《数字图像处理与计算机视觉实训》指导书
—— 从零动⼿实现 YOLOv1 ⽬标检测算法
⼀、实训⽬的
本次《图像处理与计算机视觉实训》围绕从零动⼿实现 YOLOv1 ⽬标检测算法展开,旨在让学⽣深⼊
理解 YOLOv1 算法的核⼼原理,包括其将⽬标检测转化为回归问题的独特思路、⽹格划分机制、边界
框预测及类别概率计算⽅法等。同时,通过实际动⼿操作,提升学⽣在 Python 编程、深度学习框架
(如 PyTorch)应⽤、数据预处理、模型搭建、训练与评估等⽅⾯的实践能⼒,培养学⽣发现问题、分
析问题和解决问题的能⼒,为后续更深⼊的图像处理与计算机视觉相关学习和研究奠定坚实基础。
⼆、实训环境
(⼀)硬件要求
1. 计算机:建议配置 Intel Core i5 及以上处理器,或同等性能的 AMD 处理器;内存⾄少 8GB,推荐
16GB 及以上;硬盘预留⾄少 50GB 可⽤空间,⽤于存储数据集、代码及相关⽂件。
2. 显卡:若条件允许,建议配备 NVIDIA 显卡,且具有⾄少 2GB 显存,以加速模型训练过程,推荐
NVIDIA GTX 1050 及以上型号。
(⼆)软件要求
1. 操作系统:Windows 10/11、macOS(Intel 芯⽚或 Apple Silicon 芯⽚均可)、Linux(如 Ubuntu
18.04 及以上版本)。
2. 编程语⾔:Python 3.7-3.10 版本,该版本稳定性较好,且对相关深度学习库兼容性较强。
3. 相关库:
PyTorch:推荐 1.8.0 及以上版本,⽤于搭建和训练 YOLOv1 模型。
OpenCV:⽤于图像的读取、预处理、显⽰等操作,推荐 4.5.0 及以上版本。
NumPy:⽤于数据的数组运算,推荐 1.19.0 及以上版本。
Matplotlib:⽤于绘制损失曲线、检测结果等,推荐 3.3.0 及以上版本。
Pandas:若需要对数据集相关信息进⾏统计分析,可安装 1.1.0 及以上版本。
1. 开发⼯具:PyCharm(社区版或专业版均可)、VS Code,⼆者均具有良好的代码编辑、调试功
能,且对 Python 开发⽀持友好。
三、实训内容与步骤
(⼀)YOLOv1 算法原理学习
1. 算法整体思路:YOLOv1 将⽬标检测问题转化为⼀个端到端的回归问题。它⾸先把输⼊图像均匀地
分成 S×S 个⽹格,每个⽹格负责检测那些中⼼落在该⽹格内的⽬标。
2. ⽹格与边界框:每个⽹格会预测 B 个边界框,每个边界框包含 5 个参数,分别是边界框的中⼼坐标
(x,y)、边界框的宽度和⾼度(w,h)以及该边界框的置信度。置信度反映了该边界框是否包含⽬标
以及边界框预测的准确程度,其计算公式为:置信度 = Pr (object)×IOUtruth pred,其中 Pr (object)
表⽰边界框内存在⽬标的概率,若存在则为 1,否则为 0;IOUtruth pred 表⽰预测边界框与真实边
界框的交并⽐。
3. 类别概率预测:每个⽹格还会预测 C 个条件类别概率,即 Pr (classi|object),表⽰在该⽹格包含⽬
标的条件下,⽬标属于第 i 类的概率。
4. 最终检测结果计算:对于每个边界框,将其置信度与该⽹格的类别概率相乘,得到每个类别的置信
度得分,即 Pr (classi|object)×Pr (object)×IOUtruth pred=Pr (classi)×IOUtruth pred,该得分既反映
了⽬标属于某⼀类别的概率,也反映了预测边界框的准确程度。
可结合 YOLOv1 算法的相关图⽰(如⽹格划分图、边界框参数⽰意图等)帮助理解,建议阅读
YOLOv1 的原始论⽂《You Only Look Once: Unified, Real-Time Object Detection》加深对算法原理的
理解。
(⼆)数据准备
1. 数据集选择:本次实训所⽤数据集⾃⼰收集、⾃⼰标注(标注结果⽤yolo格式保存),数量⼤约
50~100张即可,检测⽬标为⼈脸,只有⼀个类别,但是⼀张图像可能有多个⼈脸。
2. 数据清洗:检查数据集中是否存在损坏的图像或标注错误的样本。对于损坏的图像,可直接删除;
对于标注错误的样本,若错误较轻微可⼿动修正,若错误严重则予以删除。
3. 数据预处理:
图像缩放:将所有图像统⼀缩放⾄ 448×448 尺⼨,这是 YOLOv1 算法要求的输⼊图像尺⼨。可使
⽤ OpenCV 的 cv2.resize() 函数实现,⽰例代码如下:
import cv2
image = cv2.imread("image_path.jpg")
resized_image = cv2.resize(image, (448, 448))
图像归⼀化:将图像的像素值归⼀化到 [0,1] 范围内,可通过将每个像素值除以 255 实现,⽰例代
码:
normalized_image = resized_image / 255.0
标签处理:若标注结果不符合yolo格式,则⼿动转换。
(三)模型搭建
1. YOLOv1 ⽹络结构:YOLOv1 的⽹络结构包含 24 个卷积层和 2 个全连接层。卷积层⽤于提取图像
的特征,其中前⼏个卷积层主要提取低级特征(如边缘、纹理等),后⾯的卷积层提取⾼级特征
(如⽬标的形状、部件等);池化层⽤于降低特征图的尺⼨,减少计算量,同时增强特征的鲁棒
性;全连接层⽤于输出最终的预测结果。
2. ⽤ PyTorch 搭建模型:
