




day36打卡
我们把它看成一个预定会议问题,选择越早结束的会议就给后面空出来的时间越长,所以我们按照右边界排序(也就是按结束时间排序)。
按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉区间的个数就是需要移除的区间个数了。
class Solution {
static bool cmp(vector<int>& a, vector<int>& b)
{
return a[1] < b[1];
}
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
//先按右边界排序
//sort(intervals.begin(), intervals.end(), [](const auto& a, const auto& b){
// return a[1] < b[1];
//})
sort(intervals.begin(), intervals.end(), cmp);
//开始记录不重叠区间个数
int count = 1;//把第一个当做不重叠区间
int end = intervals[0][1];//记录右边界最小的区间
for(int i = 1; i < intervals.size(); i++)
{
//比这个区间的右边界大,说明不重复
if(intervals[i][0] >= end)
{
end = intervals[i][1];
count++;
}
}
return intervals.size() - count;
}
};
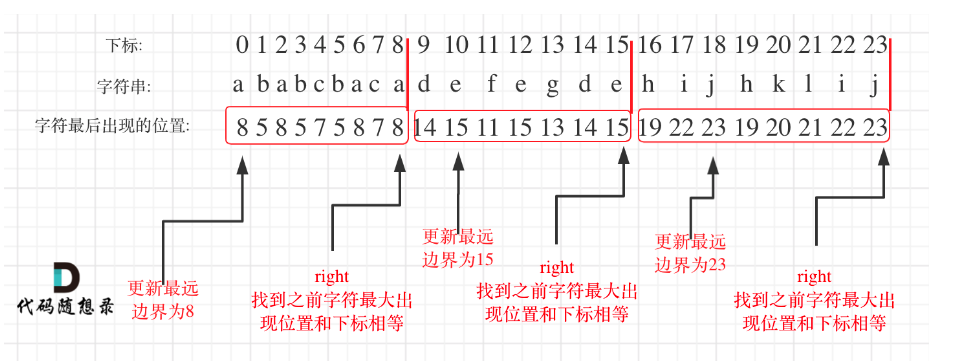
题目要求同一字母最多出现在一个片段中,那么如何把同一个字母的都圈在同一个区间里呢?
在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
分为两步:
- 统计所以字母出现的最后位置
- 遍历寻找之前遍历过的所有字母的最远边界,如果找到字母最远出现位置下标和当前下标相等了,则找到了分割点
class Solution {
public:
vector<int> partitionLabels(string s) {
// 统计每一个字符最后出现的位置
int hash[27] = {0};
for(int i = 0; i < s.size(); i++)
{
hash[s[i] - 'a'] = i;
}
// 遍历找到字母出现最后位置
int begin = 0, end = 0;
vector<int> ret;
for(int i = 0; i < s.size(); i++)
{
// 找到字符出现的最远边界
end = max(end, hash[s[i] - 'a']);
if(i == end)
{
ret.push_back(end - begin + 1);
begin = end + 1;
}
}
return ret;
}
};
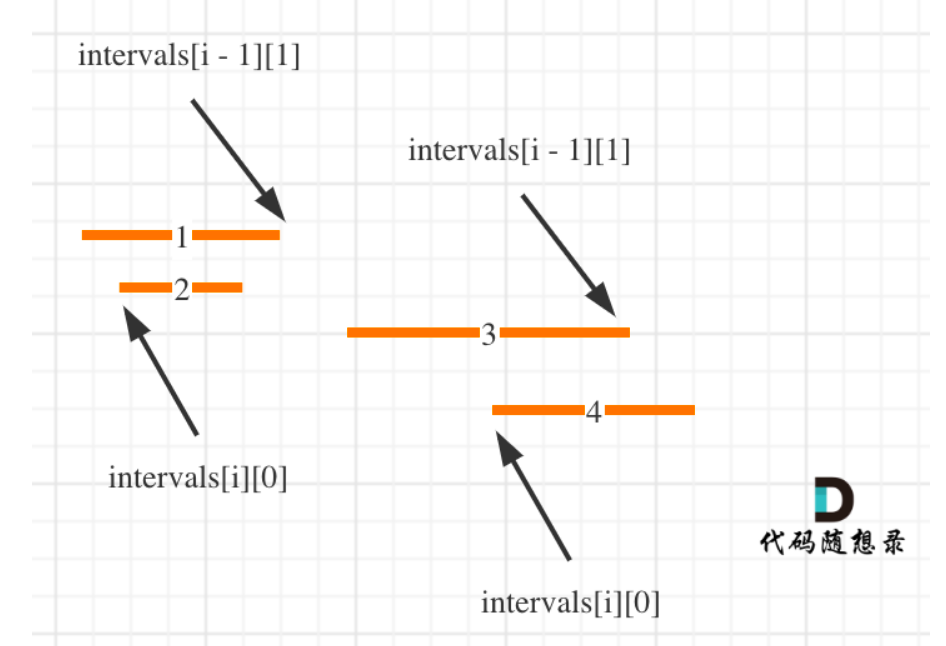
和无重叠区间几乎一模一样,仅仅是因为合并区间修改为左边界排序。
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
//按左边界排序
sort(intervals.begin(), intervals.end(), [](const auto& a, const auto& b){
return a[0] < b[0];
});
//寻找不重叠区间和合并区间
vector<vector<int>> ret;
ret.push_back(intervals[0]);
for(int i = 1; i < intervals.size(); i++)
{
//不重叠
if(intervals[i][0] > ret.back()[1])
{
ret.push_back(intervals[i]);
}
else//重叠,合并
{
ret.back()[1] = max(ret.back()[1], intervals[i][1]);
}
}
return ret;
}
};

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









