




图片,网页,多媒体(网络资源),每一个网络资源都会有一个独一无二的url
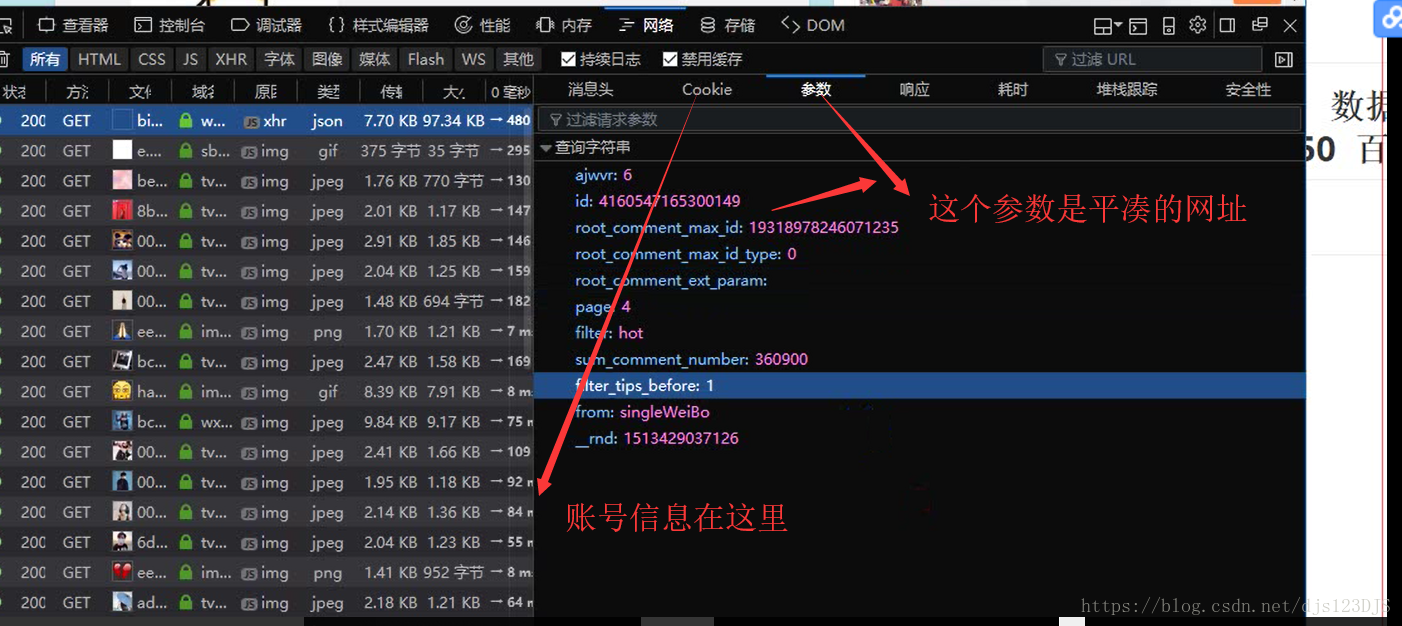
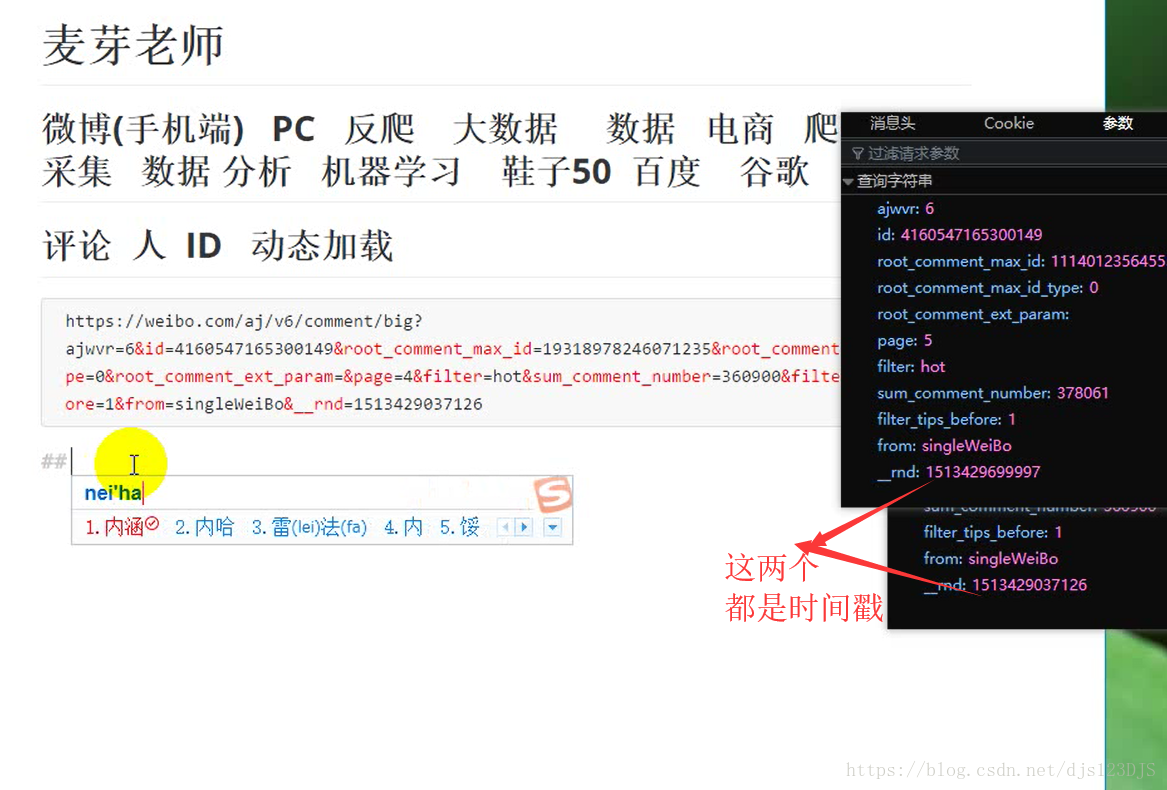
