




目录
multiprocessing模块深度应用
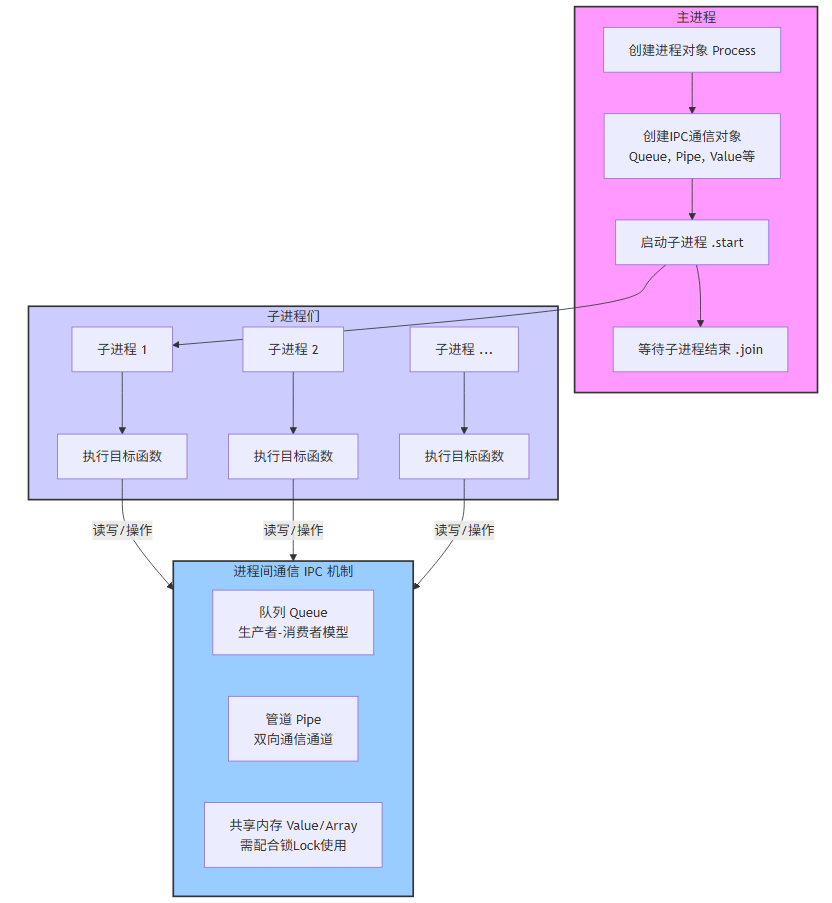
Process类的高级用法
Python的`multiprocessing`模块提供了强大的多进程编程能力。Process类是其核心组件,支持多种创建和管理进程的方式。
import multiprocessing
import os
import time
def worker_function(name, numbers):
pid = os.getpid()
result = sum(numbers)
print(f"Worker {name} (PID: {pid}) 计算结果: {result}")
class WorkerProcess(multiprocessing.Process):
"""自定义进程类"""
def __init__(self, task_id, data):
super().__init__()
self.task_id = task_id
self.data = data
def run(self):
"""重写run方法定义进程要执行的任务"""
print(f"进程 {os.getpid()} 开始执行任务 {self.task_id}")
# 模拟耗时计算
result = sum(self.data) ** 2
time.sleep(2)
print(f"进程 {os.getpid()} 完成任务 {self.task_id},结果: {result}")
return result
def demonstrate_process_creation():
"""演示多种进程创建方式"""
# 方式1:直接使用Process类
processes = []
for i in range(3):
p = multiprocessing.Process(
target=worker_function,
args=(f"Worker-{i}", list(range(i*10, (i+1)*10)))
)
processes.append(p)
p.start()
# 等待所有进程完成
for p in processes:
p.join()
print("=" * 50)
# 方式2:使用自定义进程类
custom_processes = []
for i in range(3):
data = list(range(i*5, (i+1)*5))
p = WorkerProcess(f"Task-{i}", data)
custom_processes.append(p)
p.start()
for p in custom_processes:
p.join()
if __name__ == "__main__":
demonstrate_process_creation()
两种多进程创建方式:
直接使用multiprocessing.Process类,通过传入目标函数和参数启动多个进程,完成简单的计算任务。
继承multiprocessing.Process类自定义进程类,重写run方法,实现更复杂的任务逻辑和状态管理。
进程池(Pool)管理
进程池提供了更高级的进程管理方式,自动处理进程的创建、复用和销毁。
import multiprocessing
import time
import math
def cpu_intensive_task(n):
"""CPU密集型任务:计算质数"""
if n < 2:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return n
def io_intensive_task(filename):
"""IO密集型任务:文件处理"""
time.sleep(1) # 模拟IO等待
return f"处理文件: {filename}"
class AdvancedPoolManager:
"""高级进程池管理器"""
def __init__(self, max_workers=None):
self.max_workers = max_workers or multiprocessing.cpu_count()
def process_cpu_tasks(self, numbers):
"""处理CPU密集型任务"""
print(f"使用 {self.max_workers} 个进程处理CPU密集型任务")
with multiprocessing.Pool(processes=self.max_workers) as pool:
# 使用map进行批量处理
start_time = time.time()
results = pool.map(cpu_intensive_task, numbers)
end_time = time.time()
primes = [n for n, is_prime in zip(numbers, results) if is_prime]
print(f"发现 {len(primes)} 个质数,耗时: {end_time - start_time:.2f}s")
return primes
def process_io_tasks(self, filenames):
"""处理IO密集型任务"""
print(f"使用 {self.max_workers} 个进程处理IO密集型任务")
with multiprocessing.Pool(processes=self.max_workers) as pool:
# 使用map_async进行异步处理
start_time = time.time()
async_result = pool.map_async(io_intensive_task, filenames)
# 可以在等待期间做其他事情
print("任务提交完成,等待结果...")
results = async_result.get(timeout=10)
end_time = time.time()
print(f"处理完成,耗时: {end_time - start_time:.2f}s")
return results
def process_with_callback(self, data):
"""使用回调函数处理结果"""
def success_callback(result):
print(f"任务成功完成,结果: {result}")
def error_callback(error):
print(f"任务执行失败: {error}")
with multiprocessing.Pool(processes=self.max_workers) as pool:
for item in data:
pool.apply_async(
cpu_intensive_task,
args=(item,),
