



在当今数字化时代,网络爬虫作为一种重要的数据收集工具,广泛应用于搜索引擎、数据分析、商业情报等领域。然而,恶意爬虫的出现,却给网站安全带来了前所未有的挑战。今天我们就来简单了解下什么是恶意爬虫,爬虫对网站的危害,以及在当前网络安全形势下,该如何有效应对这一威胁。
一、恶意爬虫的定义
恶意爬虫,是指未经授权或违反服务条款,擅自对目标网站进行大量、高频的数据抓取行为。这些爬虫程序往往由第三方编写,旨在获取敏感信息、商业机密或进行不正当竞争。与善意爬虫(如搜索引擎爬虫)相比,恶意爬虫缺乏合法性和合规性,对目标网站构成了严重的安全威胁。
二、恶意爬虫对网站的危害
数据泄露与隐私侵犯
恶意爬虫能够抓取用户的个人信息,如姓名、地址、电话号码等,导致隐私泄露。同时,它们还可能窃取企业或政府机构的敏感信息,如商业机密、政府文件等,造成重大损失。
服务器负载压力
大量的恶意爬虫请求会消耗网站的带宽、CPU等资源,导致服务器负载过重,影响网站性能和稳定性。严重时,甚至会导致业务服务阻塞、宕机,影响用户体验和业务运营。
不正当竞争
恶意爬虫被用于获取竞争对手的商业信息,如价格、客户名单等,从而进行不公平竞争。这种行为不仅损害了被爬取方的利益,也破坏了市场秩序。
知识产权侵害
未经授权地爬取具有版权归属的影视作品、文学作品等,构成对知识产权的侵害。这种侵权行为不仅违法,也损害了原创者的合法权益。
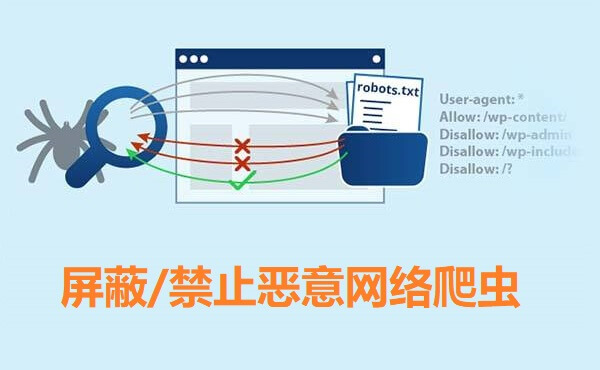
三、针对恶意爬虫的应对策略
面对恶意爬虫的威胁,网站需要采取一系列措施来加强安全防护:
1、使用验证码
在登录、注册、重置密码等敏感操作时,引入验证码机制。这可以有效防止恶意爬虫自动完成操作,降低账户被盗用和数据泄露的风险。
2、设置反爬虫机制
通过用户行为分析、IP地址封锁、User Agent限制等手段,设置反爬虫机制。一旦发现异常操作,立即封锁相关IP地址,保护网站数据安全。
3、限制访问频率
对同一IP地址的访问频率进行限制,减缓恶意攻击和爬虫程序对网站造成的影响。同时,设置每秒钟最大请求数,进一步控制流量。
4、使用动态页面
动态页面在网页加载时动态生成内容,而非在服务端生成HTML代码后返回。这可以有效避免被静态页面的恶意攻击和爬虫程序抓取数据。
5、加强授权管理
对特定的网页内容进行授权管理,确保只有合法用户才能访问敏感信息。这有助于防止敏感信息被非法获取和泄露。
6、实施内容安全策略(CSP)
通过限制网页中允许加载的资源和脚本来源,提高网站的安全性。这有助于检测和防止恶意脚本的注入和执行。
7、监测与响应
使用网站监控工具实时监测网站的访问情况,一旦发现异常请求或流量模式,及时采取相应的措施,如暂时封禁IP地址或进行报警处理。
8、使用SSL证书
SSL证书可以对传输过程中的数据进行加密,防止数据被窃取。这有助于保护网站数据安全,提高用户体验。
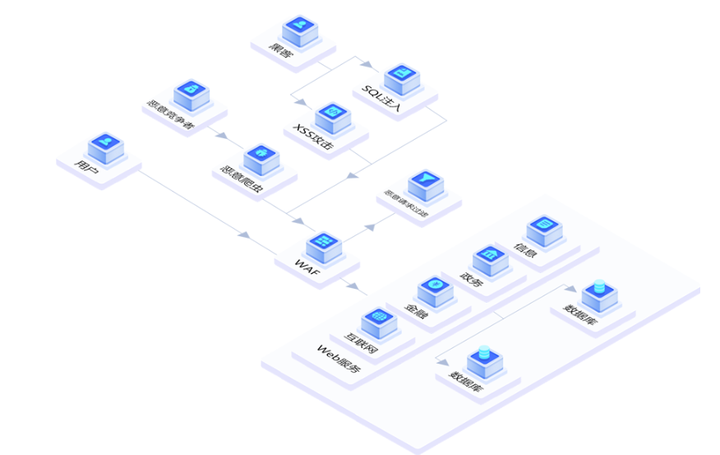
9、部署安全SCDN
德迅云安全SCDN,除了对网站可以提供缓存加速效果,减轻源站服务器压力之外,同时针对Bot安全防护,拥有精准访问控制、HTTP防护,以及恶意爬虫拦截。 后台一键添加,安全防护,一键拦截恶意爬虫。
结语
随着网络技术的不断发展,恶意爬虫的手段也在不断升级。为了绕过网站管理员的防爬策略,专业的爬虫往往会不断变换爬取手段,依靠固定的单一规则很难实现全面防护。因此,网站需要不断更新和完善防爬虫策略,以适应不断变化的威胁环境。
同时,网络安全形势的严峻也催生了新的发展机遇。通过加强网络安全技术研发和应用,可以推动网络安全产业的快速发展。此外,提高公众对网络安全的认识和防范意识,也是构建网络安全防线的重要一环。
恶意爬虫作为网站安全的隐形威胁,需要引起高度重视。通过采取一系列有效的应对策略,如使用德迅云安全SCDN,可以显著降低恶意爬虫对网站造成的危害。在当前网络安全形势下,我们需要不断更新和完善防爬虫策略,加强技术研发和应用,提高公众的安全意识,共同构建安全、稳定的网络环境。

















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