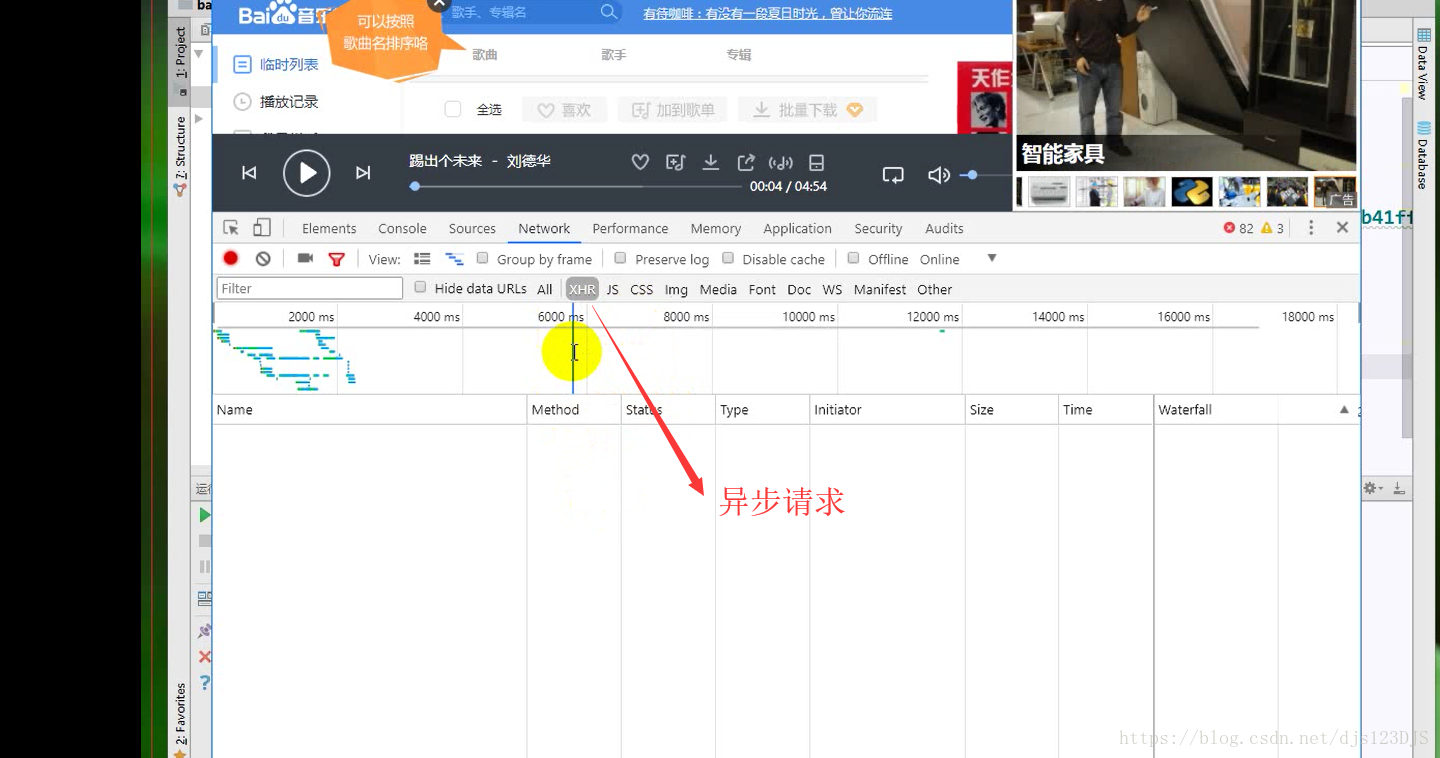
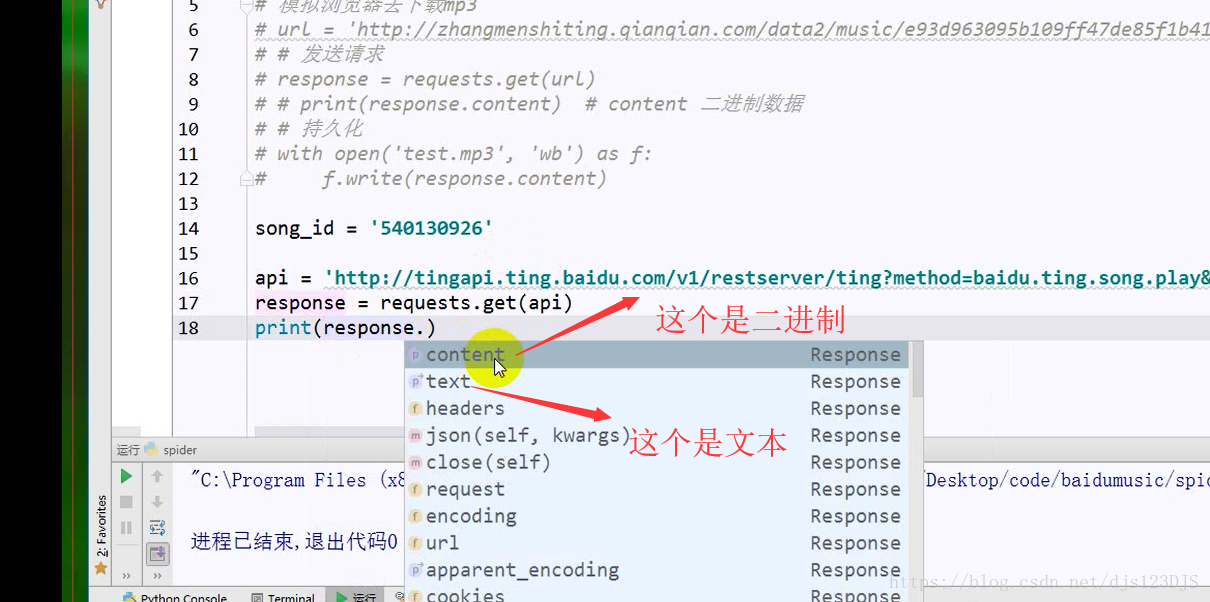
http请求 去对应的url请求数据,有get请求和post请求。
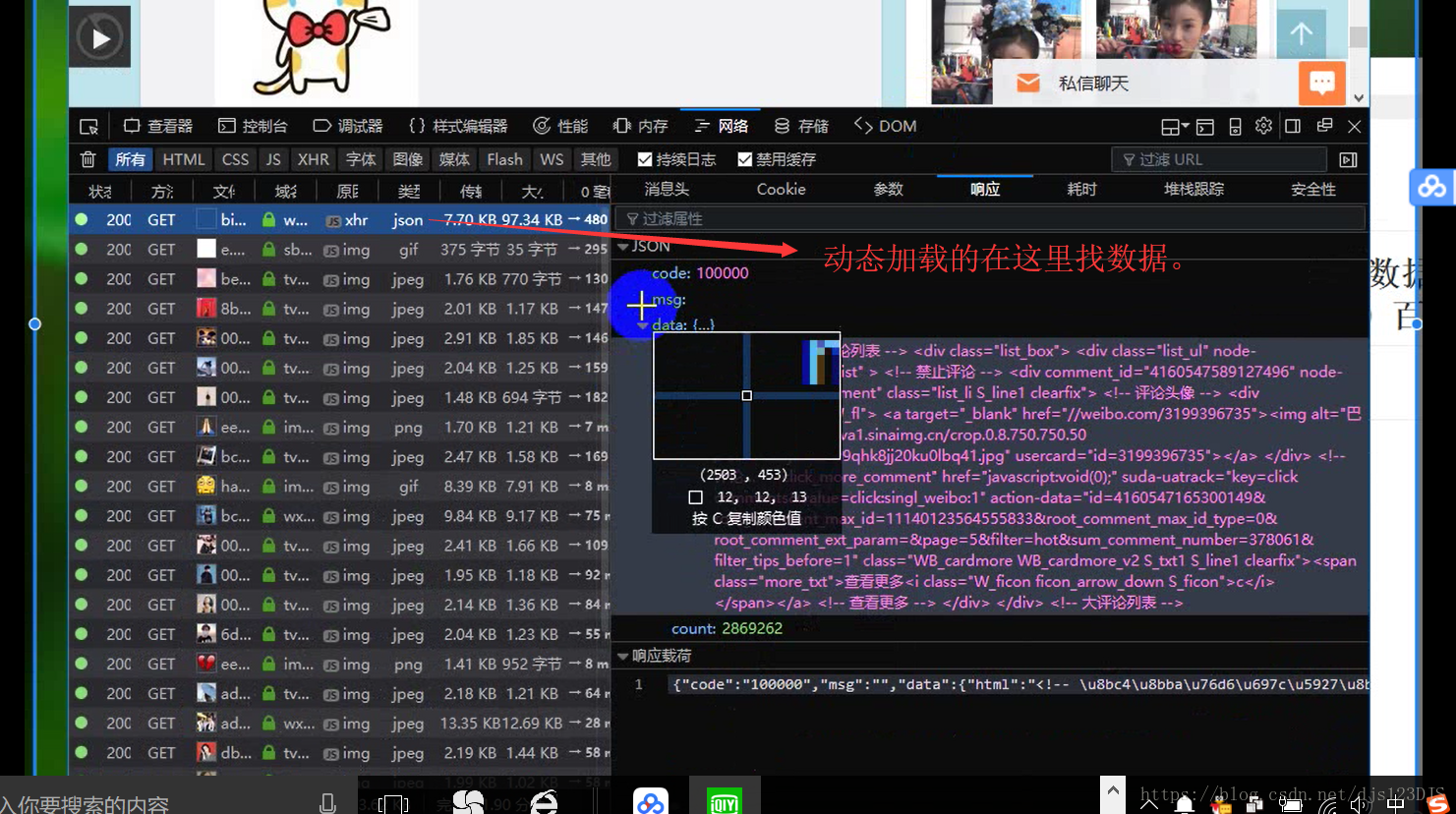
