




day29打卡
使用uset记录本层元素是否使用即可。
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
vector<vector<int>> findSubsequences(vector<int>& nums) {
//不能排序,排序后就全是非递减序列了
// sort(nums.begin(), nums.end());
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos)
{
if(path.size() > 1) ret.push_back(path);
//用来本层去重
unordered_set<int> uset;
for(int i = pos; i < nums.size(); i++)
{
if((!path.empty() && nums[i] < path.back())
|| uset.find(nums[i]) != uset.end())
continue;
uset.insert(nums[i]);
path.push_back(nums[i]);
dfs(nums, i+1);
path.pop_back();
}
}
};
思路:画出决策树:
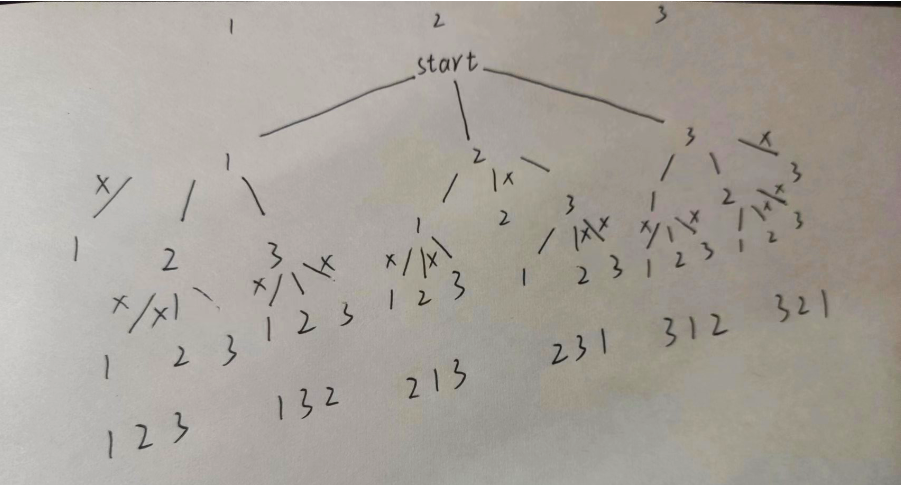
使用全局变量:ret记录返回值,check记录有无使用过这个数字(剪枝),path记录递归结果。
函数头:void dfs(vector< int >& nums)
函数体:
出口:path.size() == nums.size(),保存递归结果到ret,并向上一层返回
子问题:遍历每个数,进行push_back记录结果。
回溯:每次出递归函数时,把check[i]变为false,把path中结果pop_back。
class Solution {
public:
vector<vector<int>> ret;
vector<int> path;
bool check[7] = {false};
vector<vector<int>> permute(vector<int>& nums) {
dfs(nums);
return ret;
}
void dfs(vector<int>& nums)
{
if(path.size() == nums.size())
{
ret.push_back(path);
return;
}
for(int i = 0; i < nums.size(); i++)
{
if(check[i] == false)
{
path.push_back(nums[i]);
check[i] = true;
dfs(nums);
check[i] = false;
path.pop_back();
}
}
}
};
决策树:
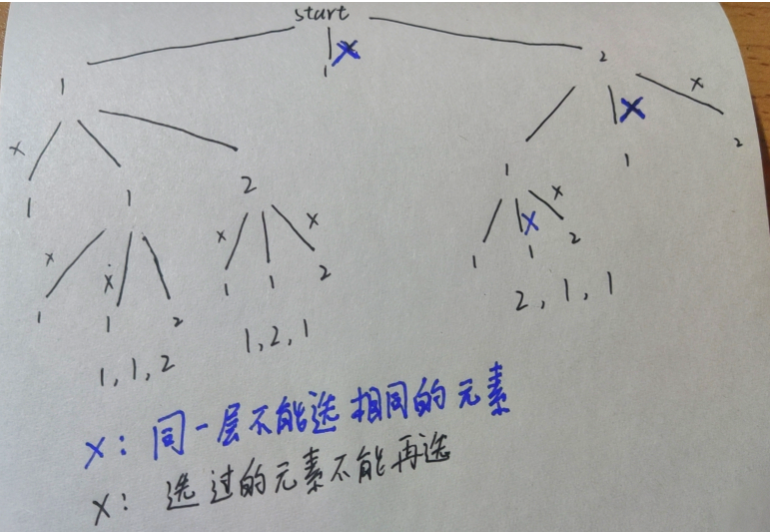
思路:完成全排列时,同时对重复情况剪枝即可。
函数头:void dfs(vector< int >& nums, int pos)
函数体:
出口:nums.size() == pos : 保存结果,返回
子问题:
在nums中选出元素,进行组合。
回溯:出递归函数后,path.pop_back()即可
剪枝:
解法1:只关心”合法“情况 :进入选择
当前元素没有被使用 && (第一次进行选择 || 这个元素和前一个元素不相等 || 如果元素相同,这个元素的前一个元素被使用过了)
如果元素相同,这个元素的前一个元素被使用过了:在不同一层,选的同一个元素
解法2:只关心“不合法”情况:跳过本次选择
当前元素被使用过了 || (不是第一次进行选择 && 这个元素和前一个元素相等 && 这个元素没有被使用过)
这个元素和前一个元素相等:在同一层,选择同一个元素
两种解法都需要数组有序,所以先进行排序。
class Solution {
vector<vector<int>> ret;
vector<int> path;
bool check[9] = {false};
int hash[9];
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
// for(auto e : nums) hash[e] = 1;
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos)
{
//出口
if(nums.size() == pos)
{
ret.push_back(path);
return;
}
//子问题:
//遍历每个元素,选择
for(int i = 0; i < nums.size(); i++)
{
//只关心不合法的情况
if(check[i] == true || (i > 0 && nums[i] == nums[i-1] && check[i-1] == false))
continue;
//只关心合法的情况
// if(check[i] == false && (i == 0 || nums[i] != nums[i-1] || check[i-1] == true))
if(check[i] == false)
{
path.push_back(nums[i]);
// hash[nums[i]] = 0;
check[i] = true;
dfs(nums, pos+1);
//回溯
check[i] = false;
// hash[nums[i]] = 1;
path.pop_back();
}
}
}
};
//回溯
check[i] = false;
// hash[nums[i]] = 1;
path.pop_back();
}
}
}
};

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