callback=success_callback,
error_callback=error_callback
)
pool.close()
pool.join()
# 使用示例
if __name__ == "__main__":
manager = AdvancedPoolManager()
# 测试CPU密集型任务
test_numbers = list(range(1000, 1100))
primes = manager.process_cpu_tasks(test_numbers)
# 测试IO密集型任务
test_files = [f"file_{i}.txt" for i in range(10)]
results = manager.process_io_tasks(test_files)
# 测试回调机制
manager.process_with_callback([97, 98, 99, 100, 101])三种核心功能:
批量处理CPU密集型任务:利用pool.map同步执行计算质数的任务,充分利用多核CPU并行计算能力。
异步处理IO密集型任务:通过pool.map_async异步提交文件处理任务,模拟IO等待,提升资源利用率。
基于回调函数的任务处理:使用pool.apply_async结合回调函数,实现任务完成后的即时响应和错误处理。
进程间通信的多种方式
Queue队列通信
Queue是最常用的进程间通信方式,提供了线程安全的FIFO队列。
import multiprocessing
import time
import random
def producer(queue, producer_id, num_items):
"""生产者进程"""
for i in range(num_items):
item = f"Item-{producer_id}-{i}"
queue.put(item)
print(f"生产者 {producer_id} 生产: {item}")
time.sleep(random.uniform(0.1, 0.5))
# 发送结束信号
queue.put(None)
print(f"生产者 {producer_id} 完成生产")
def consumer(queue, consumer_id):
"""消费者进程"""
consumed_items = []
while True:
try:
item = queue.get(timeout=5)
if item is None:
print(f"消费者 {consumer_id} 接收到结束信号")
break
consumed_items.append(item)
print(f"消费者 {consumer_id} 消费: {item}")
time.sleep(random.uniform(0.2, 0.8))
except Exception as e:
print(f"消费者 {consumer_id} 超时退出: {e}")
break
print(f"消费者 {consumer_id} 总共消费了 {len(consumed_items)} 个物品")
return consumed_items
class QueueCommunicationDemo:
"""队列通信演示"""
def __init__(self):
self.task_queue = multiprocessing.Queue()
self.result_queue = multiprocessing.Queue()
def worker_process(self, worker_id):
"""工作进程:从任务队列获取任务,将结果放入结果队列"""
processed_count = 0
while True:
try:
task = self.task_queue.get(timeout=2)
if task is None: # 结束信号
break
# 处理任务
result = task ** 2
self.result_queue.put((worker_id, task, result))
processed_count += 1
print(f"工作进程 {worker_id} 处理任务 {task} -> {result}")
time.sleep(0.1)
except Exception:
print(f"工作进程 {worker_id} 超时退出")
break
print(f"工作进程 {worker_id} 总共处理了 {processed_count} 个任务")
def run_demo(self):
"""运行演示"""
# 添加任务到队列
tasks = list(range(1, 21))
for task in tasks:
self.task_queue.put(task)
# 启动多个工作进程
num_workers = 3
workers = []
for i in range(num_workers):
p = multiprocessing.Process(target=self.worker_process, args=(i,))
workers.append(p)
p.start()
# 收集结果
results = []
for _ in range(len(tasks)):
try:
result = self.result_queue.get(timeout=10)
results.append(result)
except Exception as e:
print(f"获取结果超时: {e}")
break
# 发送结束信号
for _ in range(num_workers):
self.task_queue.put(None)
# 等待所有工作进程结束
for worker in workers:
worker.join()
# 显示结果
print(f"\n收集到 {len(results)} 个结果:")
for worker_id, task, result in results:
print(f"工作进程 {worker_id}: {task}^2 = {result}")
# 运行队列通信演示
if __name__ == "__main__":
# 基础生产者-消费者模式
queue = multiprocessing.Queue()
# 启动生产者
producer_process = multiprocessing.Process(
target=producer, args=(queue, 1, 5)
)
# 启动消费者
consumer_process = multiprocessing.Process(
target=consumer, args=(queue, 1)
)
producer_process.start()
consumer_process.start()
