




 本文深入解析了PyTorch中的scatter_和scatter_add函数,介绍了如何使用它们进行张量值的替换和累加。通过实例展示了如何在不同维度上操作,以及torch_scatter库的scatter方法,用于按指定分组进行计算。此外,还讨论了index的分组方法和reduce参数的不同效果。
本文深入解析了PyTorch中的scatter_和scatter_add函数,介绍了如何使用它们进行张量值的替换和累加。通过实例展示了如何在不同维度上操作,以及torch_scatter库的scatter方法,用于按指定分组进行计算。此外,还讨论了index的分组方法和reduce参数的不同效果。
一、 pytorch中的定义和实现原理
ouput = torch.scatter(input, dim, index, src)
# 或者是
input.scatter_(dim, index, src)
在torch._C._TensorBase.py中,定义了scatter_(self, dim, index, src, reduce=None) -> Tensor方法,作用是将src的值写入index指定的self相关位置中。用一个三维张量举例如下,将src在坐标(i,j,k)下的所有值,写入self的相应位置,而self的位置坐标除了dim维度用index[i,j,k]代替以外,都不变:
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0,用index[i][j][k]替换i坐标
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1,用index[i][j][k]替换j坐标
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2,用index[i][j][k]替换k坐标要求:
self,index,src必须有相同的维数;index在任意维度的size必须小于等于self和src对应维度的sizeself和index中元素的类型必须一致,dtype
>>> x = torch.rand(2, 5)
>>> x
tensor([[ 0.3992, 0.2908, 0.9044, 0.4850, 0.6004],
[ 0.5735, 0.9006, 0.6797, 0.4152, 0.1732]])
>>> torch.zeros(3, 5).scatter_(0, torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]]), x)
tensor([[ 0.3992, 0.9006, 0.6797, 0.4850, 0.6004],
[ 0.0000, 0.2908, 0.0000, 0.4152, 0.0000],
[ 0.5735, 0.0000, 0.9044, 0.0000, 0.1732]])
"""
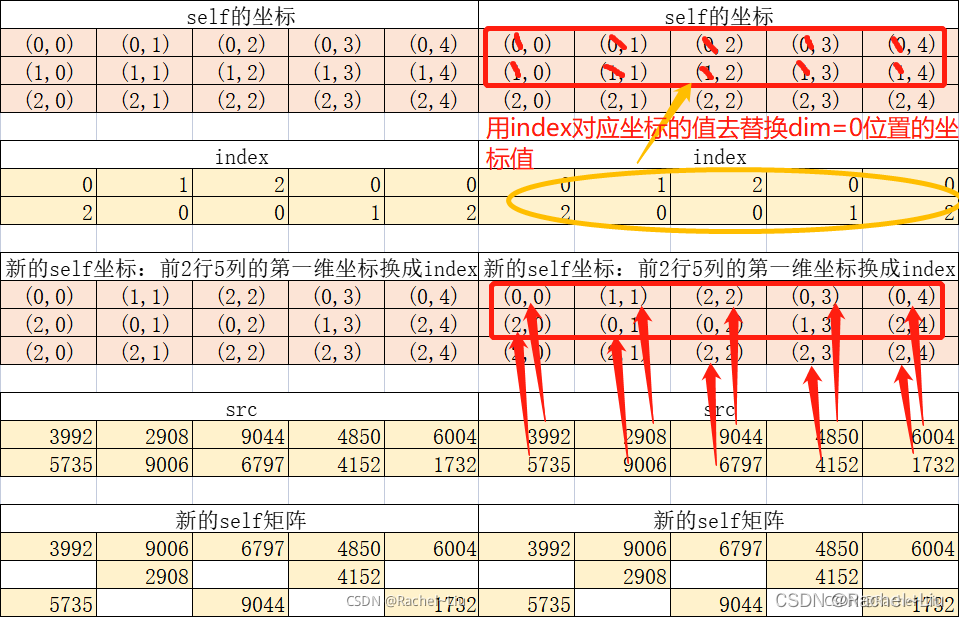
理解一下:
self是一个shape为(3,5)的全零tensor;
index是一个shape为(2,5)的tensor;
x同index的shape相同,不相同也可。
dim=0,意味着index需要修改第0维坐标;
原始坐标为:00,01,02,03,04;10,11,12,13,14
更新的横坐标依次为:01200;20012
更新的纵坐标依次为:01234;01234
对应组合,更新坐标为:00,11,22,03,04;20,01,02,13,24
然后用x在原始坐标下的值填写到self更新后的坐标位置,将原始坐标和更新坐标对应来看。
具体来看:
x new_self
00 00
01 11
02 22
03 03
04 04
10 20
11 01
12 02
13 10
14 24
"""
图示上述例子:
>>> z = torch.zeros(2, 4).scatter_(1, torch.tensor([[2], [3]]), 1.23)