网页有静态加载和动态加载的,静态加载的可以在网页的源代码中看到网页中的信息,动态加载的就不可以。
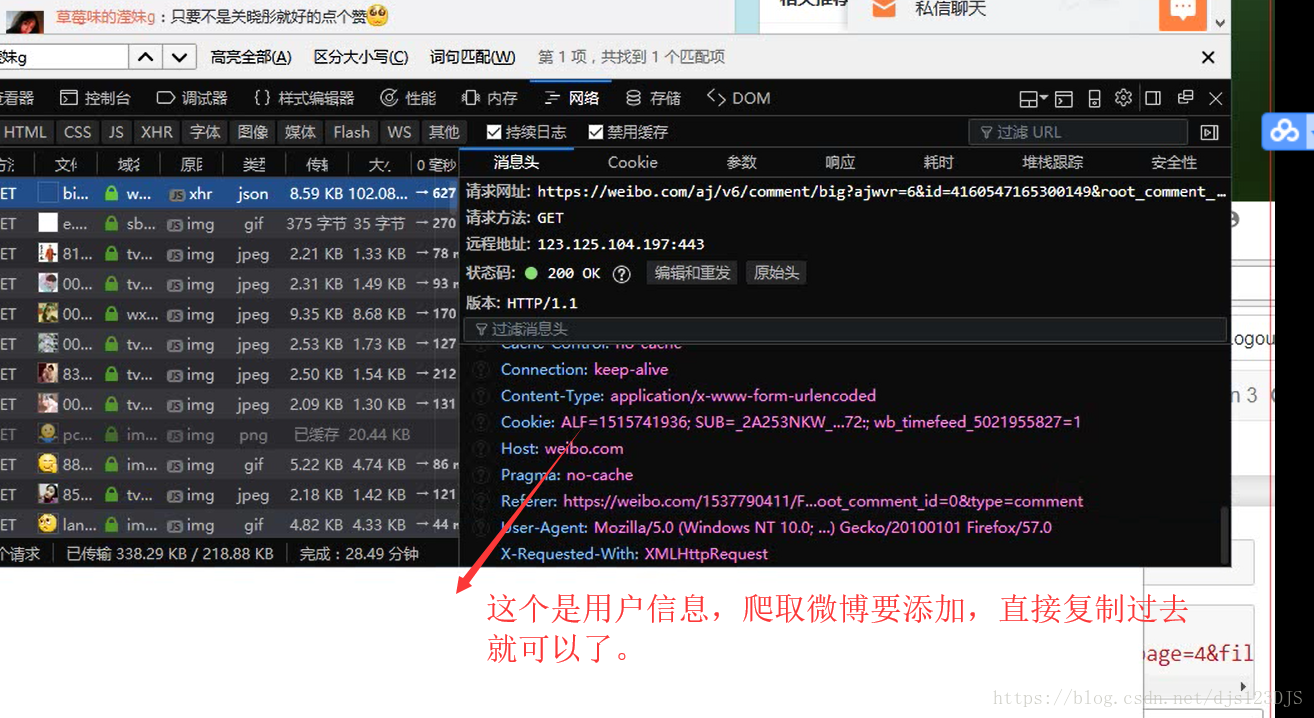
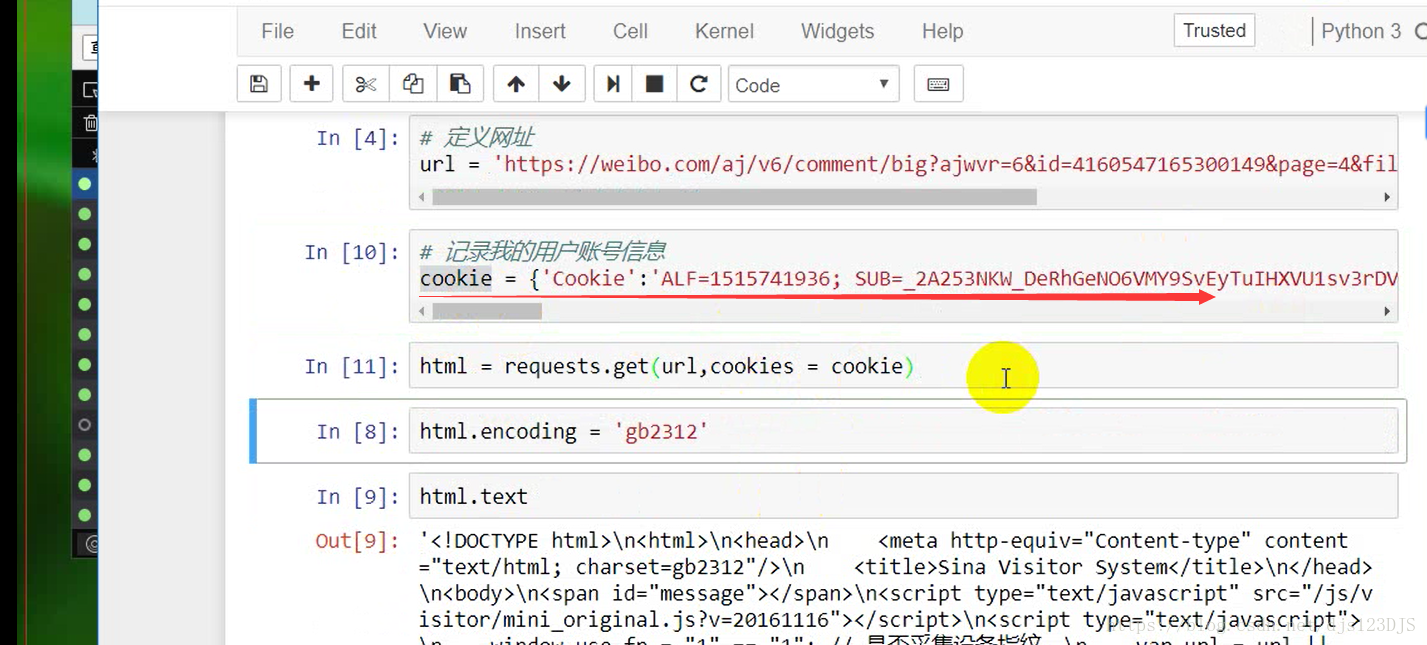
