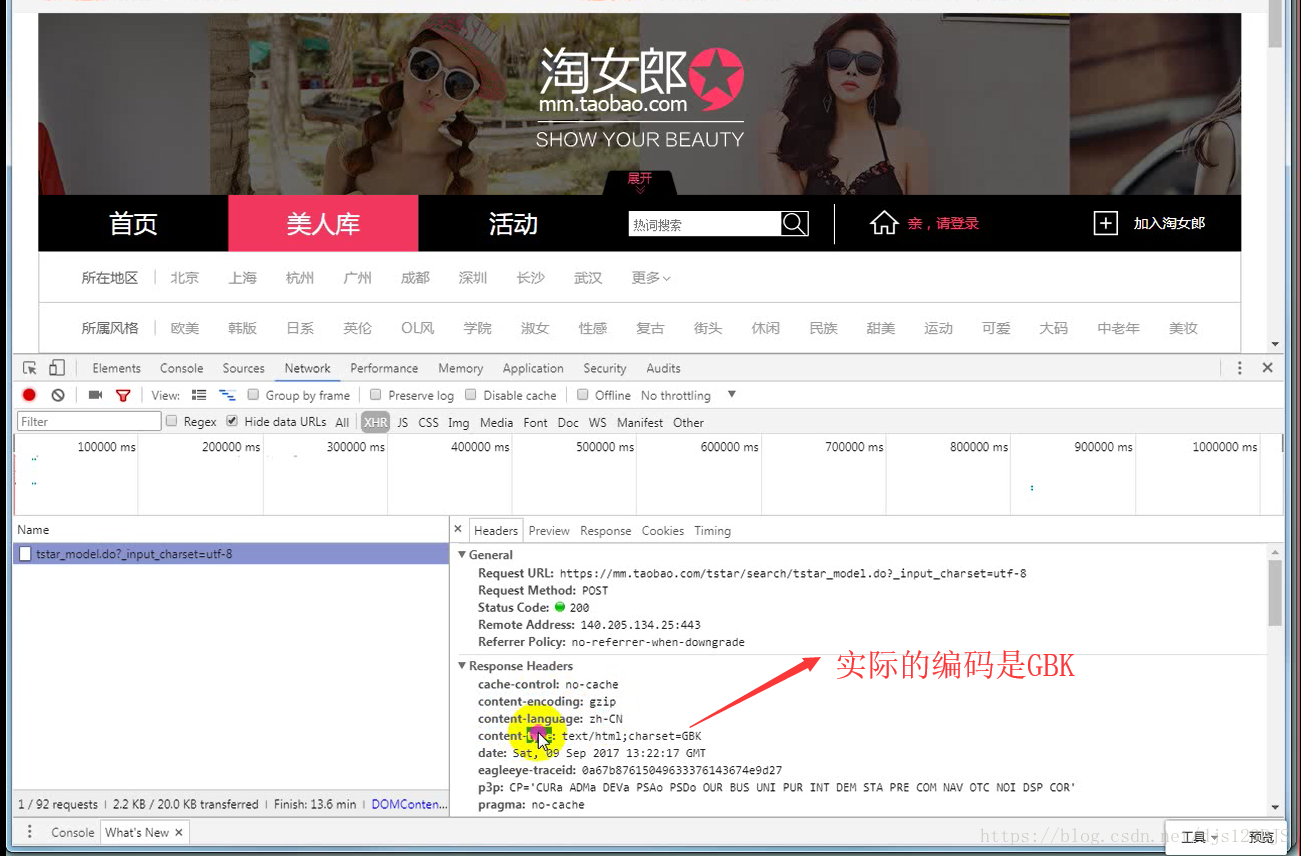
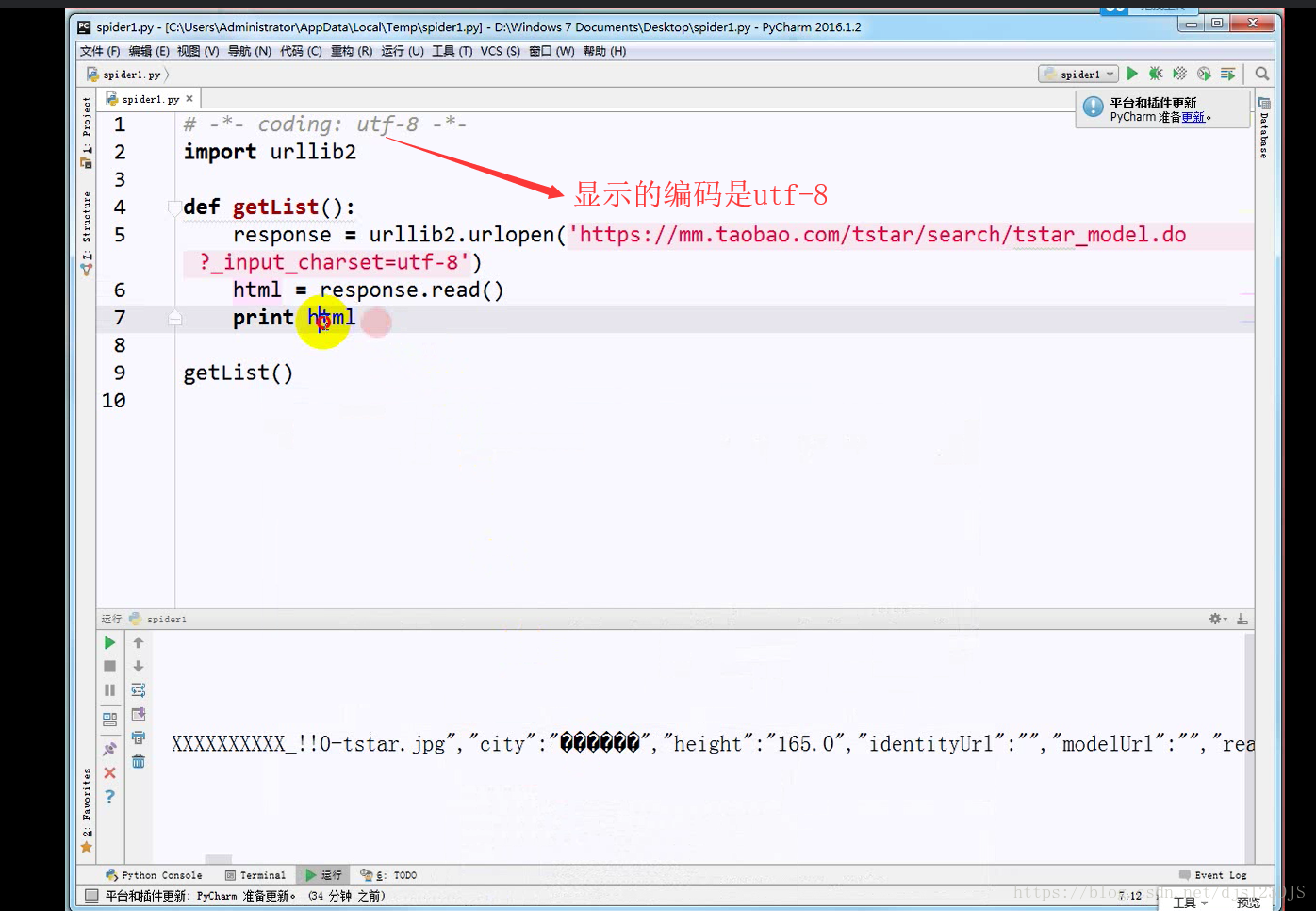