producer_process.join()
consumer_process.join()
print("=" * 50)
# 高级队列通信演示
demo = QueueCommunicationDemo()
demo.run_demo()生产者-消费者模式
生产者不断生成任务(字符串标识的物品),放入共享队列。
消费者从队列取任务,模拟消费过程,遇到None结束信号时退出。
通过队列实现安全的进程间通信,避免竞争条件。
工作进程池模式
主进程将一批整数任务放入任务队列。
多个工作进程并发从任务队列取任务,计算平方后将结果放入结果队列。
主进程从结果队列收集处理结果,最后发送结束信号通知工作进程退出。
Pipe管道通信
Pipe提供了双向通信管道,适合两个进程之间的直接通信。
import multiprocessing
import time
def server_process(conn):
"""服务器进程:处理客户端请求"""
print("服务器进程启动")
request_count = 0
while True:
try:
# 接收请求
message = conn.recv()
request_count += 1
if message.get('type') == 'shutdown':
print("服务器接收到关闭信号")
break
print(f"服务器收到请求 #{request_count}: {message}")
# 处理请求
if message.get('type') == 'calculate':
data = message.get('data', [])
result = sum(data)
response = {
'request_id': message.get('id'),
'result': result,
'status': 'success'
}
else:
response = {
'request_id': message.get('id'),
'error': 'Unknown request type',
'status': 'error'
}
# 发送响应
conn.send(response)
time.sleep(0.1) # 模拟处理时间
except Exception as e:
print(f"服务器处理请求时出错: {e}")
break
print(f"服务器进程结束,总共处理了 {request_count} 个请求")
conn.close()
def client_process(conn):
print("客户端进程启动")
requests = [
{'id': 1, 'type': 'calculate', 'data': [1, 2, 3, 4, 5]},
{'id': 2, 'type': 'calculate', 'data': [10, 20, 30]},
{'id': 3, 'type': 'unknown', 'data': []},
{'id': 4, 'type': 'calculate', 'data': list(range(100))},
]
responses = []
for request in requests:
try:
# 发送请求
print(f"客户端发送请求: {request['id']}")
conn.send(request)
# 接收响应
response = conn.recv()
responses.append(response)
print(f"客户端收到响应: {response}")
except Exception as e:
print(f"客户端通信出错: {e}")
break
# 发送关闭信号
conn.send({'type': 'shutdown'})
print(f"客户端完成,收到 {len(responses)} 个响应")
conn.close()
return responses
class PipeDataProcessor:
"""使用管道的数据处理器"""
def __init__(self):
self.parent_conn, self.child_conn = multiprocessing.Pipe()
def data_processor(self, conn):
"""数据处理进程"""
print("数据处理器启动")
while True:
try:
data = conn.recv()
if data is None:
break
# 不同类型的数据处理
if isinstance(data, list):
result = {
'type': 'list_analysis',
'length': len(data),
'sum': sum(data) if all(isinstance(x, (int, float)) for x in data) else None,
'min': min(data) if data and all(isinstance(x, (int, float)) for x in data) else None,
'max': max(data) if data and all(isinstance(x, (int, float)) for x in data) else None,
}
elif isinstance(data, dict):
result = {
'type': 'dict_analysis',
'keys': list(data.keys()),
'values_count': len(data.values()),
}
else:
result = {
'type': 'unknown',
'data_type': str(type(data)),
'str_repr': str(data)
}
conn.send(result)
except Exception as e:
print(f"数据处理器出错: {e}")
break
print("数据处理器结束")
conn.close()
def process_data_batch(self, data_batch):
"""批量处理数据"""
# 启动数据处理进程
processor = multiprocessing.Process(
target=self.data_processor,
args=(self.child_conn,)
)
processor.start()
results = []
# 发送数据并接收结果
for data in data_batch:
self.parent_conn.send(data)
result = self.parent_conn.recv()
results.append(result)
print(f"处理结果: {result}")
# 发送结束信号
self.parent_conn.send(None)