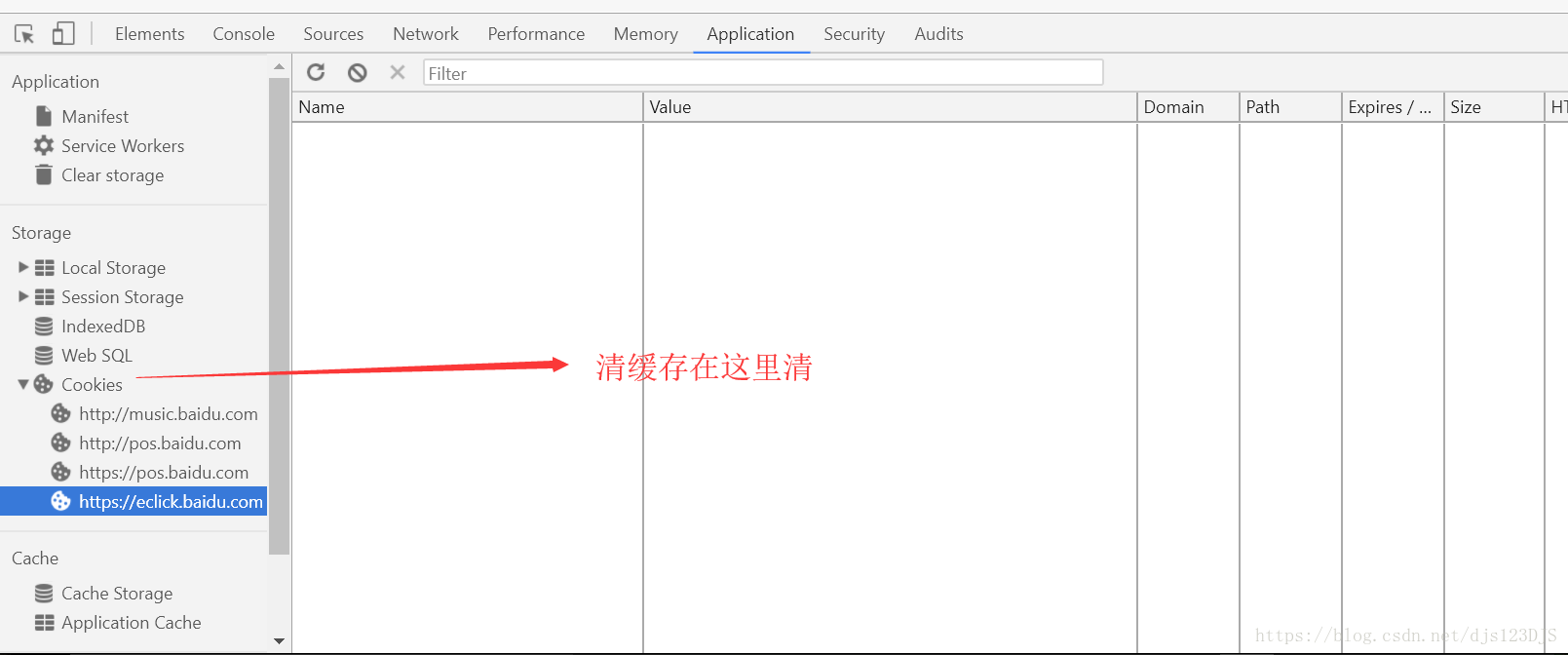
爬虫既可以cookie登录也可以模拟登录。json和字典类似
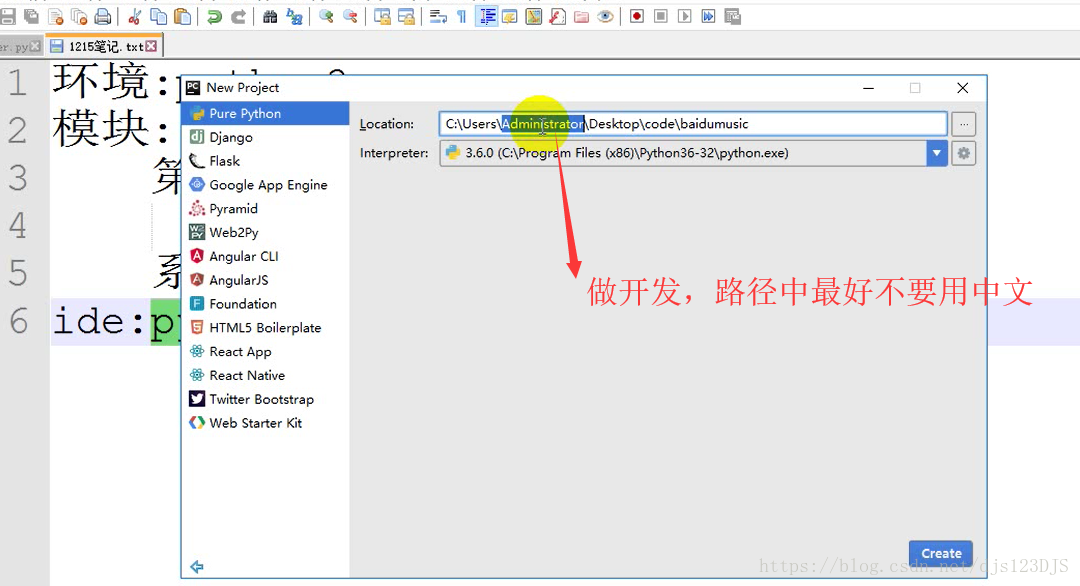
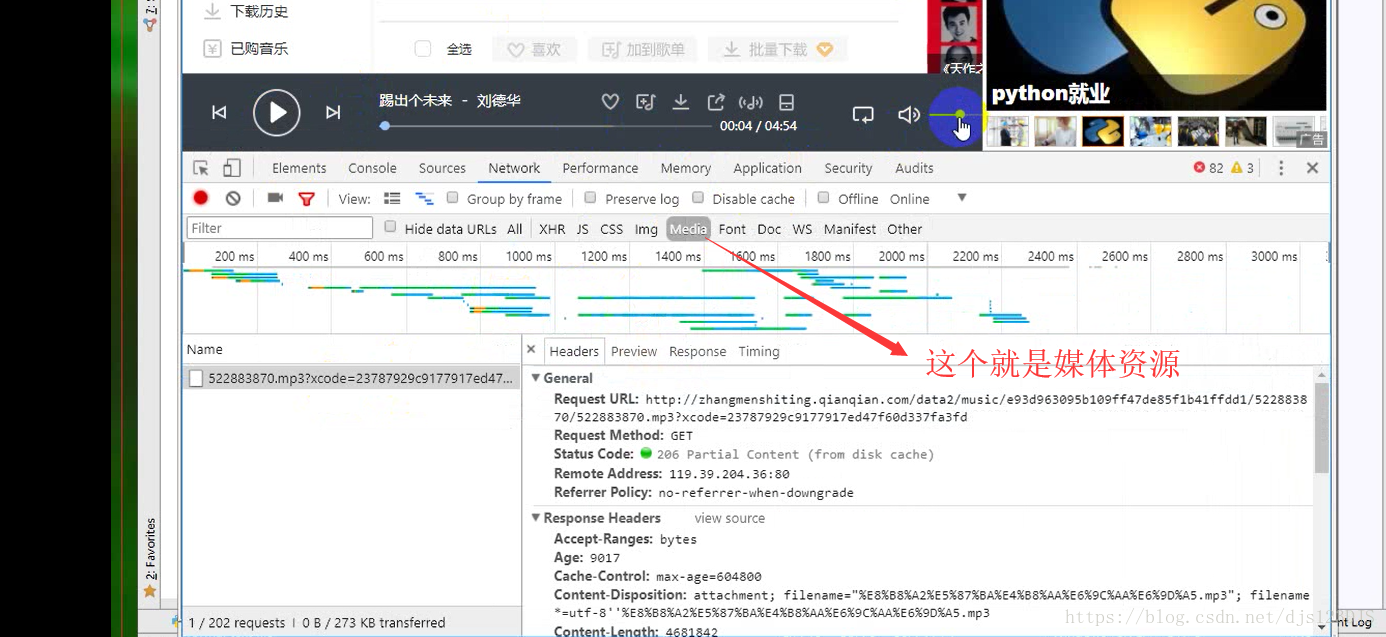
