






Hadoop是开源项目,提供分布式数据存储(HDFS),分布式数据计算(MapReduce,Spark,Flink),分布式资源调度(Yarn)
个人企业可以借助hadoop完成海量数据存储和计算
HDFS:
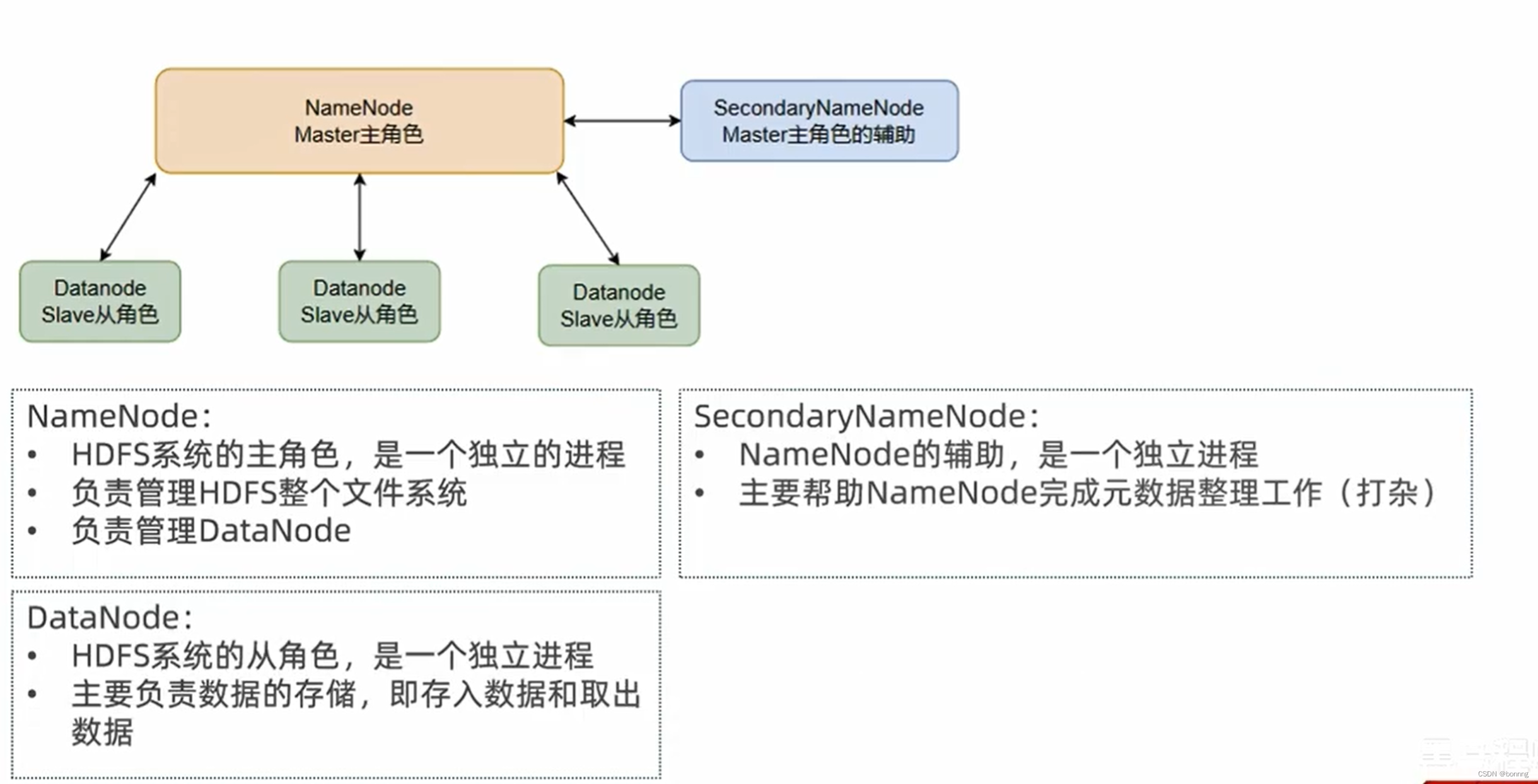
Namenode的元数据:
