



1.云服务器部署
首先是租用一个云服务器,我是在autodl中租用的服务器,租用的是16G的显存,虽然在训练的过程中显存只需要6.7G,但是呢在推理的过程中12G的显存运行不稳定我就直接换成16G的了。我在ChatGLM-6B/ptuning at main · THUDM/ChatGLM-6B · GitHub上下载了模型,但是这个里面并没有包含模型,在这个github中的代码里面的模型是从huggingface中加载的,建议是从huggingface中下载,因为模型的checkpoint挺大的,下载了几次也都失败了。https://huggingface.co/THUDM/chatglm-6b这个是网址,点一下files and versions之后就可以下载了。 没错,这里的所有都要下载,下载之后放在一个文件里面。到这一步云部署基本是完成了。之后还要修改一下模型的路径。有两种启动方式(启动原模型)。
没错,这里的所有都要下载,下载之后放在一个文件里面。到这一步云部署基本是完成了。之后还要修改一下模型的路径。有两种启动方式(启动原模型)。
1.使用web_demo.py
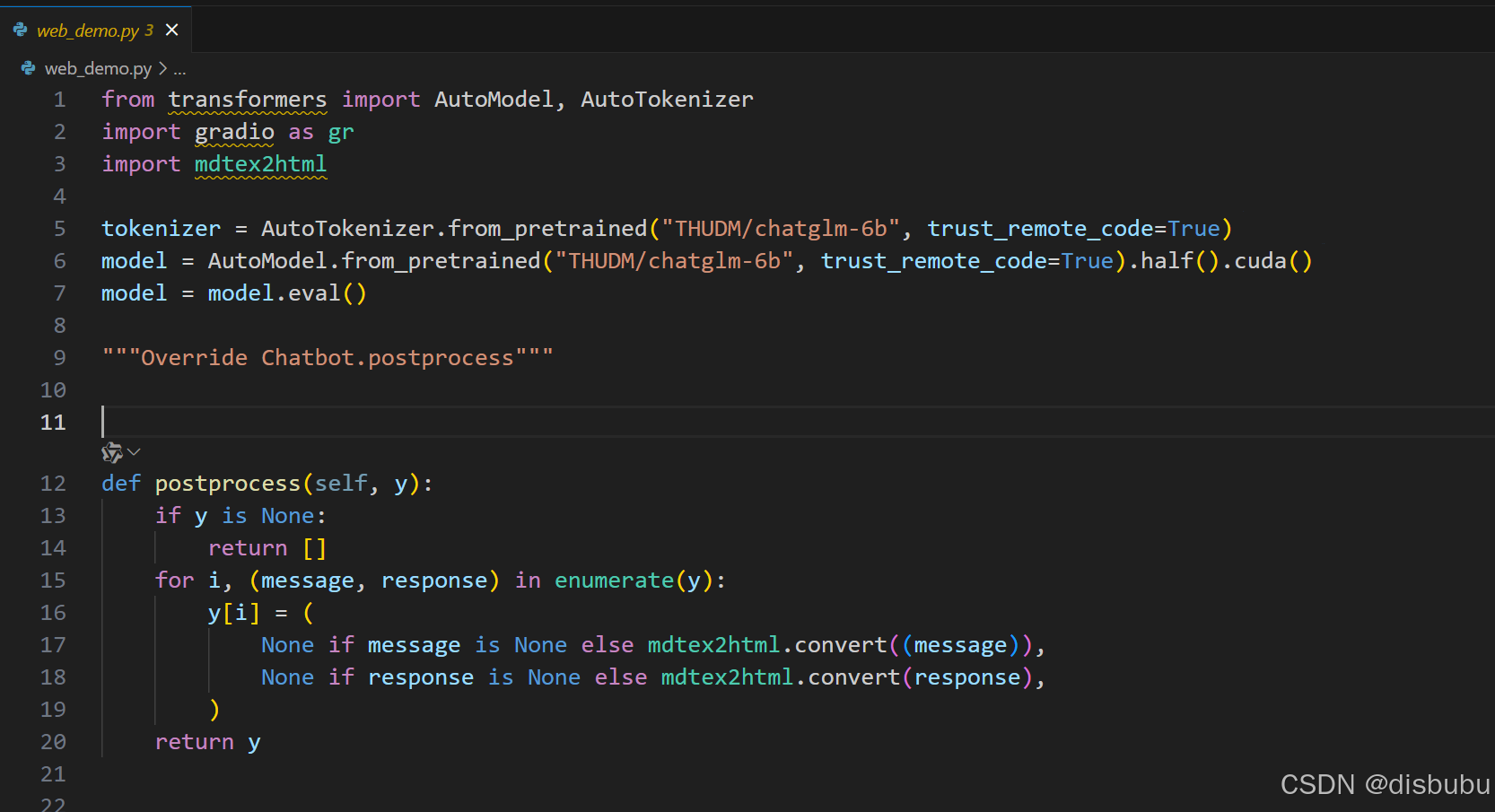
但是需要修改模型路径,也就是
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()两行代码中的“THUDM/chatglm-6b”这两段代码需要改成自己的模型路径。
2.cli_demo.py启动

同理修改一下模型的路径这样就可以运行了。
2.模型的微调
P-Tuning v2
运行以下指令进行训练:
bash train.sh
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
如果你想要本地加载模型,可以将 train.sh 中的 THUDM/chatglm-6b 改为你本地的模型路径。
Finetune
如果需要进行全参数的 Finetune,需要安装 Deepspeed,然后运行以下指令:
bash ds_train_finetune.sh
想要训练自己的数据的话,只需要将train.sh中的
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
换成自己的数据集路径就可以了,注意官方给的例子中的数据集的格式有点问题,但是他们的可以训练,我之前按照他们的方式来就报错,后来是换成了标准的json格式就可以了(也可能是我的数据集有问题,但是换成了标准的json格式就不会报错了),要是训练中断了,可以从某个checkpoint点开始训练,只需要在train.sh脚本中加入--resume_from_checkpoint output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-1000 \就可以了,这个的路径也是我自己的。下面是我自己微调的,不过因为数据集太少了,并且只用到了微调,所以效果很差。


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