# 等待处理进程结束
processor.join()
return results
# 管道通信演示
if __name__ == "__main__":
# 基础管道通信
parent_conn, child_conn = multiprocessing.Pipe()
server = multiprocessing.Process(target=server_process, args=(child_conn,))
client = multiprocessing.Process(target=client_process, args=(parent_conn,))
server.start()
client.start()
server.join()
client.join()
print("=" * 50)
# 数据处理管道演示
processor = PipeDataProcessor()
test_data = [
[1, 2, 3, 4, 5],
{'name': 'test', 'value': 42},
"hello world",
list(range(1000)),
{'a': 1, 'b': 2, 'c': 3}
]
results = processor.process_data_batch(test_data)
print(f"批量处理完成,共处理 {len(results)} 项数据")客户端-服务器通信
服务器进程不断监听管道,接收客户端请求。根据请求类型(如calculate),服务器执行相应操作(求和),并将结果通过管道返回。
客户端发送多个请求,接收对应响应,最后发送关闭信号通知服务器退出。该模式模拟了典型的请求-响应交互,适合实现简单的RPC或任务调度。
数据处理器模式
创建一个独立的数据处理进程,监听管道接收数据。根据数据类型(列表、字典、其他),执行不同的分析逻辑。
处理结果通过管道返回给主进程,实现双向通信。主进程批量发送数据,收集处理结果,最后发送结束信号关闭处理进程。该模式适合复杂数据流处理和异步任务管理。
Manager共享对象
Manager提供了在多进程间共享Python对象的机制。
import multiprocessing
def worker(shared_dict, shared_list, worker_id):
# 向共享字典写入数据
shared_dict[f'worker_{worker_id}'] = f'data_from_worker_{worker_id}'
# 向共享列表追加数据
shared_list.append(worker_id)
print(f"Worker {worker_id} 写入数据")
if __name__ == "__main__":
with multiprocessing.Manager() as manager:
# 创建共享字典和列表
shared_dict = manager.dict()
shared_list = manager.list()
processes = []
for i in range(4):
p = multiprocessing.Process(target=worker, args=(shared_dict, shared_list, i))
processes.append(p)
p.start()
for p in processes:
p.join()
print("共享字典内容:", dict(shared_dict))
print("共享列表内容:", list(shared_list))manager.dict() 和 manager.list() 创建的对象可以被多个进程安全共享和修改。各个进程对共享对象的修改对其他进程可见。使用 with multiprocessing.Manager() as manager: 确保管理器正确关闭。
共享内存与数据同步
共享内存的创建与使用,共享内存提供了高效的进程间数据共享方式,特别适合大数据量的场景。
import multiprocessing
import numpy as np
from multiprocessing import shared_memory
import time
def worker(shm_name, shape, dtype, start, end):
# 连接到已有的共享内存
existing_shm = shared_memory.SharedMemory(name=shm_name)
# 创建 NumPy 数组视图
array = np.ndarray(shape, dtype=dtype, buffer=existing_shm.buf)
print(f"子进程处理索引区间 [{start}:{end}]")
# 对指定区间的数据进行操作,比如平方
array[start:end] = array[start:end] ** 2
existing_shm.close()
if __name__ == "__main__":
# 创建一个 NumPy 数组
data = np.arange(10, dtype=np.int64)
print("原始数据:", data)
# 创建共享内存,大小为数组字节数
shm = shared_memory.SharedMemory(create=True, size=data.nbytes)
# 将共享内存映射为 NumPy 数组
shm_array = np.ndarray(data.shape, dtype=data.dtype, buffer=shm.buf)
# 将数据复制到共享内存
shm_array[:] = data[:]
# 启动两个进程分别处理数组不同部分
p1 = multiprocessing.Process(target=worker, args=(shm.name, data.shape, data.dtype, 0, 5))
p2 = multiprocessing.Process(target=worker, args=(shm.name, data.shape, data.dtype, 5, 10))
p1.start()
p2.start()
p1.join()
p2.join()
print("处理后数据:", shm_array[:])
# 关闭并释放共享内存
shm.close()
shm.unlink()
主进程创建共享内存并初始化数据。子进程通过共享内存名称连接到同一块内存,创建 NumPy 视图,操作共享数据。这样多进程间共享和修改同一块内存数据,共享内存使用完毕后,需调用 close() 和 unlink() 释放资源。
锁机制与同步原语
import multiprocessing
import time
import random
class BankAccount:
"""银行账户类,演示锁的使用"""
