



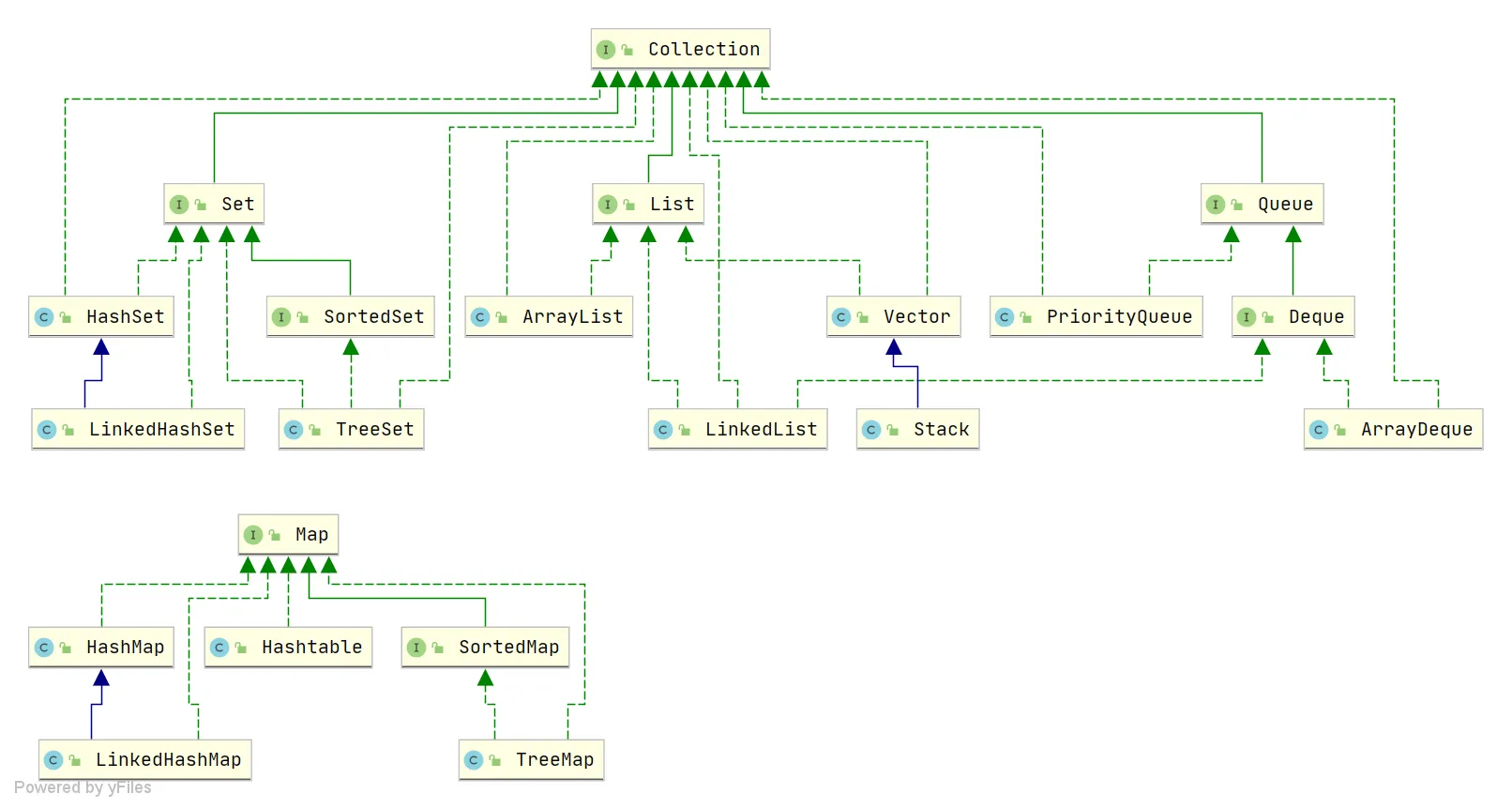
一、Java集合框架
1)讲讲Java集合的架构?
-
Collection 接口(存单一元素)
● List(有序,可重复)
○ ArrayList:底层动态数组,查询快,增删慢(尾部增删快)
○ LinkedList:底层双向链表,查询慢,增删快
● Set(无序,不可重复)
○ HashSet:底层HashMap(用 key 存),唯一性依赖hashCode + equals
○ TreeSet:底层 红黑树,元素有序(自然排序/自定义比较器)
● Queue(队列)
○ PriorityQueue:底层小顶堆,也可以作为优先级队列
○ Deque:底层双端队列 -
Map 接口(存键值对)
● HashMap:哈希表
● ConcurrentHashMap:线程安全实现
● TreeMap:底层红黑树
Java 集合框架图
2)如何选择集合?
● 需要键值对:选择 Map 接口下的集合
○ 需要排序:TreeMap
○ 不需要排序:HashMap
○ 需要线程安全:ConcurrentHashMap
● 不需要键值对:选择Collection接口下的集合
○ 需要保证元素唯一:选择 Set 接口下的集合
■ 需要排序:TreeSet
■ 不需要排序:HashSet
○ 不需要保证元素唯一:选择 List 接口下的集合
■ 查询块:ArrayList
■ 增删快:LinkedList
二、Collection
1)⭐讲讲ArrayList的底层实现?