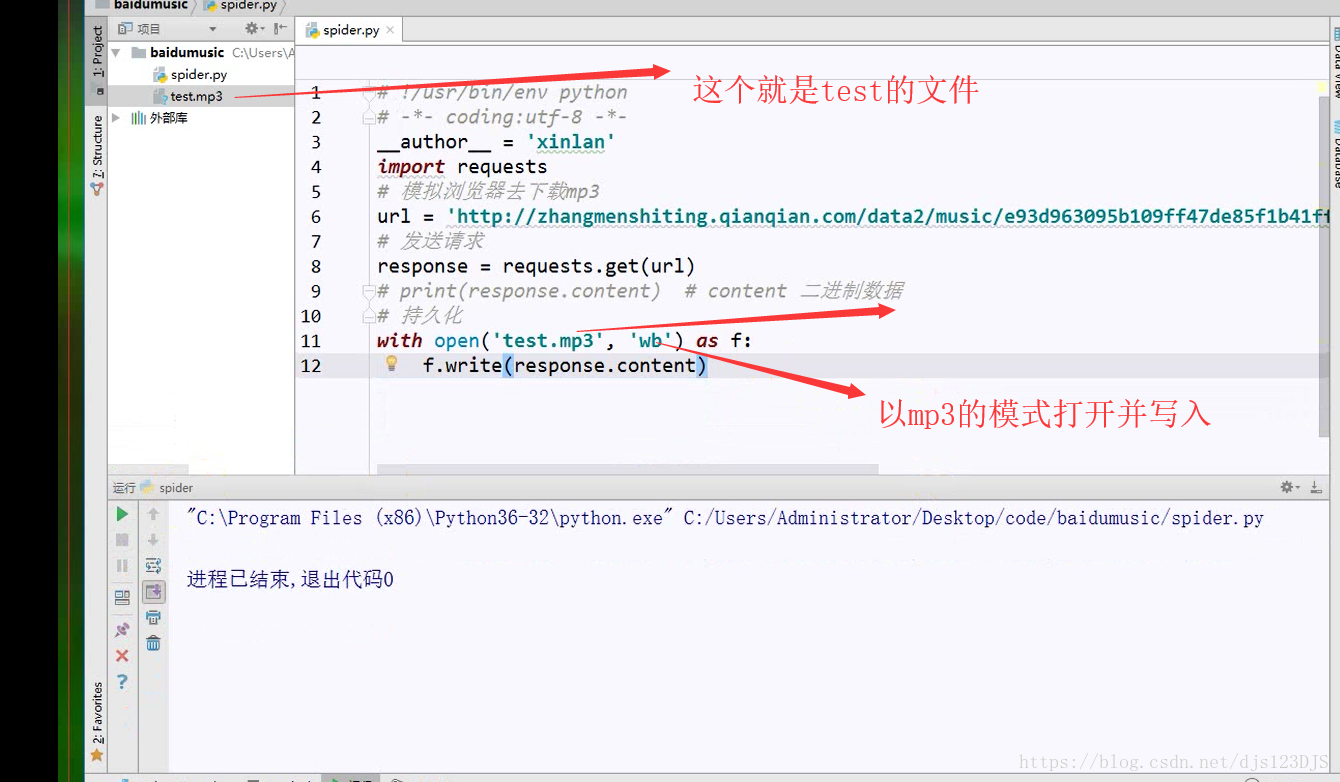
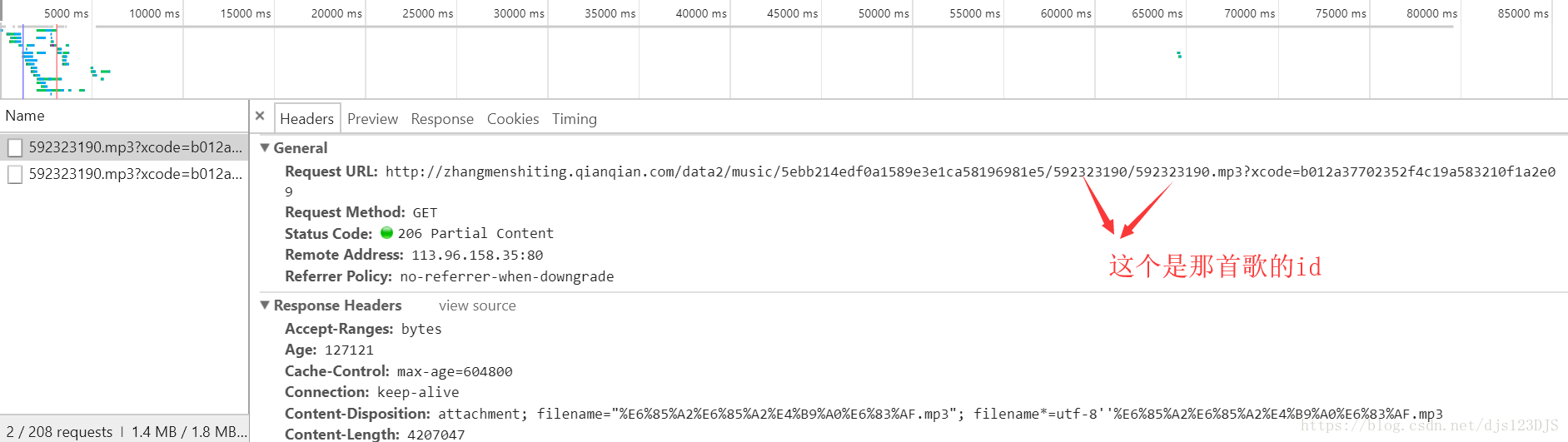
 本文介绍了网络资源的基本概念,包括URL的作用及HTTP请求方法GET和POST的区别。同时,文中对比了静态网页与动态网页的不同,并提及了爬虫技术的应用场景,如cookie登录和模拟登录等。此外,还简单解释了JSON格式与字典类型之间的相似之处。
本文介绍了网络资源的基本概念,包括URL的作用及HTTP请求方法GET和POST的区别。同时,文中对比了静态网页与动态网页的不同,并提及了爬虫技术的应用场景,如cookie登录和模拟登录等。此外,还简单解释了JSON格式与字典类型之间的相似之处。
图片,网页,多媒体(网络资源),每一个网络资源都会有一个独一无二的url
http请求 去对应的url请求数据,有get请求和post请求。
网页有静态加载和动态加载的,静态加载的可以在网页的源代码中看到网页中的信息,动态加载的就不可以。
爬虫既可以cookie登录也可以模拟登录。json和字典类似

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