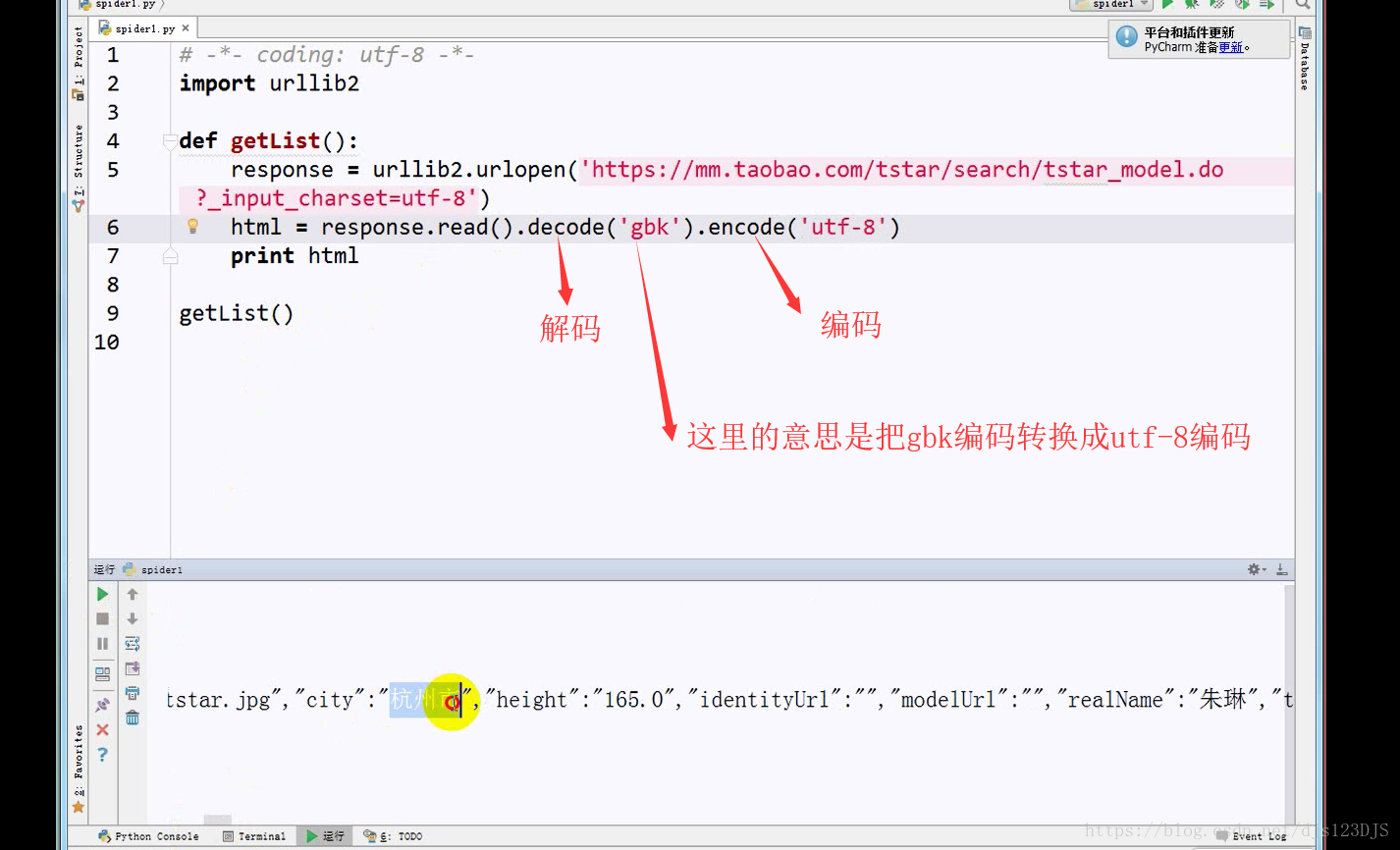