edits是流水账文件,记录了的每一次hdfs操作,定时定量的讲大量edits整合为一个fsimage文件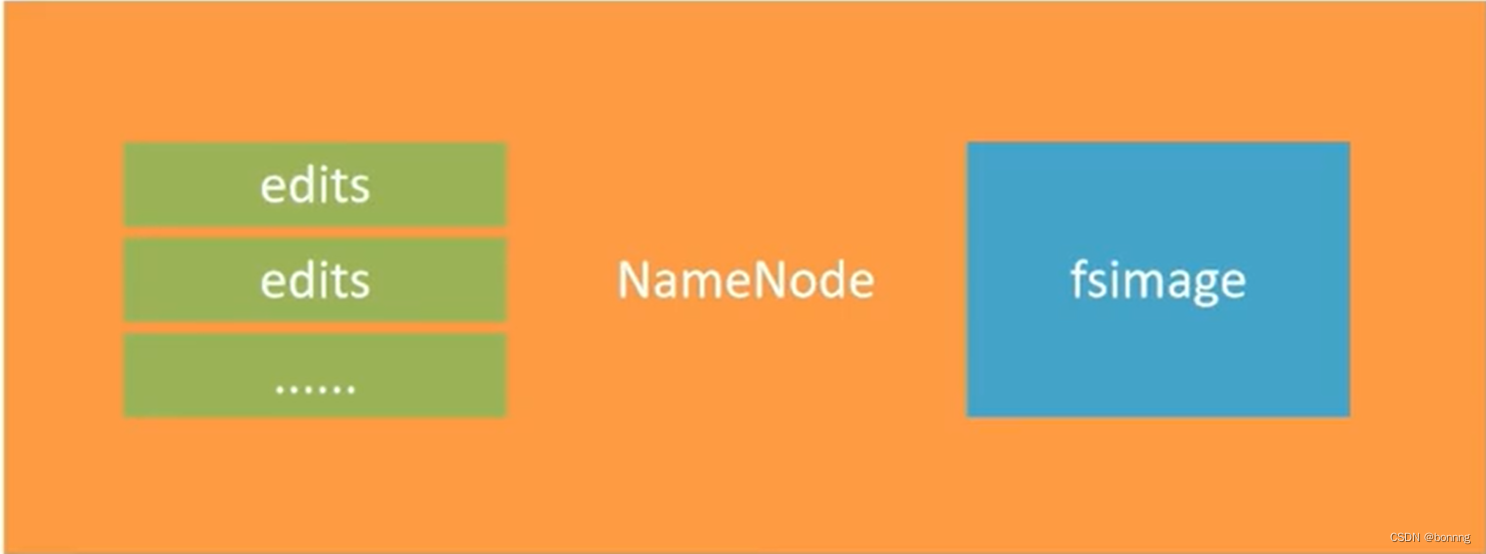
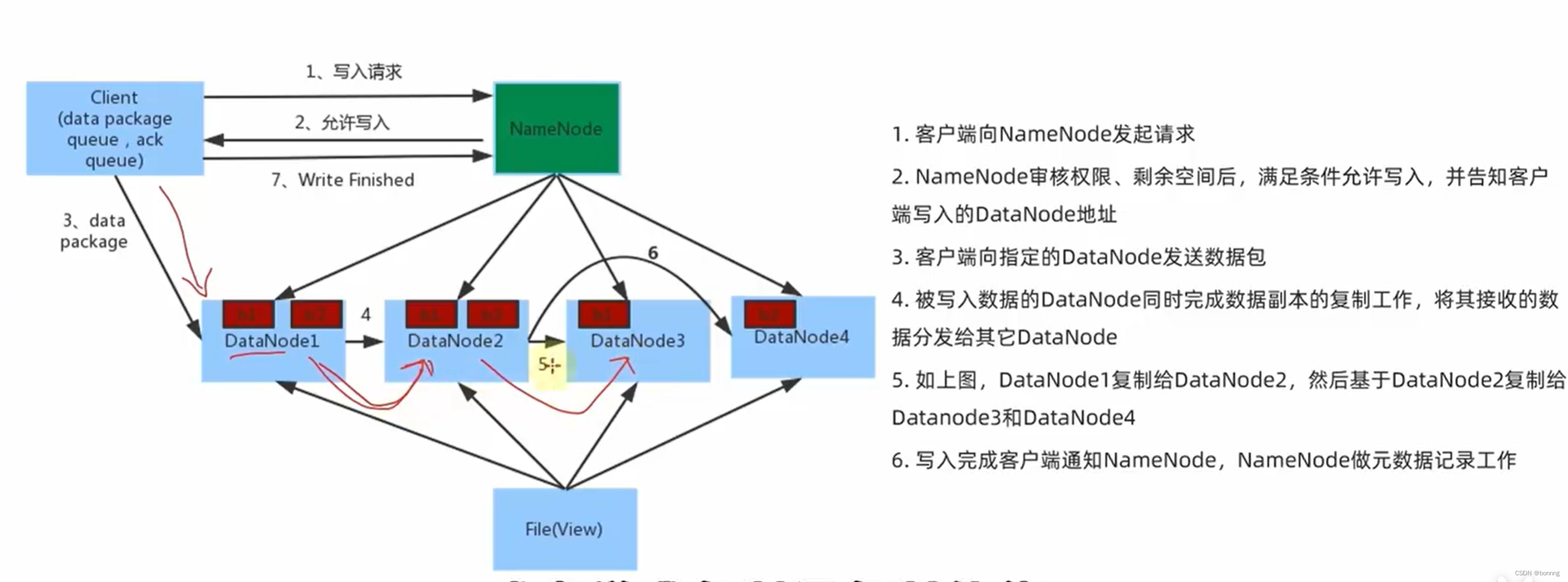
写入操作:
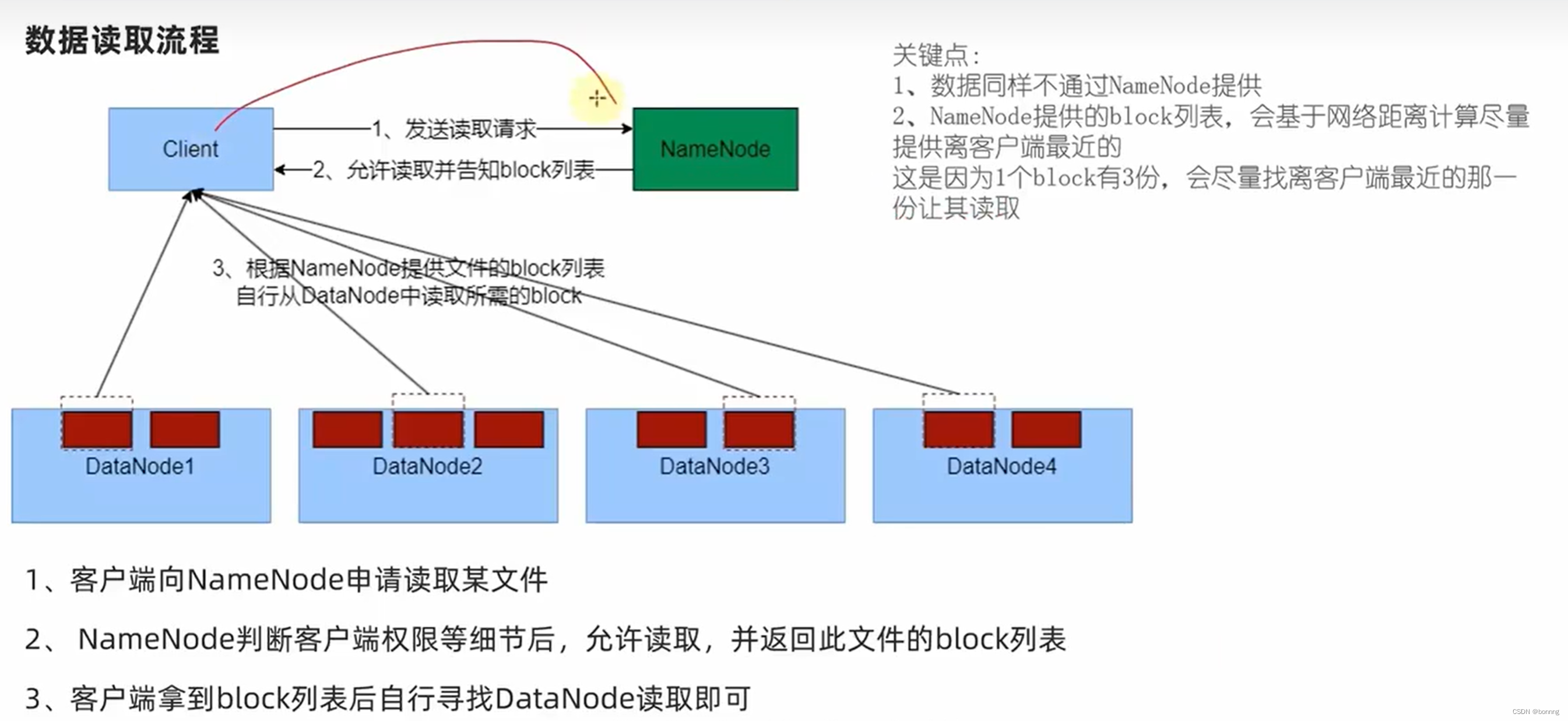
