




 利用Python爬取校花网信息,包括姓名、票数和图片,并将这些信息进行保存,还展示了部分结果图。
利用Python爬取校花网信息,包括姓名、票数和图片,并将这些信息进行保存,还展示了部分结果图。
爬取校花网信息(姓名、票数、图片)并保存
http://www.ttpaihang.com/vote/rank.php?voteid=621
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
1、爬去网站的信息
2、筛选出有用数据
3、保存有用数据
4、有用的转化并保存
"""
import json
import parser
import requests
import lxml.html
def parse_url(url, headers):
# 解析url
response = requests.get(url,headers)
return response.content.decode("gb2312")
def get_wanghong_data(html_content):
# 筛选出有用数据
metree = lxml.html.etree
# 解析对象
parser = metree.HTML(html_content,metree.HTMLParser())
# 获取图片信息
div_list = parser.xpath("//td [@align='center']")
# div_list_name = parser.xpath("//a[@class='clink']")
# print(div_list)
# print(len(div_list))
data = []
for element in div_list:
item = {}
item["name"] = element.xpath("./table[@width='460']/tr/td[@class='main2_bt_td']/div[@align='left']/table[@width='100%']/tr/td[@width='75%']/span[@class='zthei']/a/text()")[0]
item["sum"] = element.xpath("./table[@width='460']/tr/td[@class='zthong']/text()")[0]
item["img"] = "http://www.ttpaihang.com"+element.xpath("./table[@width='460']/tr/td[@width='155']/div[@align='center']/a/img/@src")[0]
# print(item)
data.append(item)
# print(data)
return data
def save_file(datas):
# 保存文件
json_str = json.dumps(datas,ensure_ascii=False,indent=2)
with open("./file/wanghong.json","w",encoding="utf-8") as files:
files.write(json_str)
print("数据以保存成功!")
def main():
http_url = "http://www.ttpaihang.com/vote/rank.php?voteid=621"
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}
# 1、爬去网站的信息
html_data = parse_url(http_url,header)
# print(html_data)
# 2、筛选出有用数据
wanghong_data =get_wanghong_data(html_data)
# print(wanghong_data)
#保存有用数据
save_file(wanghong_data)
if __name__ == '__main__':
main()
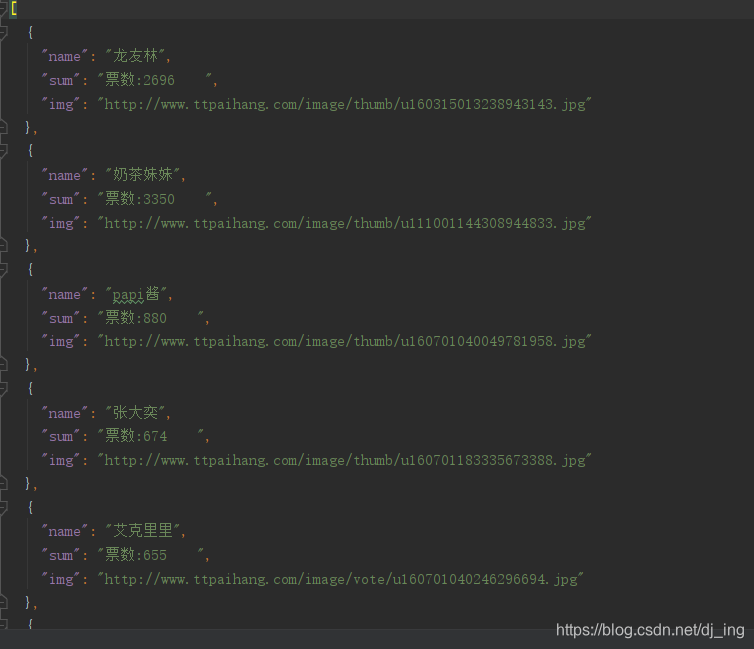
部分结果图

















 3216
3216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