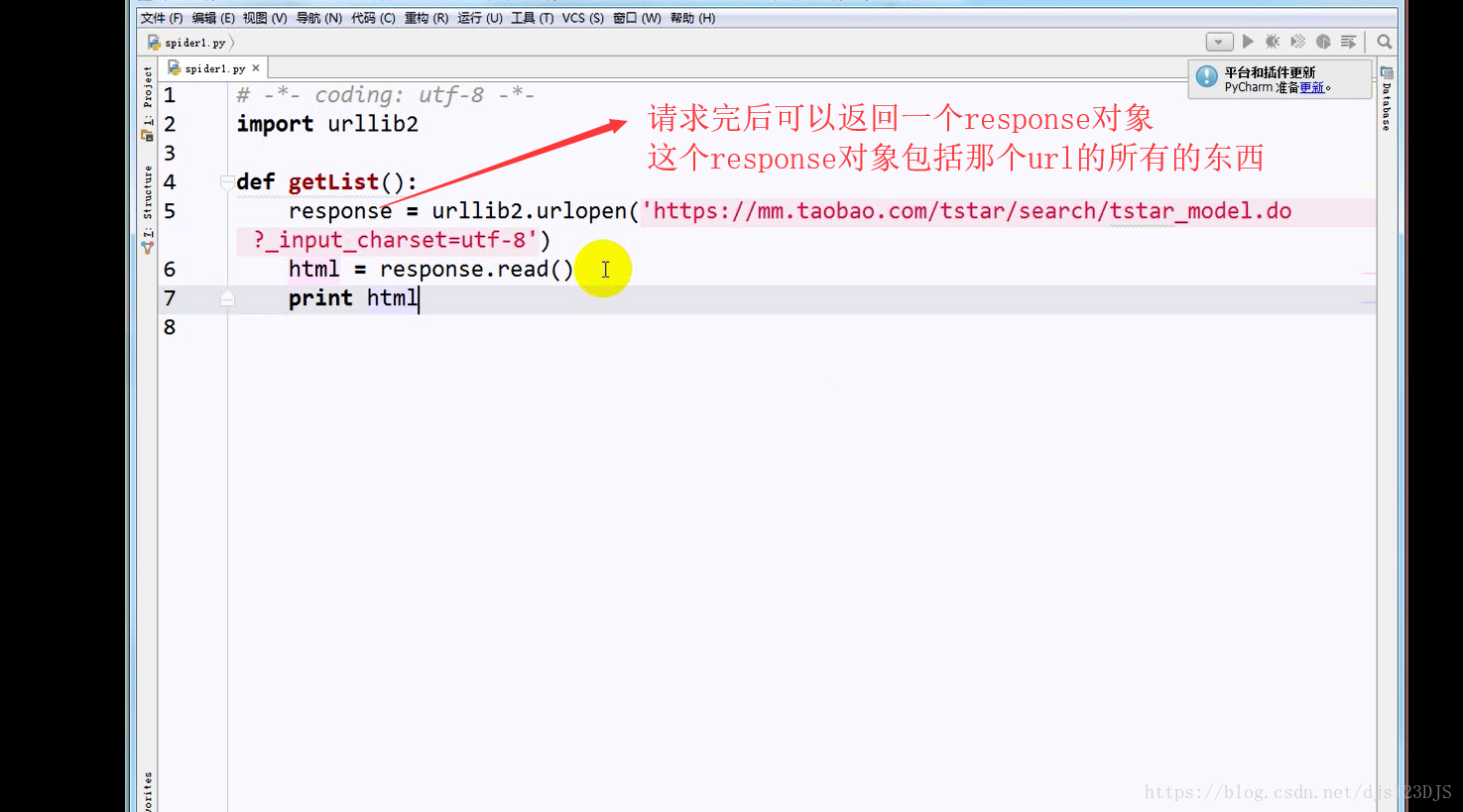
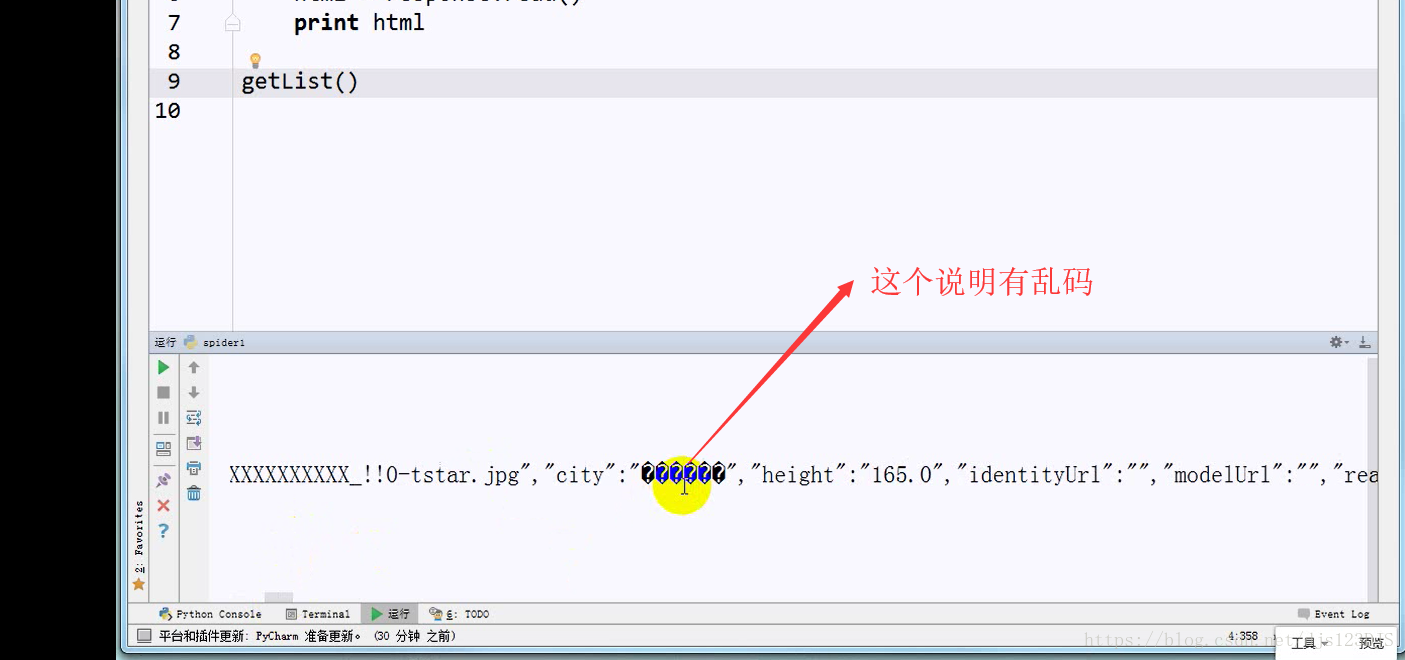