读取操作:
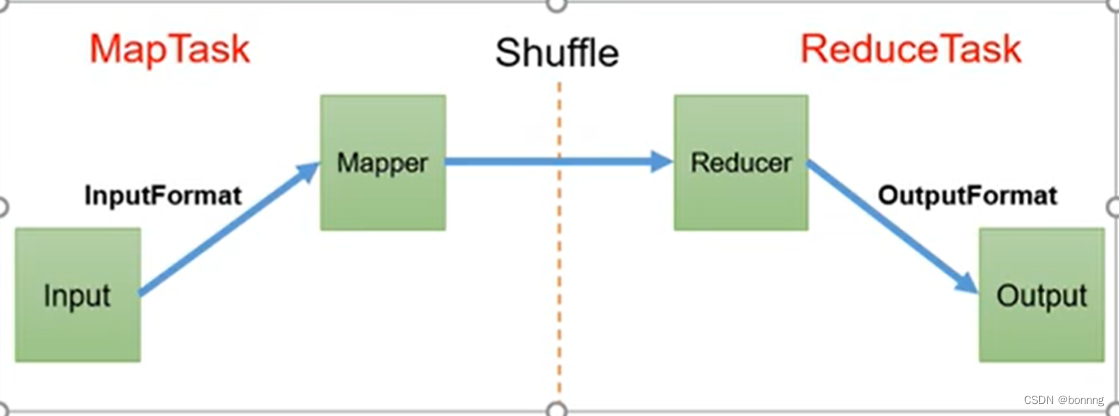
Mapreduce:
map:分散 reduce:汇总
Yarn:资源调度
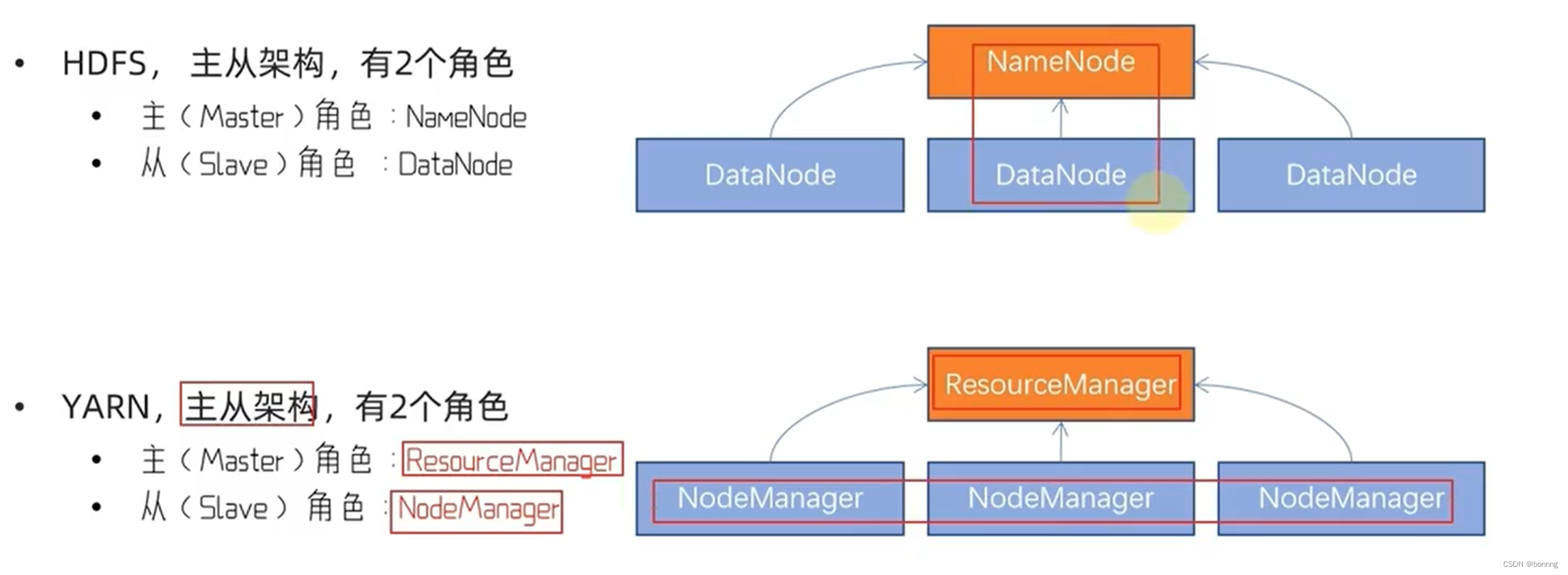