def __init__(self, initial_balance=1000):
self.balance = multiprocessing.Value('d', initial_balance)
self.lock = multiprocessing.Lock()
self.transaction_count = multiprocessing.Value('i', 0)
def deposit(self, amount, customer_id):
"""存款操作"""
with self.lock:
old_balance = self.balance.value
time.sleep(0.01) # 模拟处理时间
self.balance.value += amount
self.transaction_count.value += 1
print(f"客户 {customer_id} 存款 {amount},余额: {old_balance} -> {self.balance.value}")
def withdraw(self, amount, customer_id):
"""取款操作"""
with self.lock:
if self.balance.value >= amount:
old_balance = self.balance.value
time.sleep(0.01) # 模拟处理时间
self.balance.value -= amount
self.transaction_count.value += 1
print(f"客户 {customer_id} 取款 {amount},余额: {old_balance} -> {self.balance.value}")
return True
else:
print(f"客户 {customer_id} 取款 {amount} 失败,余额不足: {self.balance.value}")
return False
def get_balance(self):
"""获取余额"""
with self.lock:
return self.balance.value, self.transaction_count.value
def bank_customer(account, customer_id, operations):
"""银行客户进程"""
for operation in operations:
if operation['type'] == 'deposit':
account.deposit(operation['amount'], customer_id)
elif operation['type'] == 'withdraw':
account.withdraw(operation['amount'], customer_id)
time.sleep(random.uniform(0.1, 0.3))
class ProducerConsumerWithSemaphore:
"""使用信号量的生产者-消费者模式"""
def __init__(self, buffer_size=5):
self.buffer = multiprocessing.Queue(maxsize=buffer_size)
self.empty_slots = multiprocessing.Semaphore(buffer_size) # 空槽信号量
self.full_slots = multiprocessing.Semaphore(0) # 满槽信号量
self.mutex = multiprocessing.Lock() # 互斥锁
self.production_count = multiprocessing.Value('i', 0)
self.consumption_count = multiprocessing.Value('i', 0)
def producer(self, producer_id, num_items):
"""生产者进程"""
for i in range(num_items):
item = f"P{producer_id}-Item{i}"
# 等待空槽
self.empty_slots.acquire()
with self.mutex:
self.buffer.put(item)
with self.production_count.get_lock():
self.production_count.value += 1
print(f"生产者 {producer_id} 生产: {item} (队列大小: {self.buffer.qsize()})")
# 通知有新的满槽
self.full_slots.release()
time.sleep(random.uniform(0.1, 0.5))
print(f"生产者 {producer_id} 完成生产")
def consumer(self, consumer_id, max_items):
"""消费者进程"""
consumed = 0
while consumed < max_items:
try:
# 等待满槽
self.full_slots.acquire(timeout=2)
with self.mutex:
if not self.buffer.empty():
item = self.buffer.get()
with self.consumption_count.get_lock():
self.consumption_count.value += 1
consumed += 1
print(f"消费者 {consumer_id} 消费: {item} (队列大小: {self.buffer.qsize()})")
# 通知有新的空槽
self.empty_slots.release()
time.sleep(random.uniform(0.2, 0.8))
except:
print(f"消费者 {consumer_id} 超时退出")
break
print(f"消费者 {consumer_id} 完成消费,总计: {consumed}")
if __name__ == "__main__":
# 创建银行账户实例
account = BankAccount(initial_balance=1000)
# 定义多个客户的操作序列
customer_operations = [
[
{'type': 'deposit', 'amount': 200},
{'type': 'withdraw', 'amount': 150},
{'type': 'withdraw', 'amount': 100},
],
[
{'type': 'withdraw', 'amount': 300},
{'type': 'deposit', 'amount': 400},
{'type': 'withdraw', 'amount': 50},