定义⽹络模型类:创建⼀个继承⾃ torch.nn.Module 的 YOLOv1 模型类,在 __init__ ⽅法中定义各
层结构,在 forward ⽅法中定义前向传播过程。
卷积层设置:每个卷积层使⽤ 3×3 的卷积核,部分卷积层后会跟随批量归⼀化(Batch
Normalization)和激活函数(如 Leaky ReLU)。例如,第⼀个卷积层的参数可以设置为输⼊通道
数 3(RGB 图像),输出通道数 64,步⻓为 2, padding 为 1,⽰例代码如下:
import torch
import torch.nn as nn
class YOLOv1(nn.Module):
def __init__(self, S=7, B=2, C=20):
super(YOLOv1, self).__init__()
self.S = S
self.B = B
self.C = C
# 卷积层部分
self.conv_layers = nn.Sequential(
# 第一层卷积
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.1),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第二层卷积
nn.Conv2d(64, 192, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(192),
nn.LeakyReLU(0.1),
nn.MaxPool2d(kernel_size=2, stride=2),
# 后续卷积层按照YOLOv1网络结构依次设置,此处省略部分代码
)
# 全连接层部分
self.fc_layers = nn.Sequential(
nn.Flatten(),
nn.Linear(1024 * S * S, 4096),
nn.LeakyReLU(0.1),
nn.Dropout(0.5),
nn.Linear(4096, S * S * (C + B * 5))
)
def forward(self, x):
x = self.conv_layers(x)
x = self.fc_layers(x)
# 将输出reshape为(S, S, C + B*5)
x = x.view(-1, self.S, self.S, self.C + self.B * 5)
return x
权重初始化:对⽹络的卷积层和全连接层进⾏权重初始化,可使⽤ PyTorch 提供的 nn.init 模块,
例如对卷积层的权重使⽤正态分布初始化,偏置初始化为 0,⽰例代码:
def init_weights(m):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0.0, std=0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
model = YOLOv1()
model.apply(init_weights)
(四)模型训练
1. 训练参数设置:
学习率:初始学习率可设置为 0.001,在训练过程中根据模型性能进⾏调整,如使⽤学习率衰减策
略,当损失不再下降时,将学习率乘以 0.1。
batch size:根据计算机的显卡显存⼤⼩进⾏设置,若显存较⼤,可设置为 16、32 等;若显存较
⼩,可设置为 8、4 等。
训练轮数(epochs):建议设置为 100-200 轮,具体可根据模型在验证集上的性能来确定,当模型
性能不再提升时可停⽌训练。
1. 优化器选择:使⽤ SGD(随机梯度下降)优化器,动量设置为 0.9,权重衰减(weight decay)设
置为 0.0005,以防⽌模型过拟合,⽰例代码:
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
1. 损失函数定义:YOLOv1 的损失函数较为复杂,包含坐标损失、置信度损失和类别损失三部分。
坐标损失:对于含有⽬标的边界框,计算预测边界框与真实边界框的坐标误差。其中,中⼼坐标
(x,y)的损失使⽤均⽅误差,宽度和⾼度的损失使⽤平⽅根的均⽅误差,以对较⼤的边界框和较⼩
的边界框的误差进⾏不同的处理,公式如下:
其中, 为坐标损失的权重,通常设置为 5; 表⽰第 i 个⽹格的第 j 个边界框负责检测⽬标
(即该边界框与真实边界框的 IOU 最⼤); 为真实边界框的参数; 为预
测边界框的参数。
Lcoord = λcoord ∑i
S
=0 I [(x −
2
∑j
B
=0 i
o
j
bj
i x^i)
2 + (yi − y^i)
2 + ( wi − w^i)
2 + ( hi −
h^
i)
2
]
λcoord Ii
o
j
bj
xi, yi, wi, hi x^i, y^i, w^i, h^
i
置信度损失:分为两部分,⼀部分是含有⽬标的边界框的置信度损失,另⼀部分是不含⽬标的边界
框的置信度损失。不含⽬标的边界框的置信度损失权重 通常设置为 0.5,公式如下:
其中, 为真实置信度(对于含有⽬标的边界框为 1,不含⽬标的为 0); 为预测置信度。
类别损失:计算预测类别概率与真实类别概率的误差,公式如下:
其中, 表⽰第 i 个⽹格含有⽬标; 为真实类别概率(属于第 c 类则为 1,否则为 0);
为预测类别概率。
