




 本文探讨了深度学习中遇到的梯度消失和梯度爆炸问题,指出这两者分别与网络层数、激活函数选择以及权值初始化有关。数学说明部分展示了梯度如何受这些因素影响。解决方案包括更换激活函数、采用梯度剪切、权重正则化以及使用批规范化(BatchNorm)。BatchNorm通过规范化操作提升网络训练的稳定性和收敛速度。
本文探讨了深度学习中遇到的梯度消失和梯度爆炸问题,指出这两者分别与网络层数、激活函数选择以及权值初始化有关。数学说明部分展示了梯度如何受这些因素影响。解决方案包括更换激活函数、采用梯度剪切、权重正则化以及使用批规范化(BatchNorm)。BatchNorm通过规范化操作提升网络训练的稳定性和收敛速度。
梯度爆炸和消失
两种情况下梯度消失经常出现,一是在深层网络中,二是采用了不合适的激活函数,比如sigmoid。梯度爆炸一般出现在深层网络和权值初始化值太大的情况下,下面分别从这两个角度分析梯度消失和爆炸的原因。
数学说明

这边我做了做了一个两个隐层梯度的推导,看的出来层数逐渐变多,影响最大的便是权值w和激活函数,他们中的任意一个大于1或者小于1,连乘都会造成梯度的消失和爆炸。
梯度消失的一个例子

接近output层的参数基本已经收敛,收敛后基本训练就结束了,但是前面接近input的参数还是随机的。
一般的深层神经网络都具有这样的缺陷,这边提一下rnn的梯度的问题,rnn即便是浅层,也是会出现梯度的问题,尤其是当它time_step越长的时候,建模的序列越长它就越是容易遗忘,这就是梯度出问题,本质上它每一刻之间的梯度传递也是连乘的,激活函数和权值影响也是一样的。解决方案就是lstm,主要解决的是梯度消失的问题,也就是遗忘问题。
梯度爆炸是很容易发现的,它会让你的参数爆掉,使用梯度剪切就很好解决但梯度消失不太容易发现
解决方案
- 替换其他激活函数

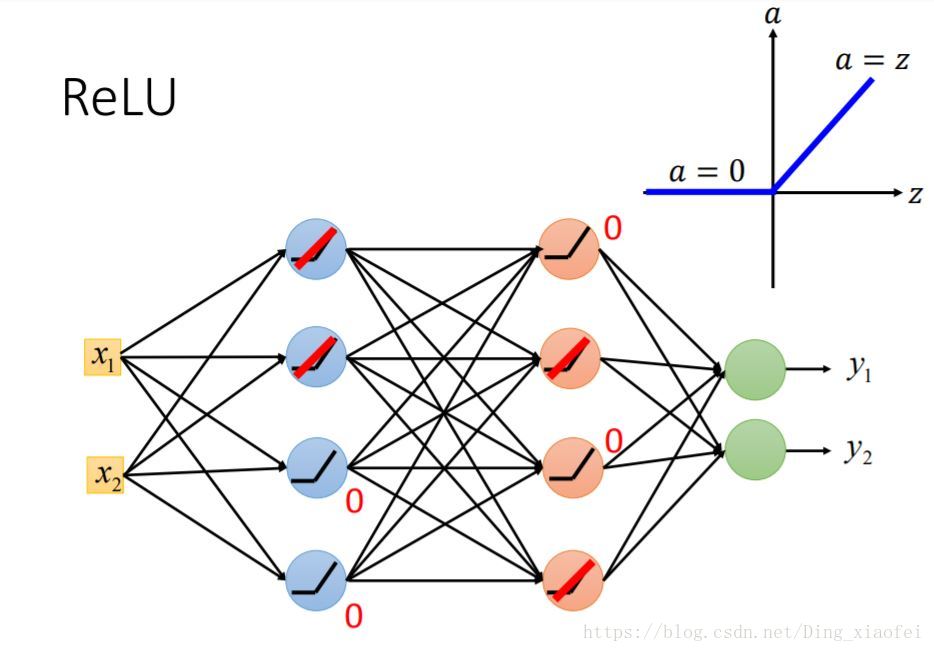
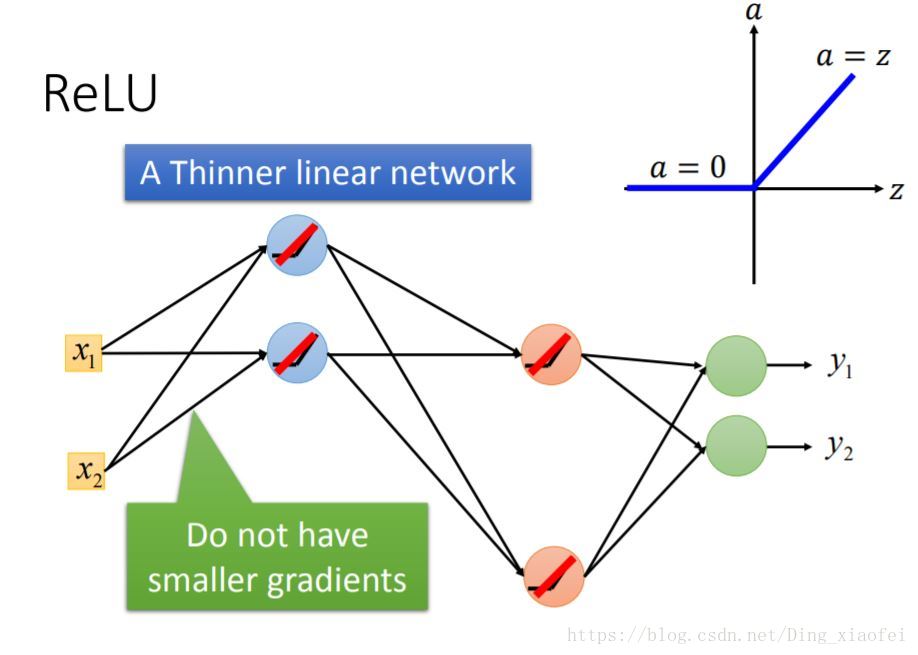
注意这边并没有退化成线性模型,每当权值发生变化,神经元接受的输入也就发生变化,激活的区域也就发生变化,其实它是局部线性的。
- 梯度剪切、正则
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)比较常见的是l1正则,和l2正则。(这边很好理解,l2让我们的权值变得比较小,自然就不容易爆炸了)
不过在神经网络里面出现得更多的是梯度消失。
- batch norm
Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。
可以参考博客


















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