],
[
{'type': 'deposit', 'amount': 500},
{'type': 'withdraw', 'amount': 700},
{'type': 'deposit', 'amount': 100},
],
]
# 启动银行客户进程
customer_processes = []
for i, ops in enumerate(customer_operations):
p = multiprocessing.Process(target=bank_customer, args=(account, i+1, ops))
customer_processes.append(p)
p.start()
# 等待所有客户进程完成
for p in customer_processes:
p.join()
# 打印最终余额和交易次数
final_balance, transaction_count = account.get_balance()
print(f"\n最终账户余额: {final_balance}")
print(f"总交易次数: {transaction_count}")
print("\n" + "="*50 + "\n")
# 生产者-消费者模型测试
buffer_size = 5
pc = ProducerConsumerWithSemaphore(buffer_size=buffer_size)
num_producers = 2
num_consumers = 2
items_per_producer = 10
# 启动生产者进程
producers = []
for i in range(num_producers):
p = multiprocessing.Process(target=pc.producer, args=(i+1, items_per_producer))
producers.append(p)
p.start()
# 启动消费者进程
consumers = []
total_items = num_producers * items_per_producer
items_per_consumer = total_items // num_consumers
for i in range(num_consumers):
c = multiprocessing.Process(target=pc.consumer, args=(i+1, items_per_consumer))
consumers.append(c)
c.start()
# 等待所有生产者完成
for p in producers:
p.join()
# 等待所有消费者完成
for c in consumers:
c.join()
print(f"\n生产总数: {pc.production_count.value}")
print(f"消费总数: {pc.consumption_count.value}")银行账户类:锁机制保证数据一致性
使用multiprocessing.Value存储共享余额和交易计数。通过multiprocessing.Lock实现对余额和计数的互斥访问,防止竞态条件。
多个客户进程并发执行存款和取款操作,锁保证每次操作的原子性和数据一致性。模拟处理延迟,体现真实环境下的并发访问风险。
生产者-消费者模型:信号量实现同步控制
使用multiprocessing.Queue作为缓冲区,限制最大容量。empty_slots信号量表示缓冲区空槽数量,full_slots信号量表示满槽数量。
生产者进程在放入数据前等待空槽,放入后释放满槽信号量。消费者进程在取数据前等待满槽,取出后释放空槽信号量。互斥锁mutex保护缓冲区操作,避免并发冲突。生产者和消费者通过信号量和锁协同工作,实现高效安全的数据交换。
条件变量与屏障同步
import multiprocessing
import random,time
class TaskCoordinator:
"""任务协调器,使用条件变量"""
def __init__(self, manager, num_workers):
self.num_workers = num_workers
self.tasks = manager.Queue()
self.results = manager.dict()
self.condition = manager.Condition()
self.workers_ready = manager.Value('i', 0)
self.all_done = manager.Value('b', False)
def worker_process(self, worker_id):
"""工作进程"""
# 通知准备就绪
with self.condition:
self.workers_ready.value += 1
print(f"工作进程 {worker_id} 准备就绪")
self.condition.notify_all()
# 等待所有工作进程准备就绪
while self.workers_ready.value < self.num_workers:
self.condition.wait()
print(f"工作进程 {worker_id} 开始工作")
# 处理任务
while True:
try:
task = self.tasks.get(timeout=1)
if task is None:
break
# 执行任务
result = task['data'] ** 2
self.results[task['id']] = {
'worker_id': worker_id,
'result': result
}
print(f"工作进程 {worker_id} 完成任务 {task['id']}")
time.sleep(0.1)
except:
break
print(f"工作进程 {worker_id} 结束工作")
class BarrierSynchronization:
"""屏障同步演示"""
def __init__(self, num_processes):
self.num_processes = num_processes
self.barrier = multiprocessing.Barrier(num_processes)
def phase_worker(self, worker_id, phases):
"""分阶段工作的进程"""
for phase in range(phases):
# 执行当前阶段的工作
work_time = random.uniform(1, 3)
print(f"工作进程 {worker_id} 开始阶段 {phase + 1}")
time.sleep(work_time)