总损失为以上三部分损失之和,可在 PyTorch 中⾃定义损失函数类实现,⽰例代码框架如下:
class YOLOv1Loss(nn.Module):
def __init__(self, S=7, B=2, C=20, lambda_coord=5, lambda_noobj=0.5):
super(YOLOv1Loss, self).__init__()
self.S = S
self.B = B
self.C = C
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
def forward(self, pred, target):
# pred形状为(batch_size, S, S, C + B*5)
# target形状为(batch_size, S, S, C + 5),其中5包括真实边界框参数和是否有目标的标志
batch_size = pred.size(0)
# 计算坐标损失、置信度损失和类别损失,此处省略具体计算过程
total_loss = coord_loss + conf_loss + class_loss
return total_loss / batch_size
1. 训练过程:
数据加载:使⽤ PyTorch 的 Dataset 和 DataLoader 类加载预处理后的数据集,实现数据的批量读取
和增强(如随机翻转、裁剪等)。
模型训练循环:对于每个 epoch,遍历训练数据集,将输⼊图像送⼊模型得到预测结果,计算损
失,然后通过反向传播更新模型参数。同时,定期在验证集上评估模型性能,⽰例代码框架如下:
λnoobj
Lconf = ∑i
S
=
2
0 ∑j
B
=0
Ii
o
j
bj
(Ci − C^
i)
2 + λnoobj ∑i
S
=
2
0 ∑j
B
=0
Ii
n
j
oobj
(Ci − C^
i)
2
Ci C^
i
Lclass = ∑i
S
=0
I (p (c) −
2
i
obj ∑c
C
=0 i p^i(c))
2
Ii
obj pi(c)
p^i(c)
criterion = YOLOv1Loss()
train_dataset = ... # 自定义的训练数据集
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataset = ... # 自定义的验证数据集
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
for epoch in range(epochs):
model.train()
train_loss = 0.0
for images, targets in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
train_loss /= len(train_dataset)
model.eval()
val_loss = 0.0
with torch.no_grad():
for images, targets in val_loader:
outputs = model(images)
loss = criterion(outputs, targets)
val_loss += loss.item() * images.size(0)
val_loss /= len(val_dataset)
print(f"Epoch {epoch+1}/{epochs}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
1. 训练效果监控:使⽤ Matplotlib 绘制训练损失和验证损失曲线,直观地观察模型的训练情况。若训
练损失持续下降⽽验证损失不再下降或上升,说明模型可能出现过拟合,可采取增加数据增强、调
整正则化参数等措施。⽰例代码:
import matplotlib.pyplot as plt
train_losses = [] # 存储每个epoch的训练损失
val_losses = [] # 存储每个epoch的验证损失
# 在每个epoch结束后将损失添加到列表中
# ...
plt.plot(range(1, epochs+1), train_losses, label='Train Loss')
plt.plot(range(1, epochs+1), val_losses, label='Val Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
(五)模型评估
1. 评估指标选择:使⽤ mAP(mean Average Precision)作为模型的评估指标。mAP 是⽬标检测任
务中常⽤的评估指标,它先计算每个类别的 AP(Average Precision),然后取所有类别的 AP 的平
均值。
2. AP 计算:对于每个类别,根据模型的预测结果和真实标签,计算不同置信度阈值下的精确率
(Precision)和召回率(Recall),绘制 P-R 曲线,AP 即为 P-R 曲线下的⾯积。
3. 模型评估实现:可使⽤第三⽅库(如 pycocotools)或⾃⾏编写代码计算 mAP。⾸先,将模型在测
试集上的预测结果转换为特定的格式(如包含图像 ID、类别、置信度、边界框坐标等信息),然后
与真实标签进⾏⽐对,计算 mAP。
(六)⽬标检测应⽤