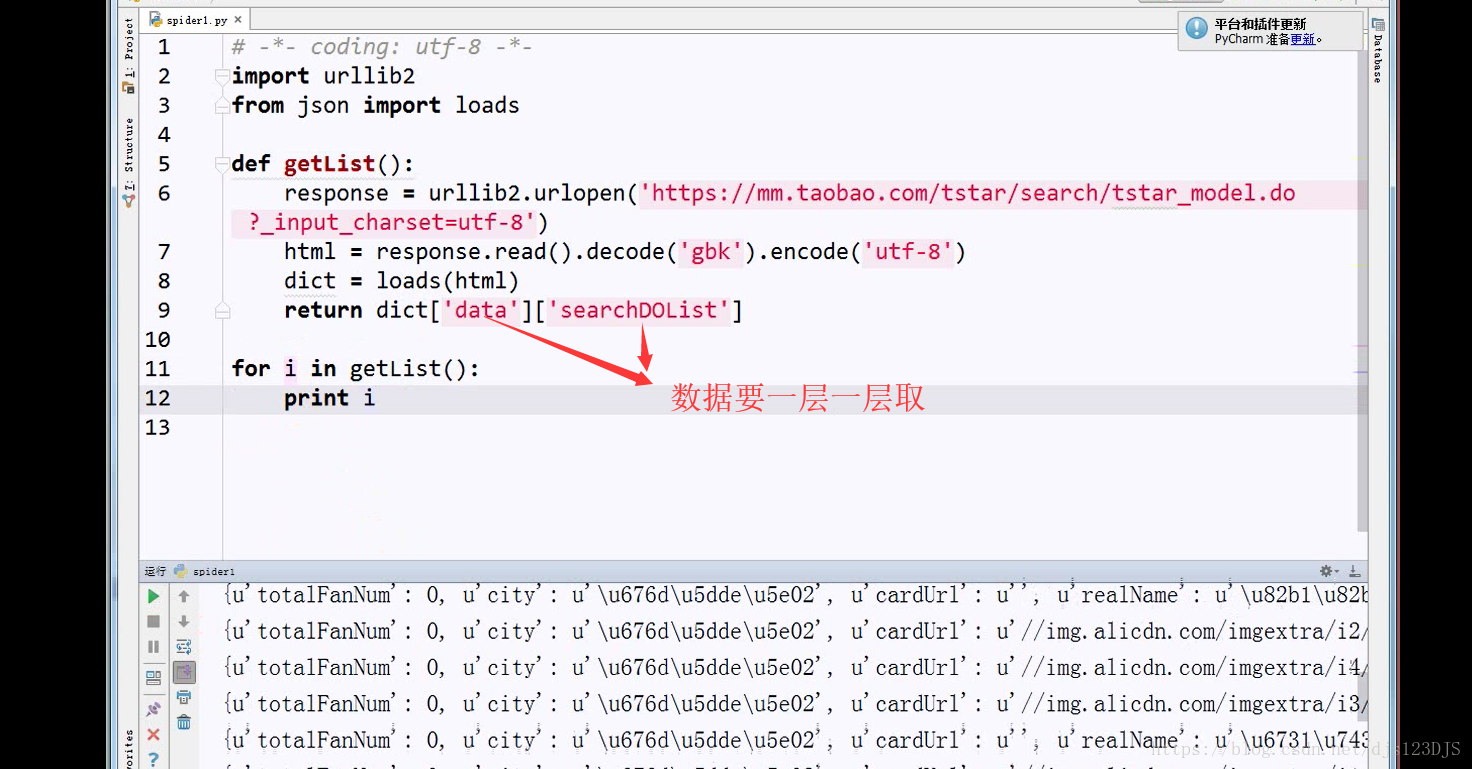