print(f"工作进程 {worker_id} 完成阶段 {phase + 1} (耗时 {work_time:.2f}s)")
# 等待所有进程完成当前阶段
print(f"工作进程 {worker_id} 等待其他进程完成阶段 {phase + 1}")
try:
self.barrier.wait(timeout=10)
print(f"工作进程 {worker_id} 继续下一阶段")
except multiprocessing.BrokenBarrierError:
print(f"工作进程 {worker_id} 屏障被破坏")
break
except Exception as e:
print(f"工作进程 {worker_id} 屏障等待异常: {e}")
break
print(f"工作进程 {worker_id} 完成所有阶段")
def main():
num_workers = 4
num_phases = 3
# 使用 Manager 创建共享对象
with multiprocessing.Manager() as manager:
# 任务协调器测试(条件变量)
coordinator = TaskCoordinator(manager, num_workers)
# 添加任务
for i in range(10):
coordinator.tasks.put({'id': i, 'data': i + 1})
# 添加结束信号
for _ in range(num_workers):
coordinator.tasks.put(None)
# 启动工作进程
worker_procs = []
for wid in range(num_workers):
p = multiprocessing.Process(target=coordinator.worker_process, args=(wid,))
worker_procs.append(p)
p.start()
# 等待所有工作进程完成
for p in worker_procs:
p.join()
print("\n所有工作进程完成,结果汇总:")
for task_id, res in sorted(coordinator.results.items()):
print(f"任务 {task_id} 由工作进程 {res['worker_id']} 处理,结果: {res['result']}")
print("\n" + "="*50 + "\n")
# 屏障同步测试
barrier_sync = BarrierSynchronization(num_workers)
phase_procs = []
for wid in range(num_workers):
p = multiprocessing.Process(target=barrier_sync.phase_worker, args=(wid, num_phases))
phase_procs.append(p)
p.start()
for p in phase_procs:
p.join()
if __name__ == "__main__":
main()条件变量(Condition)实现任务协调
目的:确保所有工作进程在开始处理任务前都已准备就绪,避免部分进程提前执行。
实现:使用manager.Condition()创建跨进程条件变量。每个工作进程启动时,先在条件变量保护下将workers_ready计数加一,并调用notify_all()通知其他进程。进程在条件变量上等待,直到所有进程准备完毕。
任务处理:进程从共享任务队列中获取任务,执行计算(平方操作),将结果存入共享字典。通过超时机制避免死锁,任务完成后进程退出。
屏障(Barrier)实现分阶段同步
目的:多进程分阶段执行任务,每个阶段结束后等待所有进程完成,保证阶段间同步。
实现:使用multiprocessing.Barrier创建屏障,指定参与进程数。每个进程执行阶段任务后调用barrier.wait()等待其他进程。支持超时和异常处理,避免屏障破坏导致死锁。
应用场景:适合分阶段计算、分布式训练等需要阶段同步的任务。
实战案例:简单的分布式计算框架
import multiprocessing
import time
import hashlib
import logging
from enum import Enum
from typing import Callable
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
class TaskStatus(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
class Task:
def __init__(self, task_id: str, func_name: str, args: tuple = (), kwargs: dict = None):
self.task_id = task_id
self.func_name = func_name
self.args = args
self.kwargs = kwargs or {}
self.status = TaskStatus.PENDING
self.result = None
self.error = None
self.created_time = time.time()
self.start_time = None
self.end_time = None
self.worker_id = None
def to_dict(self):
return {
'task_id': self.task_id,
'func_name': self.func_name,
'args': self.args,
'kwargs': self.kwargs,
'status': self.status.value,
'result': self.result,
'error': self.error,
'created_time': self.created_time,
'start_time': self.start_time,
'end_time': self.end_time,
'worker_id': self.worker_id
}
@classmethod
def from_dict(cls, data):
task = cls(data['task_id'], data['func_name'], data['args'], data['kwargs'])
task.status = TaskStatus(data['status'])
task.result = data['result']
task.error = data['error']
task.created_time = data['created_time']