1. 测试图像处理:选取测试集中的图像或⾃⾏拍摄的图像,按照数据预处理步骤进⾏处理(图像缩
放、归⼀化等)。
2. 模型预测:将处理后的图像输⼊训练好的 YOLOv1 模型,得到预测结果。
3. 结果后处理:对预测结果进⾏⾮极⼤值抑制(NMS)处理,去除冗余的边界框。NMS 的基本思路
是:对于同⼀类别的⽬标,⾸先选择置信度最⾼的边界框,然后计算其他边界框与该边界框的
IOU,若 IOU ⼤于设定的阈值(如 0.5),则将其删除,重复此过程直⾄处理完所有边界框。
4. 检测结果显⽰:使⽤ OpenCV 或 Matplotlib 将处理后的检测结果在图像上绘制出来,包括边界框和
对应的类别及置信度,⽰例代码:
import cv2
def draw_detection(image, bboxes, classes, confidences, class_names):
for bbox, cls, conf in zip(bboxes, classes, confidences):
x_center, y_center, w, h = bbox
image_height, image_width = image.shape[:2]
x1 = int((x_center - w / 2) * image_width)
y1 = int((y_center - h / 2) * image_height)
x2 = int((x_center + w / 2) * image_width)
y2 = int((y_center + h / 2) * image_height)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
label = f"{class_names[cls]}: {conf:.2f}"
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return image
# 示例调用
image = cv2.imread("test_image.jpg")
# 假设bboxes为经过NMS处理后的边界框列表,classes为类别索引列表,confidences为置信度列表
processed_image = draw_detection(image, bboxes, classes, confidences, class_names)
cv2.imshow("Detection Result", processed_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
四、注意事项
1. 数据⽅⾯:确保数据集的完整性和正确性,数据清洗和预处理步骤要仔细操作,否则会影响模型的
训练效果。在转换标签格式时,要准确计算边界框的相对坐标,避免出现错误。
2. 模型参数设置:模型的超参数(如学习率、batch size 等)对训练效果影响较⼤,可根据实际情况
进⾏调整。在训练过程中,若出现损失不下降或发散的情况,可检查学习率是否合适,或是否存在
数据预处理错误等问题。
3. 训练过程监控:定期查看训练损失和验证损失曲线,及时发现模型过拟合或⽋拟合的情况,并采取
相应的措施。同时,注意观察模型在验证集上的检测结果,直观地了解模型的性能。
4. 硬件资源使⽤:在训练模型时,会占⽤较多的计算机资源,尤其是显卡资源。避免在训练过程中同
时运⾏其他占⽤⼤量资源的程序,以防⽌训练中断或计算机卡顿。
5. 代码调试:在编写代码过程中,要养成良好的调试习惯,可使⽤ print 语句或调试⼯具查看变量的
值、⽹络的输出形状等,及时发现并解决代码中的错误。
五、考核⽅式
本次实训的考核将结合以下⼏个⽅⾯进⾏综合评定:
平时分(50%)
实训成果(50%),各项占⽐如下:
1. 实训报告(40%):要求学⽣撰写详细的实训报告,内容包括实训⽬的、实训环境、实训步骤、遇
到的问题及解决⽅法、模型训练与评估结果分析等。报告需结构清晰、内容完整、逻辑严谨。
2. 模型性能(30%):根据模型在测试集上的 mAP 值进⾏评定,mAP 值越⾼,得分越⾼。
3. 代码实现(30%):检查学⽣的代码是否完整、规范,是否能够正确实现 YOLOv1 算法的各个环节
(数据预处理、模型搭建、训练、评估、检测等)。代码需具有良好的可读性和可维护性,并有适
当的注释。




 本文深入探讨了Sobel、Scharr及拉普拉斯算子在图像边缘检测中的应用。通过对比不同算子的效果,如Sobel梯度、Scharr算子和拉普拉斯算子,揭示了scharr算子在描述图像细节上的优势。文章提供了详细的代码实现,包括Sobel算子的dx、dy参数设置,以及如何使用cv2库进行边缘检测。
本文深入探讨了Sobel、Scharr及拉普拉斯算子在图像边缘检测中的应用。通过对比不同算子的效果,如Sobel梯度、Scharr算子和拉普拉斯算子,揭示了scharr算子在描述图像细节上的优势。文章提供了详细的代码实现,包括Sobel算子的dx、dy参数设置,以及如何使用cv2库进行边缘检测。


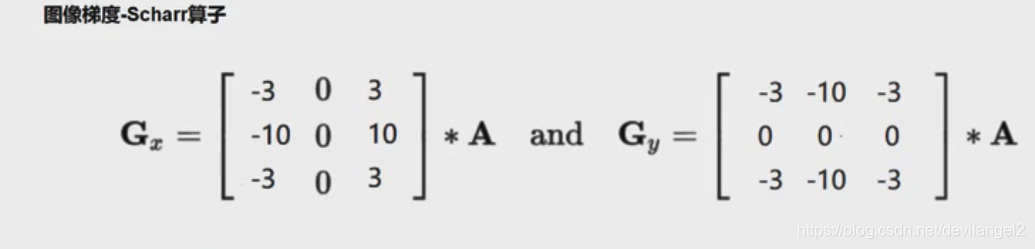


















 7
7

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









