



transformer是一个预学习模型。通过预先学习建立参数范式,用参数范式来匹配答案。
transformer通过编码器和解码器,构造各种函数模具线性和非线性、通过自注意力机制模拟单词之间的联系构造,通过位置编码加入位置信息。
为什么用编码和解码器。因为要生产的序列不是端对端对等的,有N:1,N:M等,通过编码解码器能够更好的模拟。
为什么采用自注意力机制,因为解决理解每个单词的全局环境联系,通过理解全局环境的联系才能更好的理解单词。例如他苹果,可以理解为苹果手机、或者水果苹果,只有通过全局环境的联系才能理解苹果的真正含义。之前用RNN可以解决该问题,但是RNN是一个全局序列表示,每一个都需要前一个T-1的输入,且RNN的序列参数是相等的不能合理表示每个单词对不同前序单词的关注差异。
自注意力机制(Self-Attention):让每个词都能关注句子中的其他所有词,而不是仅仅关注前后相邻的词。通过计算Query、Key、Value之间的关系,为不同词分配不同的权重,决定哪些词对当前词最重要。
多头注意力(Multi-Head Attention):使用多个注意力头,让模型从不同角度理解文本,增强模型的表达能力。
前馈神经网络(Feedforward Neural Network):对每个Token进行非线性变换,提高模型表达能力。
位置编码(Positional Encoding):由于Transformer不包含循环结构,使用位置编码来保留词语的顺序信息。
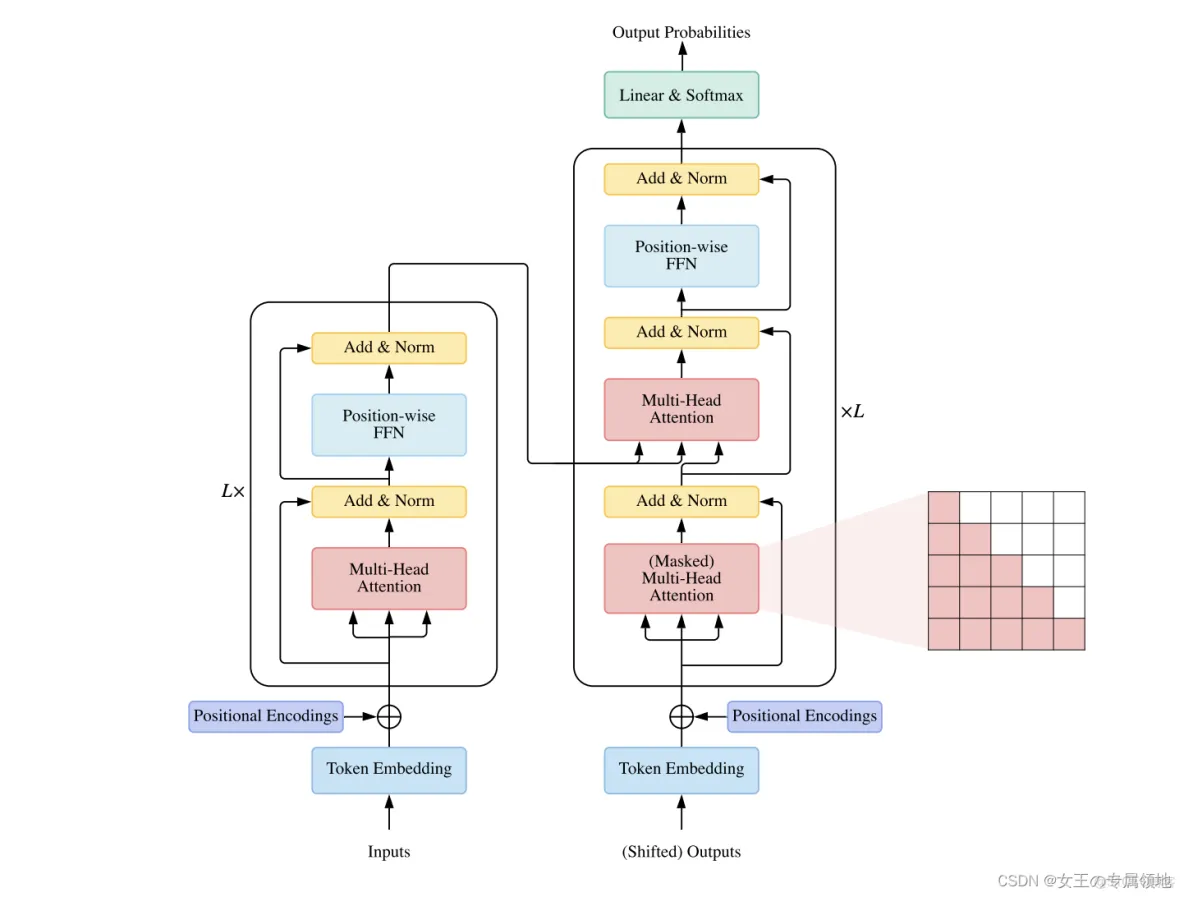
编码过程
1、形成词向量。
2、词向量通过*3个M矩阵形成Q、K、V3向量矩阵。
3、添加位置时序信息,通过sin或者cos函数形成。
4、通过多头注意力机制记录单词对前序词的权重关系。多个头分别记录不同的场景,丰富表达。通过最后一维对Q、K、V分割为H份,每份分别进行多头注意力计算,然后进行线性相加,在通过矩阵乘积转化为D维。可以沿着Q、K、V向量的最后一维度,按照头的数量平均拆分成H份,获得用于多头计算的{𝑄𝑖∈𝑅𝐿×𝐷ℎ,𝐾𝑖∈𝑅𝐿×𝐷ℎ,𝑉𝑖∈𝑅𝐿×𝐷ℎ∣𝑖=1,2,...,𝐻}{Qi∈RL×Dh,Ki∈RL×Dh,Vi∈RL×Dh∣i=1,2,...,H}向量,其中𝐷ℎ=𝐷𝑣𝐻Dh=HDv。接下来,需要根据每个头的QKV向量进行自注意力计算。
多头结果融合:将多个头计算的自注意力结果进行融合,得到最终得输出向量𝑍Z。
𝑍=MultiHeadAttention(𝑋)≜(ℎ𝑒𝑎𝑑1⊕ℎ𝑒𝑎𝑑2⊕...⊕ℎ𝑒𝑎𝑑𝐻)𝑊Z=MultiHeadAttention(X)≜(head1⊕head2⊕...⊕headH)W
其中⊕表示沿着向量的最后一维进行拼接,拼接后向量维度可能并不等于原始向量的维度𝐷D,因此这里乘以矩阵$ \mathbf W\in \mathbb{R}^{(H*D_h) \times D},将向量映射为原始的输入维度,将向量映射为原始的输入维度D$。
5、Add&Norm 加与规范层:使得网络训练更加稳定,收敛性更好。
6、前馈网络(Feed Forward Network):通过FFN 的第一个组成部分是一个线性层,其特征参数为 和 ,然后引入ReLU 激活函数。ReLU 是引入非线性的主流选择,这对于增强模型捕捉数据中的复杂规律至关重要。
7、形成的多头计算通过拼接到一起然后在进行线性计算转换为一个。
解码过程
7、前面3步类似编码过程。后面有掩码多头注意力机制。
8、类似编码,引入了编码的输出。
9、解码后通过最后的线性层接上一个softmax,其中线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更高维度的向量(logits)上,假设我们模型的词汇表是10000个词,那么logits就有10000个维度,每个维度对应一个惟一的词的得分。之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!

















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