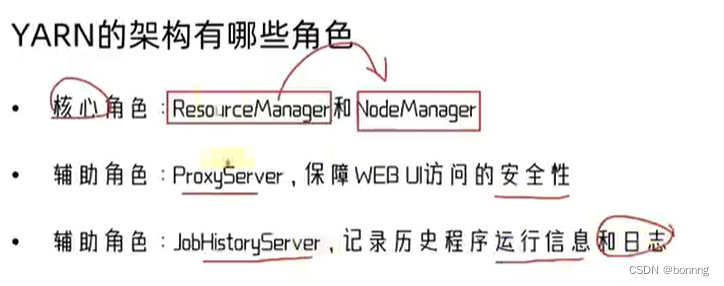
ResourceManager:整个集群的资源调度者
NodeManager:单个服务器的资源调度者
yarn容器:

yarn架构:
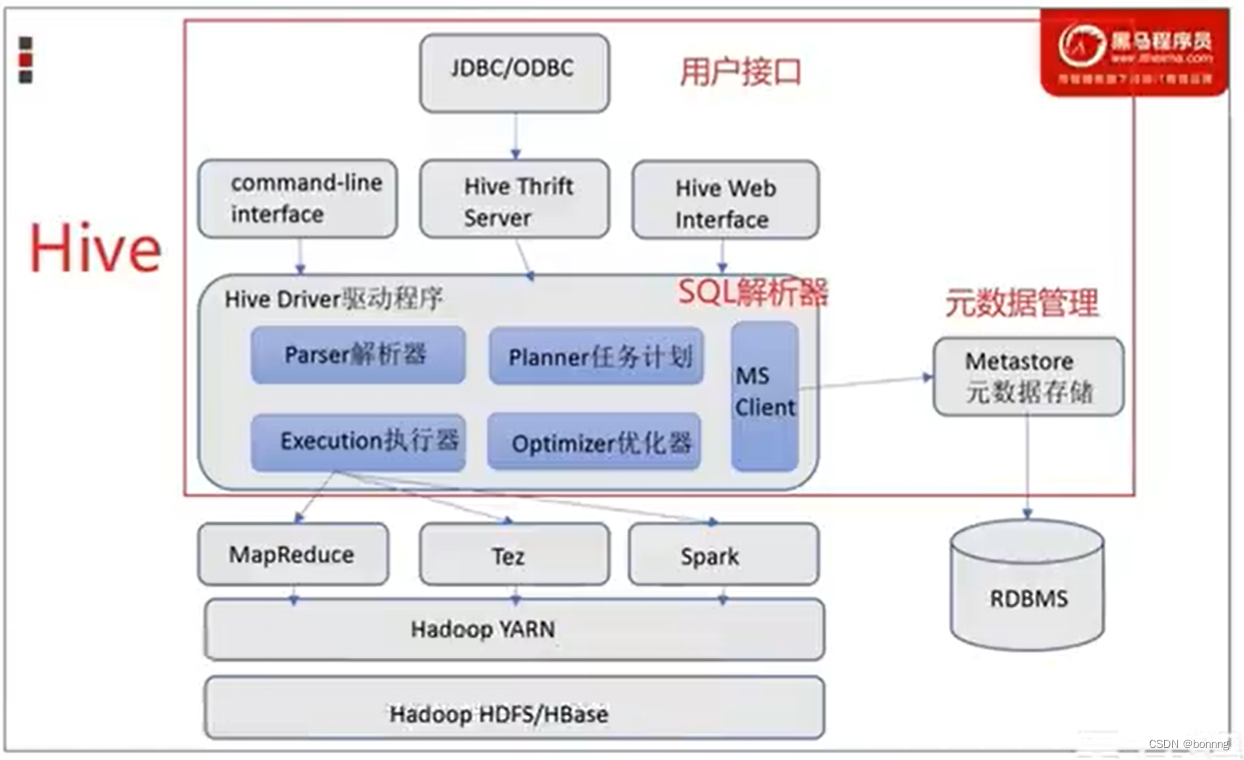
Hive
将sql翻译成MapReduce
结构:

启动Hive
1、直接在Linux系统中启动Hive:/bin/hive
2、间接:bin/service --hiveserver2 启动服务提供thrift接口给其他客户端链接:DataGrip,DBeaver

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