task.start_time = data['start_time']
task.end_time = data['end_time']
task.worker_id = data['worker_id']
return task
def fibonacci(n):
"""计算斐波那契数列第n项"""
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
def calculate_prime(n):
"""判断是否为质数"""
import math
if n < 2:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True
def worker_loop(task_queue, result_queue, task_registry, function_registry, system_stats, worker_id):
logger = logging.getLogger(f"Worker-{worker_id}")
logger.info(f"Worker {worker_id} started.")
while True:
try:
task_dict = task_queue.get(timeout=1)
if task_dict is None:
logger.info(f"Worker {worker_id} received stop signal.")
break
task = Task.from_dict(task_dict)
task.status = TaskStatus.RUNNING
task.start_time = time.time()
task.worker_id = worker_id
task_registry[task.task_id] = task.to_dict()
func = function_registry.get(task.func_name)
if func is None:
raise ValueError(f"Function '{task.func_name}' not found.")
result = func(*task.args, **task.kwargs)
task.result = result
task.status = TaskStatus.COMPLETED
task.end_time = time.time()
system_stats['completed_tasks'] += 1
task_registry[task.task_id] = task.to_dict()
result_queue.put(task.to_dict())
logger.info(f"Worker {worker_id} completed task {task.task_id}")
except Exception as e:
logger.error(f"Worker {worker_id} error: {e}")
system_stats['failed_tasks'] += 1
def generate_task_id(func_name, args, kwargs):
content = f"{func_name}_{args}_{kwargs}_{time.time()}"
return hashlib.md5(content.encode()).hexdigest()[:16]
def main():
multiprocessing.set_start_method('spawn') # Windows 平台推荐显式设置
manager = multiprocessing.Manager()
task_queue = multiprocessing.Queue()
result_queue = multiprocessing.Queue()
task_registry = manager.dict()
system_stats = manager.dict({'completed_tasks': 0, 'failed_tasks': 0})
function_registry = manager.dict()
# 注册函数
function_registry['fibonacci'] = fibonacci
function_registry['calculate_prime'] = calculate_prime
# 添加任务
tasks = [
('fibonacci', (35,), {}),
('calculate_prime', (1009,), {}),
('fibonacci', (40,), {}),
('calculate_prime', (1013,), {}),
]
for func_name, args, kwargs in tasks:
task_id = generate_task_id(func_name, args, kwargs)
task = Task(task_id, func_name, args, kwargs)
task_registry[task_id] = task.to_dict()
task_queue.put(task.to_dict())
# 启动工作进程
num_workers = 4
workers = []
for i in range(num_workers):
p = multiprocessing.Process(
target=worker_loop,
args=(task_queue, result_queue, task_registry, function_registry, system_stats, i)
)
p.start()
workers.append(p)
# 发送停止信号
for _ in range(num_workers):
task_queue.put(None)
# 等待所有工作进程结束
for p in workers:
p.join()
# 输出结果
print("\n任务执行结果:")
while not result_queue.empty():
task_result = result_queue.get()
print(f"任务ID: {task_result['task_id']}, 函数: {task_result['func_name']}, 结果: {task_result['result']}")
print(f"\n系统统计: 完成任务数={system_stats['completed_tasks']}, 失败任务数={system_stats['failed_tasks']}")
if __name__ == "__main__":
main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