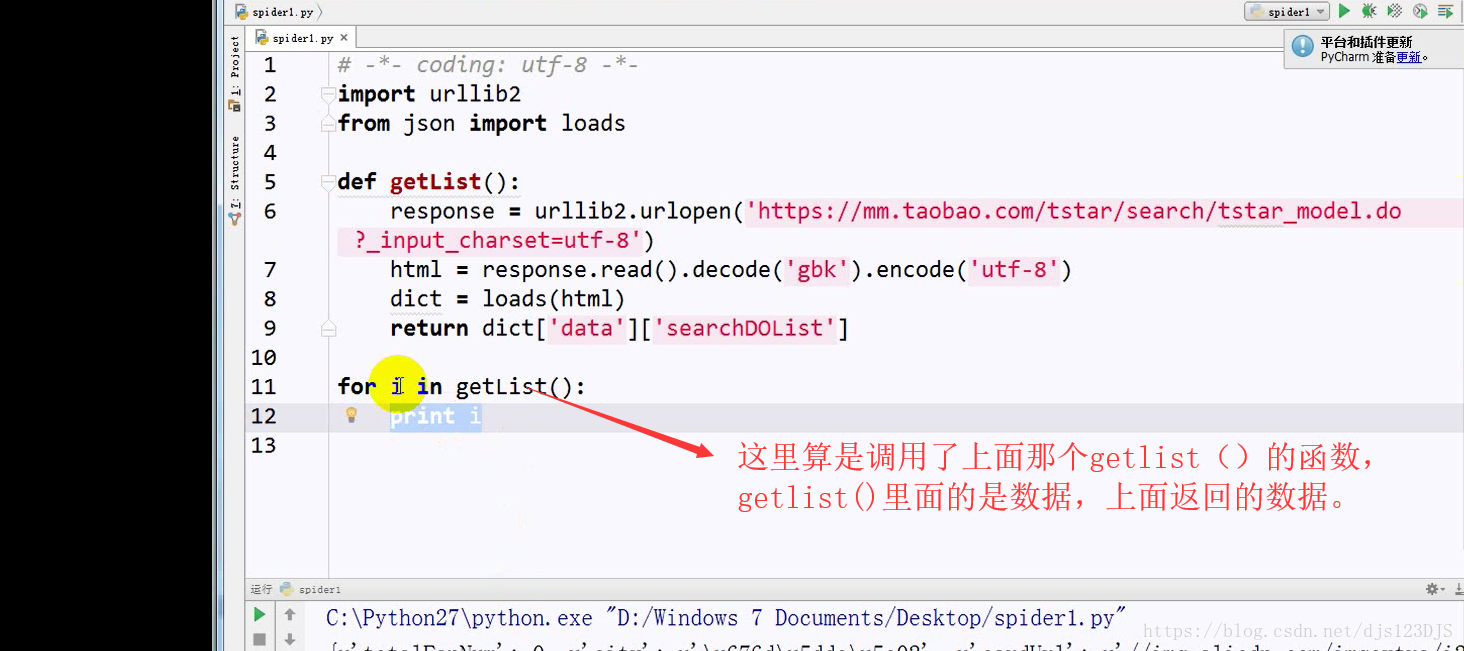
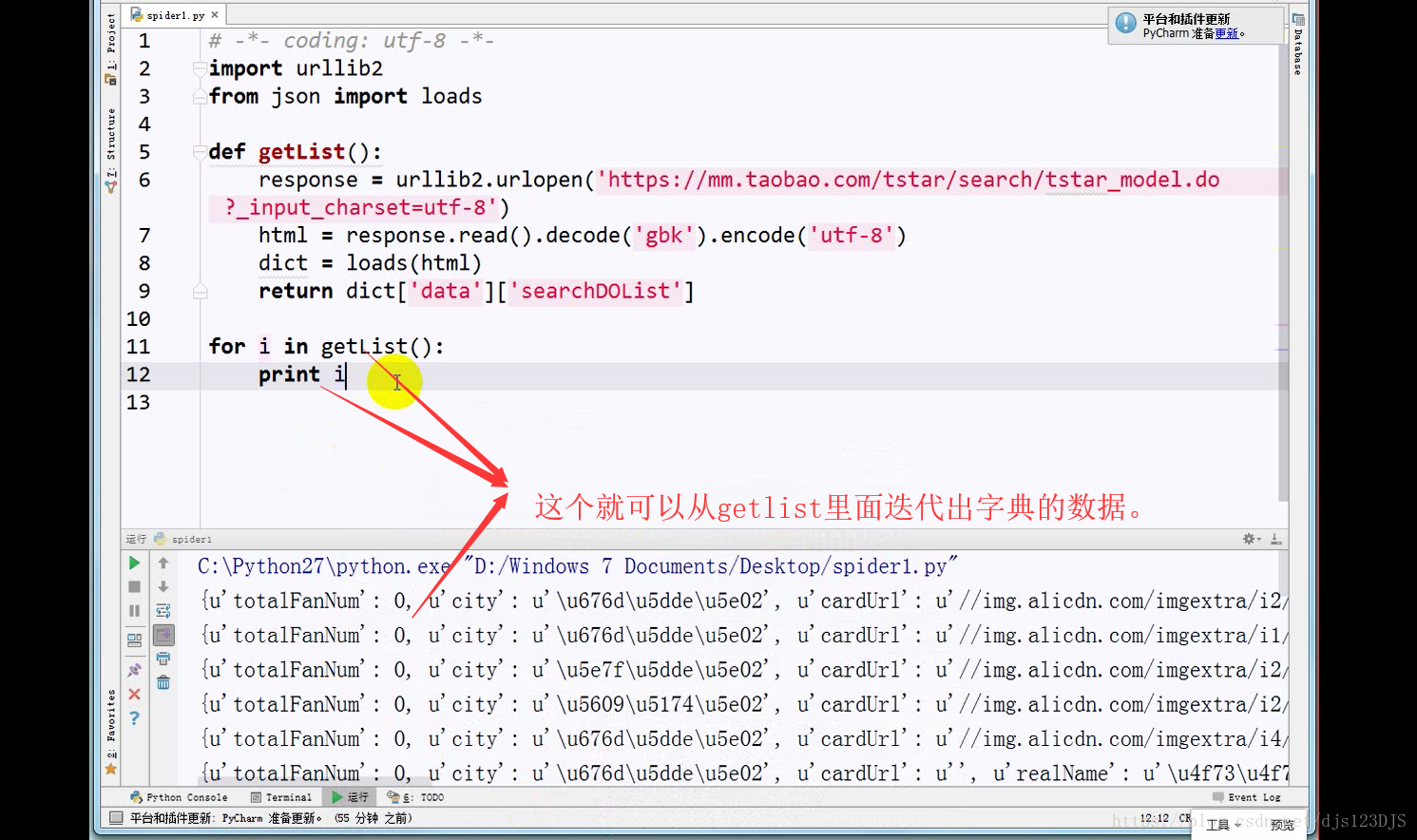
乱码的原因是实际的编码和显示的编码(这个指的是编译器中显示的编码)不一致。如用utf-8的编码来显示gbk的编码那就会乱码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