- 底层数据结构
a. ArrayList内部维护一个Object动态数组,用于存储元素 - 动态扩容机制
a. 当向ArrayList底层数组已满时,ArrayList会自动创建一个原数组容量的 1.5 倍的新数组,将原数组中的所有元素复制到新数组中
b. 由于扩容操作会影响性能,因此在已知元素数量的情况下,建议在初始化时指定初始容量 - 线程安全性
a. ArrayList不是线程安全的。在多线程环境下,需要使用如Collections.synchronizedList()等方案进行处理 - 时间复杂度
a. 随机访问效率高:O(1)
b. 插入和删除,因为需要移动前后元素位置,效率低:O(n)
c. 适用场景:适用于需要频繁进行随机访问,而对插入和删除操作要求不高的场景
2)⭐⭐ArrayList和LinkedList的区别?
- 线程安全:
○ ArrayList和LinkedList都是非线程安全的,在多线程环境下使用需要额外的同步措施 - 底层数据结构:
○ ArrayList:底层使用数组实现。这意味着元素在内存中是连续存储的
○ LinkedList:底层使用双向链表实现。每个元素都包含指向前后元素的指针,元素在内存中不是连续存储的 - 时间复杂度:
○ ArrayList:数组支持随机访问,适合频繁访问元素的场景
○ LinkedList:查询慢,但在头尾增删快,适合头尾频繁插入和删除元素的场景 - 内存占用:
○ LinkedList每个元素需要额外的空间存储前后指针,因此空间开销大 - 技术选型:
○ 虽然LinkedList适合频繁的插入和删除操作,但仅限于头尾操作,在其他位置插入和删除元素的效率并不高
○ 在大多数情况下,ArrayList都可以替代LinkedList,并且性能更好
三、Map
1)⭐⭐讲讲HashMap的底层实现?
-
数据结构
● 数组:HashMap底层维护一个数组,数组元素被称为桶(bucket)
● 链表:解决哈希冲突
● 红黑树(以提高查找效率):当链表元素数量超过阈值(默认为 8),链表会转换为红黑树,小于树化阈值(默认为 6)时会转换回链表 -
工作流程
a. 计算哈希值:调用put()方法时,会先调用键的hashCode()方法计算键的哈希值
b. 确定数组索引:通过哈希值和数组长度取模,计算索引
c. 处理哈希冲突:链地址法、红黑树 -
扩容机制:数组初始容量为16,当HashMap的填充率达到阈值(默认为 75%)时,会进行扩容至原来的两倍(重新计算键值对的哈希值并分配到新的数组中,称为rehash)
-
细节
● 允许null:允许一个null 键和多个null值
● 非线程安全:在多线程环境下使用需要进行同步处理,或使用ConcurrentHashMap
2)⭐HashMap和ConcurrentHashMap的区别?
- 线程安全:ConcurrentHashMap是线程安全的
- 性能
○ HashMap在单线程环境中具有更高的性能,因为它没有同步的开销
○ ConcurrentHashMap在多线程环境中具有更高的并发性能,因为它通过细粒度锁减少了线程之间的竞争 - 迭代器
○ HashMap的迭代器是fail-fast的。如果在迭代过程中HashMap被修改,迭代器会抛出ConcurrentModificationException
○ ConcurrentHashMap的迭代器是fail-safe的,允许在迭代过程中修改ConcurrentHashMap - null值
○ HashMap允许一个null 键和任意数量的null值
○ ConcurrentHashMap不允许null键或null值
3)ConcurrentHashMap和Hashtable的区别?
- 线程安全机制
○ Hashtable:使用synchronized关键字对整个哈希表进行同步。这意味着在同一时刻,只能有一个线程可以访问 Hashtable
○ ConcurrentHashMap:采用分段锁(Segment Locking)机制,将整个哈希表分成多个段,每个段都有自己的锁。提高了并发性能 - 性能
○ Hashtable:由于使用全局锁,并发性能较低,在高并发场景下容易成为性能瓶颈
○ ConcurrentHashMap:由于采用分段锁或更细粒度的锁,并发性能较高,在高并发场景下表现更好 - null值:都不允许键或值为null,否则会抛出 NullPointerException
- 迭代器
○ Hashtable的迭代器是fail-fast的,如果在迭代过程中,哈希表被修改,会抛出ConcurrentModificationException
○ ConcurrentHashMap的迭代器是fail-safe的。它们不会抛出ConcurrentModificationException,并且允许在迭代过程中修改ConcurrentHashMap
4)⭐ConcurrentHashMap如何实现线程安全?
Java 7之前:
在Java 7中,ConcurrentHashMap 主要通过分段锁机制来实现线程安全
● 数据结构:ConcurrentHashMap 内部维护一个Segment数组,每个Segment 类似于一个小的HashMap
● Segment类:Segment类继承自ReentrantLock,这意味着每个Segment本身就是一个锁
● 加锁:多线程访问ConcurrentHashMap 时,会根据键的哈希值确定要访问的Segment,并尝试获取锁
Java 8及之后:
使用Node<k, v>数组替换了Segment数组,使用synchronized替换了ReentrantLock
● Node类:一个Node就是一个键值对,元素使用volatile+CAS+synchronized的机制保证并发安全
● synchronized:synchronized在Java 6之后经过优化,性能已经接近 ReentrantLock。
● CAS:可以避免使用锁,从而提高并发性能
● 红黑树:当哈希冲突严重时,ConcurrentHashMap会将哈希表的链表转换为红黑树,以提高查找效率

















 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









