







 本文介绍了Python爬虫中XPath的使用,包括XPath的基本概念、安装、节点类型和路径表达式。通过实例展示了如何定位元素、属性和文本节点,强调XPath在HTML解析中的重要性。
本文介绍了Python爬虫中XPath的使用,包括XPath的基本概念、安装、节点类型和路径表达式。通过实例展示了如何定位元素、属性和文本节点,强调XPath在HTML解析中的重要性。
小伙伴、大伙伴们,大家好~今天要给大家介绍的是Python 爬虫必杀技:XPath。
1. 简介
一提到网络爬虫,就不得不提到Xpath Helper,我们常常用它来对所要提取的文本内容进行定位。除了这一利器外,了解Xpath定位的原理及其基本用法可以大幅提高我们的爬虫技巧。
XPath即XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。现在问题来了,爬虫是从HTML网页上抓取信息,你给我介绍XML干嘛?实际上,XML是一种与HTML很相似的可扩展标记语言,均为具备结构和层次的文档,我们所关注的文本内容都由各种标签“包围”着。不同的是,XML文档的结构更简洁,比HTML对初次学习爬虫的新手更友好。因此,我们学习Python爬虫,可以从使用XPath对XML进行定位开始~
2. 安装
在Windows环境下,同时按下Home+R,输入cmd:
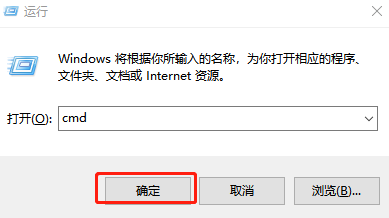
确认后进入命令提示符界面,键入如下命令后回车:
pip install lxml若出现下图所示界面,则表示安装成功:
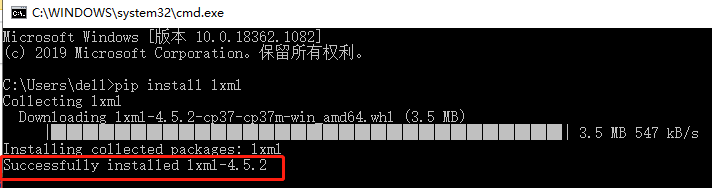
3. XPath的节点
XPath的主要节点有4种,分别是:文档节点,元素节点,属性节点和文本节点。比如下面这个XML文档:
<bookstore> <book category="Fantasy Novels"> <title>Harry Potter</title> <author>J K. Rowling</author>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