>>> z
tensor([[ 0.0000, 0.0000, 1.2300, 0.0000],
[ 0.0000, 0.0000, 0.0000, 1.2300]])
"""
理解一下:一个2*1的index_tensor(一个2维张量,两个维度的size分别是2和1,对应两个值为2和3),dim=1,需要修改的就是1维。
原来的坐标是00,10;修改后的坐标是02,13。
然后用目标值1.23去替换self中坐标02,13的值,得到上述结果。
"""
>>> z = torch.ones(2, 4).scatter_(1, torch.tensor([[2], [3]]), 1.23, reduce='multiply')
>>> z
tensor([[1.0000, 1.0000, 1.2300, 1.0000],
[1.0000, 1.0000, 1.0000, 1.2300]])
"""
同上:用目标值找到self在更新坐标位置的值,乘以目标值1.23得到更新后的矩阵。
"""
类似于上述方法,在python中还包括scatter_add(dim, index, src) -> Tensor用于实现将src按照index位置累加到self上。
torch_scatter库
这个第三方库对矩阵的分组处理这个概念做了更进一步的封装,通过index来指定分组信息,将元素分组后进行对应处理,最基础的scatter方法形式如下:
torch_scatter.scatter(src, index, dim, out, dim_size, reduce)src: 数据源
index:分组序列
dim:分组遵循的维度
out:输出的tensor,可以不指定直接让函数输出
dim_size:out不指定的时候,将输出shape变为该值大小;dim_size也不指定,就根据计算结果来
reduce:分组的操作,包括sum,mul,mean,min和max操作
这个方法理解关键在index的分组方法,举个例子:
dim = 1
index = torch.tensor([[0, 1, 1]])
torch_scatter.scatter对index的顺序是没有特定规定的,相同数字对应的元素即为一组。比如例子中,维度1上的第0个元素为一组,第1和2元素为另一组。这样,按照分组进行reduce定义的计算即可获得输出。如:
t = torch.arange(12).view(4, 3)
print(t)
t_s = torch_scatter.scatter(t, torch.tensor([[0, 1, 1]]), dim=1, reduce='sum')
print(t_s)
输出:
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
tensor([[ 0, 3],
[ 3, 9],
[ 6, 15]])
可以看出,每行的后两个元素求了和,与index定义相同。
要注意的是,index的shape[0]为1时,会自动对dim对应的维度上每一层进行相同的分组处理,如上例所示,index大小为(1, 3),即对src的三行数据都进行了分组处理。
而另一种分组方式,如需要每行分组不同,则需要index的shape和src的shape相同,如下例:
t = torch.arange(12).view(4, 3)
print(t)
t_s = torch_scatter.scatter(t, torch.tensor([[0, 1, 1], [1, 1, 0], [0, 1, 1], [1, 1, 0]]), dim=1, reduce='sum')
print(t_s)
输出:
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
tensor([[ 0, 3],
[ 5, 7],
[ 6, 15]])


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









